Как правильно сделать столбчатый фундамент своими руками: Столбчатый фундамент своими руками: пошаговая инструкция
Как сделать столбчатый фундамент своими руками
В наше время стало довольно популярным использование столбчатого фундамента в строительстве.
Наибольшую популярность этот вид конструкции получил в строительстве небольших построек на дачном участке. Прежде всего, благодаря его низкой стоимости и простоте возведения.
Наиболее подходяще применение данному типу фундаментов — это небольшие строения малой массы. Он может служить хорошей основой для сооружений из бруса и новомодных так называемых “канадских” домов, которые возводятся по каркасно-щитовой технологии.
Но в целом, он может подойти и для зданий из:
- кирпича;
- камня;
- железобетона, при условии, что стены будут не слишком толстые.
Так или иначе, для постройки более серьезных сооружений, стоит все же использовать другие типы фундаментов.
Столбчатый же фундамент используют прежде всего для снижения затрат на стройматериалы, в случаях когда его прочности и грузоподъемности достаточно для планируемого строения.
Как сделать столбчатый фундамент своими руками
Теперь поговорим немного о самом процессе возведения подобного типа фундамента, который можно разделить на несколько этапов.
В первую очередь, необходимо вырыть ямы для будущего основания. Нам нужна не одна большая, а множество небольших, которые легко делаются своими руками с помощью обычного бура и значительно экономят время, и финансы.
Расчет глубины и ширины этих отверстий производят исходя из планируемой массы сооружения. Расстояние между ними обычно 1,5-2 метра, которые рассчитываются в зависимости от нескольких факторов. Стоит учесть, что они (опоры) должны быть в местах соприкосновения и соединения стен, а также там, где планируется установка внутренних перегородок.
Если есть возможность желательно использовать специальные буры, которые создают небольшое пространство под ямой, которая заполняется впоследствии и увеличивает площадь опоры, и соответственно надежность конструкции.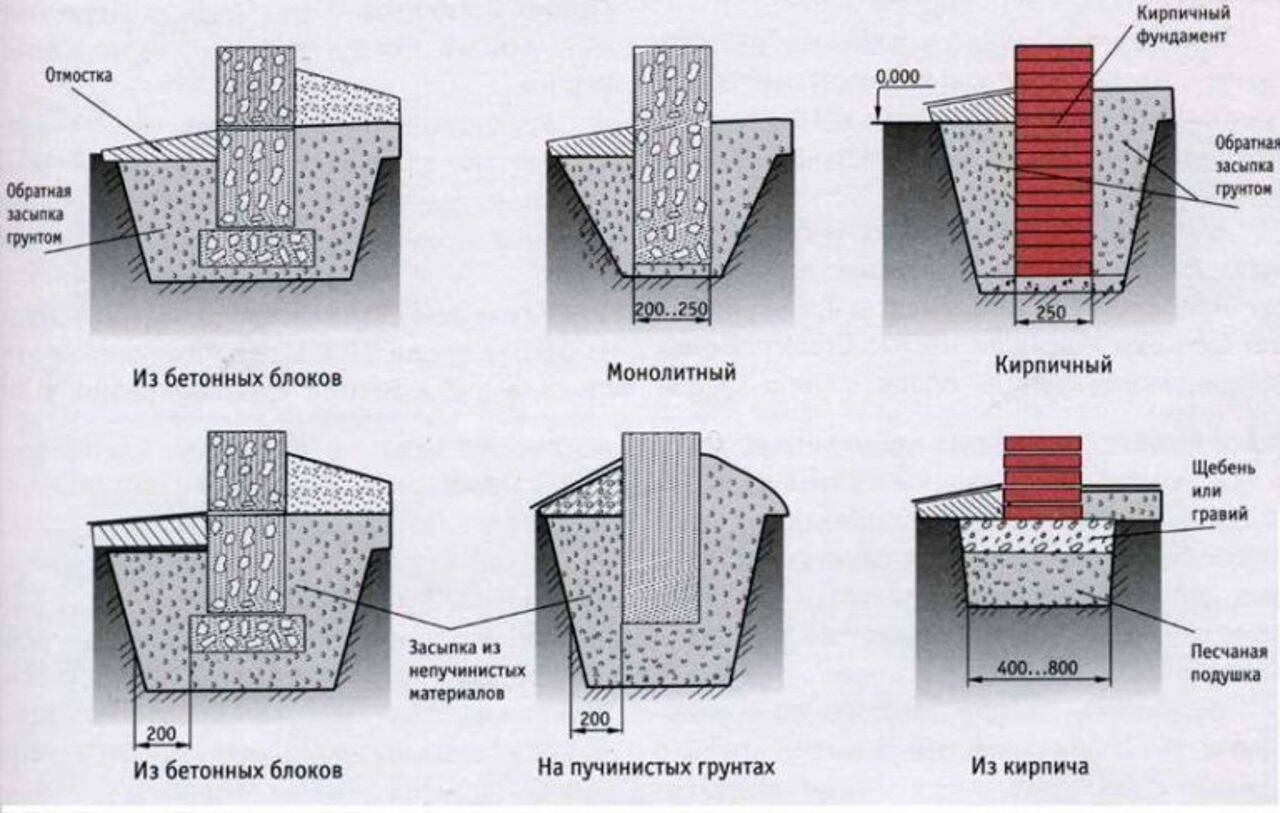
Если говорить о материалах, которые будут использоваться при возведении столбчатого фундамента своими руками, то они как и в случае с ленточным основанием – цемент, песок и вода. Понадобиться ещё наполнитель, в виде:
- щебня;
- гравия;
- бутового камня;
- гранитного отсева.
При возведении столба применяют трубы из асбеста или более экономичный вариант – деревянную опалубку.
- Я в своё время использовал железный питьевой бак на 40 литров, вырезал дно и разрезал его для более удобного снятия с застывшего столба.
- Когда устанавливал бачок на шурф, то предварительно связывал его проволокой, а на место разреза ложил целлофан, чтобы не было утечки бетона.
- У вас сейчас выбор богаче, можно применить подходящий по размеру пластиковый сосуд или небольшую бочку.
Глубину установки столбов рассчитывают с учетом климата в конкретной местности, а именно, на сколько глубоко в зимнее время может промерзать земля.
Лучше всего наполнять шурфы сразу бетоном, но в ряде случаев можно сначала заполнить их щебнем и бутовым камнем, а затем залить раствором.
Приготовить бетонную смесь и залить её в готовую скважину действие не сложное. Здесь следует учитывать, что соотношение гравия, песка и цемента 5:3:1 – то есть, на 50 кг гравия нужно 30 кг песка и 10 кг цемента.
Сам бетон хорошо замешивать в бетономешалке, но можно и в железной ванне или в деревянном ящике:
- Сначала нужно всыпать сухие компоненты – песок, гравий, цемент и хорошо их перемешать до однородной массы.
- А потом только можно доливать воду и при этом перемешивая бетонную смесь. На вид масса должна быть вся увлажнена.
- Если делаете в первый раз, то попробуйте на малом объёме материала, как набьёте руку, то полный вперёд.
Также рекомендуется укрепление столбов с помощью арматуры. Но можно и обойтись без этого, просто стоит добавить больше цемента в бетон.
Но можно и обойтись без этого, просто стоит добавить больше цемента в бетон.
Видео: как правильно залить столбчатый фундамент своими руками.
Видео: свайный фундамент с ростверком.
Вот такими простыми способами, описанными в статье и делается столбчатый фундамент своими руками. Ничего сложного в этом нет, смело беритесь за дело!
Как правильно сделать столбчатый фундамент под дом своими руками: пошаговая инструкция, видео
Не всегда имеется необходимость в сооружении крепкого, основательного и дорогого основания, в таких ситуациях нужно знать
Содержание:
- За и против столбчатого фундамента
- Разделение на подвиды
- Собираем данные и проводим расчеты
- Структура: составные элементы и их назначение
- Процесс создания столбчатого фундамента
- Как правильно сделать столбчатый фундамент под дом своими руками: видео
Такая конструкция применима только для легких сооружений. Предельный показатель веса находится на уровне 1000 кг/м3.
Предельный показатель веса находится на уровне 1000 кг/м3.
За и против столбчатого фундамента
Каждая разновидность основы имеет ряд преимуществ и отрицательных моментов. Чтобы понять насколько в вашем случае подходит изготовление столбчатого фундамента своими руками, необходимо изучить все эти моменты и сделать соответствующие выводы.
Список положительных моментов выглядит следующим образом:
- доступная стоимость, которая сохраняется даже при большой углубленности;
- сохранение стойкости и эксплуатационных характеристик при пучении грунта;
- отсутствие необходимости в привлечении дорогой, мощной и габаритной техники;
- простое проектирование;
- возможность расположения на местности с большими перепадами высоты без выполнения работ по выравниванию грунта;
- быстрое возведение;
- гидроизоляция не требует вложения больших средств и использования большого количества материалов;
- высокая надежность и долговечность.


Список отрицательных моментов выглядит следующим образом:
- потеря устойчивости во время движения грунта и влияния большой боковой нагрузки;
- несовместимость с болотистой местностью и грунтом, склонным к движению.
Когда все факторы хорошо изучены и на их основе сделаны соответствующие выводы, можно переходить к следующему этапу. Если фундамент на столбах своими руками построить невозможно, нужно изучить другие основы, описание каждой из которых имеется на нашем ресурсе. Если фундамент на столбиках своими руками может быть возведен, то можно продвигаться дальше.
Разделение на подвиды
Пока мы не будем рассказывать о том, как сделать столбчатый фундамент. К этому вопросу мы вернемся чуть позже, пока не решим еще один важный момент, связанный с выбором типа ленточного фундамента. Если сделать неправильный выбор, то основа не будет долговечной, что приведет к разрушению всей постройки.
Главное разделение основано на глубине заложения фундамента. Для определения уровня, который в вашем случае будет оптимальным, необходимо учитывать особенности будущей постройки (тип, вес, этажность), геологические характеристики участка и грунта. По глубине заложения выделяют следующие разновидности:
Для определения уровня, который в вашем случае будет оптимальным, необходимо учитывать особенности будущей постройки (тип, вес, этажность), геологические характеристики участка и грунта. По глубине заложения выделяют следующие разновидности:
- Заглублённый должен располагаться ниже отметки, на которой находится уровень промерзания почвы. Разница составляет 20 см.
- Мелкозаглублённый погружается в землю на 40, а то и на все 70 см. Такая основа применима в теплых регионах без большого количества осадков. Нагрузка должна быть небольшой, поэтому позволительно на таком фундаменте возводить лишь каркасные сооружения.
- Незаглублённый располагается просто на грунте. Подготовительные работы заключаются в снятии верхнего, плодородного слоя грунта, который необходимо заменить на материал нерудного типа.
Кроме такого разделения существует классификация столбчатого фундамента по материалу, из которого возводились его опоры. А материалы могут использоваться самые разные:
- готовые железобетонные опоры, которые максимально упрощают процесс строительства;
- бут и бетон позволяют добиться высокой прочности при минимальных вложениях;
- кирпич усложняет работу, зато выглядит такой фундамент презентабельно и долго сохраняет свои функциональные характеристики;
- дерево требует тщательной обработки;
- трубы из различного материала.

Мы еще на шаг приблизились к тому, чтобы узнать как сделать столбчатый фундамент своими руками. Чтобы в дальнейшем не возникало вопросов и все термины были понятными, необходимо рассмотреть структуру ленточного основания.
Собираем данные и проводим расчеты
Нас интересует как правильно сделать столбчатый фундамент, чтобы он получится прочным, надежным и смог отслужить выше положенного срока. Для этого необходимо собрать некоторые данные относительно местности и будущего строения. На основании этого информации можно проводить расчеты.
- тип грунта;
- глубина промерзания почвы может быть выяснена у строителей или по специальным таблицам;
- степень заглубления фундамента определяется типом грунта, погодными условиями и весом строения;
- определение оптимального материала, который будет использоваться для создания столбов;
- определение расстояния, на котором будут располагаться столбы;
- вес здания.

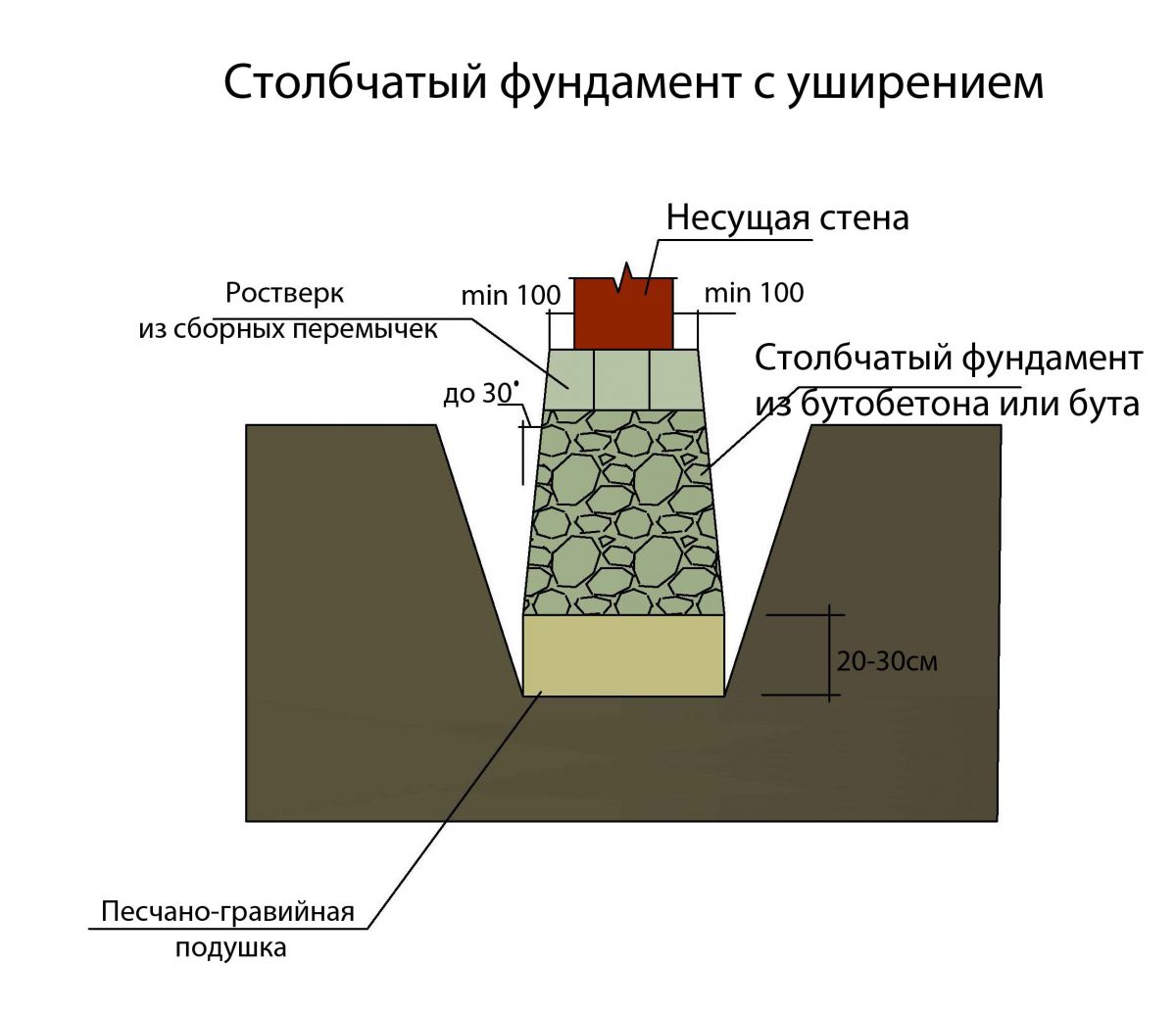
Структура: составные элементы и их назначение
Столбчатый фундамент под дом своими руками мы сможем сделать только в том случае, если будем знать о его структуре.
- Ж/б плита, подушка из песка и щебня — эти элементы необходимы для распределения нагрузки. Если халатно отнестись к организации этих слоев, то грунт может просесть в некоторых местах. Подушка создается по принципу расклинцовки, суть которого заключается в уменьшении фракции материала при укладывании каждого следующего слоя. Если фундамент для дома своими руками столбчатый создается на твердом грунте, столб может располагаться на щебне.
- Столб может состоять из различных материалов, о которых выше уже говорилось. Часто строители-аматоры отдают предпочтение кирпичной кладке, железобетону и шлакоблоку. Как сделать столбы под фундамент мы обязательно расскажем, но немного позже.
- Ростверк может быть металлическим, бетонным или деревянным. Этот элемент представлен в виде несущей жесткой балки, которая монтируется на столбы. Ее назначение заключается в поддерживании стен, которые располагаются между столбами. Монтаж ростверка необходим при расположении столбов на расстоянии более полутора метра друг от друга.
 Ее назначение заключается в поддерживании стен, которые располагаются между столбами. Монтаж ростверка необходим при расположении столбов на расстоянии более полутора метра друг от друга.
Ее назначение заключается в поддерживании стен, которые располагаются между столбами. Монтаж ростверка необходим при расположении столбов на расстоянии более полутора метра друг от друга.Вот и все устройство столбчатого фундамента, своими руками будем учиться его возводить дальше.
Процесс создания столбчатого фундамента
Когда все подготовительные моменты решены, можно переходить к практической стороне вопроса. Мы рассмотрим общий процесс создания столбчатого фундамента. Все другие разновидности столбчатых основ создаются по единой схеме, просто можно пропустить лишние этапы. Как делать столбчатый фундамент смотрите ниже. Весь рабочий процесс мы разделили на этапы, что упрощает изучение материала.
Подготовительные работы на участке
Убираем слой плодородной земли, который заменяем на песок с гравием. Слой земли снимается вместе с растительностью и корнями. В случае присутствия глины в грунте организовываем подсыпку из песка и гравия. Ямы засыпаем грунтом и убираем неровности, чтобы позволит легко выполнить разметку. Для этого удобно использовать колышки и натянутые веревки. Размечаем место для расположения каждого столба. Расстояние между ними может находиться в пределах полутора — двух метров. Это только первый этап, так что продолжаем сооружать столбчатый фундамент своими руками, пошаговая инструкция изложена дальше.
Для этого удобно использовать колышки и натянутые веревки. Размечаем место для расположения каждого столба. Расстояние между ними может находиться в пределах полутора — двух метров. Это только первый этап, так что продолжаем сооружать столбчатый фундамент своими руками, пошаговая инструкция изложена дальше.
Организация ям для столбов
Ямы можно делать самостоятельно, что является длительной и затруднительной работой. Привлечение строительной техники существенно облегчает этот процесс, но удорожает строительство. Как делать столбчатый фундамент под дом в этом случае решать только вам.
Располагать ямы необходимо по осям. При глубине ямы менее метра стенки в укреплении не нуждаются. В противном случае процесс выкапывания будет сопровождаться обустройством откосов и креплений с распорками. Глубина ямы должна превышать уровень залегания основы на 30 см. Это расстояние займет подушка из песка и гравия. Ширина ямы также должна быть больше планируемой. В этом случае монтаж опалубки и распорок будет проходить без сложностей.
Монтаж арматуры
Чтобы столбы под фундамент своими рукам получились крепкими и надежными, их необходимо армировать. Необходимо выбирать стержни А3 с диаметром не менее 12 мм. Располагаются железные прутки в продольном направлении. Между горизонтальными перемычками должно оставаться 20 см. Мы говорили ранее о необходимости монтажа ростверка. Он должен быть связан с арматурным каркасом. Чтобы в будущем можно было легко справиться с этой работой, необходимо стержни оставить над фундаментом. 15 см хватит вполне. Заметьте, мы правильно делаем столбчатый фундамент своими руками, поэтому отклоняться от нашей инструкции не стоит.
Столбы
Как уже говорилось, столбы могут создаваться из различных материалов. Чтобы рассказать как сделать столбики под фундамент, мы решили рассмотреть наиболее распространенный и легкий, но оттого не менее надежный. В ямы вставляются полые трубы, в которые заливается бетон. Эти трубы будут стоять на своем месте, служа дополнительной защитой для столбов.
Заливка бетона должна осуществляться послойно, не более 30 см каждый слой. Для этого процесса хорошо подходят вибраторы, которые позволяют убрать из бетона воздух и утрамбовать его.
Гидроизоляция
Мало знать как самому сделать столбчатый фундамент, нужно еще помнить о необходимости проведения гидроизоляции. Суть этого процесса заключается в защите фундамента о губительного влияния влаги. Есть много защитных средств, которые отличаются способом использования, стоимостью и длительностью действия.
Ростверк
Если расстояние между столбами в вашем фундаменте не превышает полтора метра, то этот этап можно пропускать и смело переходить к следующему. В противном случае придется соорудить такой элемент, чтобы повысить прочность основы и убрать нагрузку под стенами. Ведь нас интересует как правильно сделать столбчатый фундамент своими руками, поэтому будем соблюдать все рекомендации.
Есть два варианта для создания ростверка:
- Монолитный пояс требует сооружения опалубки, установки арматуры и заливания бетона. Дождавшись застывания демонтируем опалубку и проводим гидроизолирование.
- Сборный пояс требует тщательного соединения перемычек при помощи арматуры и сварки монтажных петель. Дальше следует монтаж опалубки, каркаса из арматуры и заливка бетона.
 Дождавшись застывания демонтируем опалубку и проводим гидроизолирование.
Дождавшись застывания демонтируем опалубку и проводим гидроизолирование.Теперь вы почти знаете как самому сделать столбчатый фундамент своими руками, согласитесь невыполнимого в этой работе ничего нет.
Завершающие работы
Пазухи ям необходимо заполнить грунтом. Также необходимо установить плиты перекрытия. Подпольное пространство без соответствующей защиты будет страдать от холода и осадков. Чтобы исправить эту ситуацию, необходимо пространство между столбами закрыть стенкой. Это может быть кирпичная кладка или любой другой, удобный для вас способ. В стенке или забирке, как ее называют, необходимо соорудить отверстия, через которые будут выводиться коммуникации.
Мы рассказали как правильно делать столбчатый фундамент. Теперь вы готовы приступать к этой ответственной работе.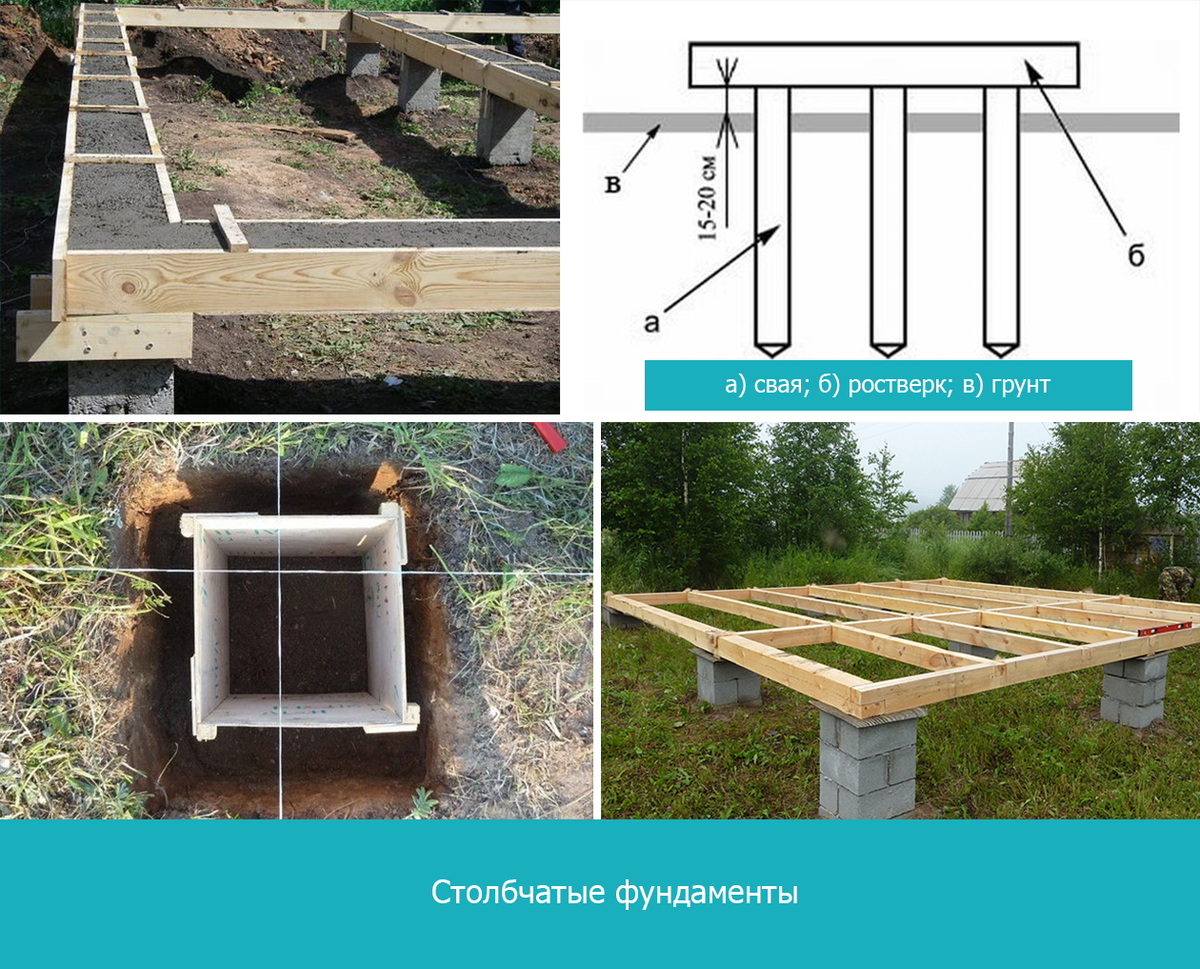 Мы верим в вас.
Мы верим в вас.
Как правильно сделать столбчатый фундамент под дом своими руками: видео
Другие материалы в этой категории: « Утепление цоколя фундамента снаружи и внутри своими руками: как утеплить пошаговая инструкция, видео Как сделать фундамент для дачи своими руками: пошаговая инструкция, видео »
лучших столбцовых баз данных для некоммерческих организаций — 2023 обзоры и сравнение
Что такое некоммерческие столбцовые базы данных?
Столбчатые базы данных, также известные как базы данных, ориентированные на столбцы, или базы данных с хранилищем столбцов, представляют собой тип баз данных, в которых данные хранятся в столбцах, а не в строках. Столбчатые базы данных имеют некоторые преимущества по сравнению с традиционными строковыми базами данных, включая скорость и эффективность. Сравните лучшие столбцовые базы данных для некоммерческих организаций, доступные в настоящее время, используя приведенную ниже таблицу.
Сравните лучшие столбцовые базы данных для некоммерческих организаций, доступные в настоящее время, используя приведенную ниже таблицу.
- 1
Садас Двигатель
Садас
Sadas Engine — это самая быстрая система управления столбцовыми базами данных как в облаке, так и локально. Превратите данные в информацию с помощью самой быстрой системы управления базами данных со столбцами, способной работать в 100 раз быстрее, чем транзакционные СУБД, и способной выполнять поиск в огромном количестве данных за период, превышающий 10 лет. Каждый день мы работаем над тем, чтобы обеспечить безупречный сервис и соответствующие решения для улучшения деятельности вашего конкретного бизнеса. SADAS srl, компания AS Group, занимается разработкой решений для бизнес-аналитики, приложений для анализа данных и инструментов DWH, опираясь на передовые технологии.
Компания работает во многих секторах: банковском, страховом, лизинговом, коммерческом, медиа и телекоммуникационном, а также в государственном секторе. Инновационные программные решения для повседневного управления и процессов принятия решений в любой отрасли - 2
Снежинка
Снежинка Инк.
Ваша облачная платформа данных. Безопасный и простой доступ к любым данным с бесконечной масштабируемостью. Получите всю информацию обо всех ваших данных от всех ваших пользователей с мгновенной или почти бесконечной производительностью, параллелизмом и масштабированием, которые требуются вашей организации. Беспрепятственно делитесь и используйте общие данные для совместной работы в вашей организации и за ее пределами, чтобы решать самые сложные бизнес-задачи в режиме реального времени. Повысьте производительность своих специалистов по данным и сократите время окупаемости, чтобы быстро предоставлять современные и интегрированные решения для данных из любой точки вашей организации.
Независимо от того, переносите ли вы данные в Snowflake или извлекаете информацию из Snowflake, наши технологические партнеры и системные интеграторы помогут вам развернуть Snowflake для достижения успеха. - 3
Апач Кассандра
Фонд программного обеспечения Apache
База данных Apache Cassandra — правильный выбор, когда вам нужна масштабируемость и высокая доступность без ущерба для производительности. Линейная масштабируемость и проверенная отказоустойчивость стандартного оборудования или облачной инфраструктуры делают его идеальной платформой для критически важных данных. Поддержка Cassandra для репликации между несколькими центрами обработки данных является лучшей в своем классе, обеспечивая более низкую задержку для ваших пользователей и уверенность в том, что вы можете пережить региональные сбои.
- 5
Роксет
Роксет
Анализ необработанных данных в реальном времени. Прямая загрузка из S3, Kafka, DynamoDB и других источников. Исследуйте необработанные данные в виде таблиц SQL. Создавайте потрясающие приложения на основе данных и интерактивные информационные панели за считанные минуты. Rockset — это бессерверная поисковая и аналитическая система, которая обеспечивает работу приложений в реальном времени и интерактивных информационных панелей. Работайте непосредственно с необработанными данными, включая JSON, XML, CSV, Parquet, XLSX или PDF. Подключайте данные из потоков реального времени, озер данных, баз данных и хранилищ данных в Rockset. Принимайте данные в режиме реального времени без создания конвейеров. Rockset постоянно синхронизирует новые данные по мере их поступления в ваши источники данных без необходимости использования фиксированной схемы.
Используйте знакомый SQL, включая соединения, фильтры и агрегации. Это невероятно быстро, поскольку Rockset автоматически индексирует все поля ваших данных. Обрабатывайте быстрые запросы, которые обеспечивают работу приложений, микросервисов, интерактивных информационных панелей и блокнотов по обработке и анализу данных, которые вы создаете. Масштабируйте, не беспокоясь о серверах, сегментах или пейджерах. - 6
Амазонка Красное смещение
Амазонка
Больше клиентов выбирают Amazon Redshift, чем любое другое облачное хранилище данных. Redshift поддерживает аналитические рабочие нагрузки для компаний из списка Fortune 500, стартапов и всего, что между ними. Такие компании, как Lyft, вместе с Redshift выросли из стартапов в многомиллиардные предприятия. Никакое другое хранилище данных не позволяет так легко извлекать новые идеи из всех ваших данных. С помощью Redshift вы можете запрашивать петабайты структурированных и полуструктурированных данных в своем хранилище данных, рабочей базе данных и озере данных, используя стандартный SQL.
Redshift позволяет легко сохранять результаты ваших запросов обратно в озеро данных S3, используя открытые форматы, такие как Apache Parquet, для дальнейшего анализа с помощью других аналитических сервисов, таких как Amazon EMR, Amazon Athena и Amazon SageMaker. Redshift — это самое быстрое облачное хранилище данных в мире, которое с каждым годом становится все быстрее. Для рабочих нагрузок, требующих высокой производительности, вы можете использовать новые инстансы RA3, чтобы повысить производительность до трех раз по сравнению с любым облачным хранилищем данных. - 7
Керона
Вам это нужно
Мы делаем аналитику BI и больших данных проще и быстрее. Наша цель — расширить возможности бизнес-пользователей и сделать так, чтобы вечно занятые бизнес-специалисты и высоконагруженные специалисты по бизнес-аналитике были менее зависимы друг от друга при решении бизнес-задач, связанных с данными.
Если вы когда-либо сталкивались с нехваткой необходимых вам данных, временем на создание отчетов или длинной очередью к вашему эксперту по бизнес-аналитике, подумайте о Querona. Querona использует встроенный механизм больших данных для обработки растущих объемов данных. Повторяющиеся запросы могут кэшироваться или рассчитываться заранее. Оптимизация требует меньше усилий, поскольку Querona автоматически предлагает улучшения запросов. Querona расширяет возможности бизнес-аналитиков и специалистов по данным, предоставляя им возможности самообслуживания. Они могут легко обнаруживать и прототипировать модели данных, добавлять новые источники данных, экспериментировать с оптимизацией запросов и копаться в необработанных данных. Требуется меньше ИТ. Теперь пользователи могут получать оперативные данные независимо от того, где они хранятся. Если базы данных слишком заняты, чтобы к ним можно было обращаться в режиме реального времени, Querona кэширует данные. - 9
Вертика
Микро Фокус
Единое хранилище аналитики. Высокоэффективная аналитика и машинное обучение в экстремальных масштабах. Поскольку критерии для хранения данных продолжают развиваться, аналитики технических исследований видят новых лидеров в стремлении к революционной аналитике больших данных. Vertica поддерживает предприятия, работающие с данными, чтобы они могли получить максимальную отдачу от своих инициатив в области аналитики с помощью расширенной аналитики временных рядов и геопространственной аналитики, машинного обучения в базе данных, интеграции с озером данных, определяемых пользователем расширений, оптимизированной для облака архитектуры и многого другого.
Наша серия веб-трансляций «Под капотом» позволит вам подробно изучить функции Vertica, предоставленные инженерами и техническими экспертами Vertica, и узнать, что делает эту базу данных самой быстрой и масштабируемой передовой аналитической базой данных на рынке. От приложений для совместного использования и интеллектуального сельского хозяйства до профилактического обслуживания и клиентской аналитики — Vertica поддерживает ведущих мировых революционеров, использующих данные, в их стремлении к трансформации отрасли и бизнеса. - 10
BigQuery
Google
Анализируйте петабайты данных с помощью ANSI SQL с молниеносной скоростью и нулевыми операционными издержками. Выполняйте аналитику в любом масштабе с трехлетней совокупной стоимостью владения на 26–34 % ниже, чем у альтернативных облачных хранилищ данных. Демократизируйте идеи с помощью надежной и более безопасной платформы, масштабируемой в соответствии с вашими потребностями.
Извлекайте ценные сведения из данных, хранящихся в облаках, с помощью гибкого многооблачного аналитического решения. Запрашивайте потоковые данные в режиме реального времени и получайте актуальную информацию обо всех ваших бизнес-процессах. Легко прогнозируйте результаты бизнеса с помощью встроенного машинного обучения и без необходимости перемещения данных. Безопасный доступ и обмен аналитическими данными в вашей организации с помощью нескольких щелчков мыши. С легкостью создавайте потрясающие отчеты и информационные панели, используя популярные инструменты бизнес-аналитики, готовые к использованию. Положитесь на надежные средства управления безопасностью, управлением и надежностью BigQuery, которые обеспечивают высокую доступность и 9SLA 9,99% времени безотказной работы. Защитите свои данные с помощью шифрования по умолчанию и ключей шифрования, управляемых клиентом. - 11
Большая таблица Google Cloud
Google
Google Cloud Bigtable — это полностью управляемая масштабируемая служба базы данных NoSQL для больших аналитических и операционных рабочих нагрузок.
Быстрота и производительность. Используйте Cloud Bigtable в качестве механизма хранения, который растет вместе с вами от первого гигабайта до петабайта для приложений с малой задержкой, а также для высокопроизводительной обработки данных и аналитики.
Плавное масштабирование и репликация: начните с одного узла на кластер и плавно масштабируйте до сотен узлов, динамически поддерживающих пиковую нагрузку. Репликация также обеспечивает высокую доступность и изоляцию рабочей нагрузки для приложений, работающих в режиме реального времени.
Простой и интегрированный: полностью управляемый сервис, который легко интегрируется с такими инструментами для работы с большими данными, как Hadoop, Dataflow и Dataproc. Кроме того, поддержка стандарта HBase API с открытым исходным кодом упрощает начало работы для групп разработчиков. - 12
Зеленая слива
База данных Гринплам
Greenplum Database® — это передовое полнофункциональное хранилище данных с открытым исходным кодом.
Он обеспечивает мощную и быструю аналитику объемов данных в петабайтах. База данных Greenplum, специально ориентированная на аналитику больших данных, оснащена самым передовым в мире оптимизатором запросов на основе затрат, обеспечивающим высокую производительность аналитических запросов для больших объемов данных. Проект Greenplum Database® выпущен под лицензией Apache 2. Мы хотим поблагодарить всех наших нынешних участников сообщества и заинтересованы во всех новых потенциальных вкладах. Для сообщества базы данных Greenplum ни один вклад не является слишком маленьким, мы приветствуем все типы вкладов. Платформа массивных параллельных данных с открытым исходным кодом для аналитики, машинного обучения и искусственного интеллекта. Быстро создавайте и развертывайте модели для сложных приложений в области кибербезопасности, профилактического обслуживания, управления рисками, обнаружения мошенничества и многих других областей. Испытайте полнофункциональную интегрированную платформу аналитики с открытым исходным кодом. - 13
Апач Друид
Друид
Apache Druid — это распределенное хранилище данных с открытым исходным кодом. Основной дизайн Druid сочетает в себе идеи из хранилищ данных, баз данных временных рядов и поисковых систем для создания высокопроизводительной аналитической базы данных в реальном времени для широкого спектра вариантов использования. Druid объединяет ключевые характеристики каждой из трех систем в свой уровень приема, формат хранения, уровень запросов и базовую архитектуру. Druid хранит и сжимает каждый столбец по отдельности, и ему нужно читать только те, которые необходимы для конкретного запроса, который поддерживает быстрое сканирование, ранжирование и groupBys. Druid создает инвертированные индексы для строковых значений для быстрого поиска и фильтрации. Готовые коннекторы для Apache Kafka, HDFS, AWS S3, потоковых процессоров и многого другого. Druid интеллектуально разделяет данные на основе времени, а запросы на основе времени выполняются значительно быстрее, чем традиционные базы данных.
Масштабируйтесь вверх или вниз, просто добавляя или удаляя серверы, и Druid автоматически перебалансирует. Отказоустойчивая архитектура обходит сбои сервера. - 14
CrateDB
Crate.io
Crate.io является разработчиком CrateDB, глобальной базы данных с несколькими моделями, которая позволяет компаниям получать доступ к данным в любом масштабе. CrateDB — это распределенная база данных SQL, построенная на основе облачной архитектуры. Он сочетает в себе знакомство с SQL с масштабируемостью и гибкостью данных NoSQL, позволяя разработчикам: — Используйте SQL для обработки любого типа данных, структурированных или неструктурированных — Выполняйте SQL-запросы со скоростью в реальном времени, даже JOIN и агрегаты. — Масштаб просто CrateDB доступен в облаке, на периферии и локально, чтобы удовлетворить потребности каждого. Клиенты часто используют CrateDB для хранения и запроса данных в реальном времени.
Это связано с тем, что CrateDB позволяет легко и экономично обрабатывать скорость, объем и разнообразие машинных и журнальных данных.
Crate.io был удостоен почетного упоминания в магическом квадранте Gartner 2021 года для систем управления облачными базами данных. - 15
DataStax
ДатаСтакс
Открытый многооблачный стек для современных приложений для работы с данными. Построен на базе Apache Cassandra™ с открытым исходным кодом. Глобальный масштаб и 100% время безотказной работы без привязки к поставщику. Развертывание в мультиоблачной, локальной среде, среде с открытым исходным кодом и Kubernetes. Гибкость и оплата по мере использования для повышения совокупной стоимости владения. Начните строить быстрее с API-интерфейсами Stargate для NoSQL, реального времени, реактивного, JSON, REST и GraphQL. Избавьтесь от сложности нескольких проектов OSS и API, которые не масштабируются.
Идеально подходит для коммерции, мобильных устройств, искусственного интеллекта и машинного обучения, Интернета вещей, микросервисов, социальных сетей, игр и многофункциональных интерактивных приложений, масштабирование которых необходимо в зависимости от спроса. Получите возможность создавать современные приложения для работы с данными с помощью Astra, базы данных как услуги на базе Apache Cassandra™. Используйте REST, GraphQL, JSON с вашим любимым фреймворком с полным стеком. Богатые интерактивные приложения, эластичные и готовые к распространению вирусов с первого дня. Apache Cassandra DBaaS с оплатой по мере использования, масштабируемая без усилий и по доступной цене. - 16
МарияДБ
МарияДБ
Платформа MariaDB — это комплексное решение корпоративной базы данных с открытым исходным кодом. Он обладает универсальностью для поддержки транзакционных, аналитических и гибридных рабочих нагрузок, а также реляционных, JSON и гибридных моделей данных.
Кроме того, он может масштабироваться от автономных баз данных и хранилищ данных до полностью распределенного SQL для выполнения миллионов транзакций в секунду и выполнения интерактивной специальной аналитики миллиардов строк. MariaDB может быть развернута локально на обычном оборудовании, доступна во всех основных общедоступных облаках и через MariaDB SkySQL в качестве полностью управляемой облачной базы данных. Чтобы узнать больше, посетите mariadb.com. - 17
МонетДБ
МонетДБ
Выберите из широкого спектра функций SQL для реализации ваших приложений от чистой аналитики до гибридной транзакционной/аналитической обработки. Когда вам интересно, что содержится в ваших данных; когда вы хотите работать эффективно; когда ваш крайний срок подходит к концу: MonetDB возвращает результат запроса за считанные секунды или даже меньше. Когда вы хотите (повторно) использовать свой собственный код; когда вам нужны специализированные функции: используйте хуки, чтобы добавить свои собственные пользовательские функции в SQL, Python, R или C/C++.
Присоединяйтесь к нам и расширяйте сообщество MonetDB в более чем 130 странах со студентами, преподавателями, исследователями, стартапами, малыми предприятиями и многонациональными предприятиями. Присоединяйтесь к ведущей базе данных в сфере аналитических вакансий и исследуйте инновации! Не теряйте время на сложной установке, используйте простую настройку MonetDB, чтобы быстро настроить и запустить свою СУБД. - 18
Apache HBase
Фонд программного обеспечения Apache
Используйте Apache HBase™, когда вам нужен произвольный доступ для чтения/записи в режиме реального времени к вашим большим данным. Цель этого проекта — размещение очень больших таблиц — миллиардов строк и миллионов столбцов — на кластерах стандартного оборудования. Поддержка автоматического перехода на другой ресурс между серверами RegionServer. Простой в использовании Java API для клиентского доступа. Шлюз Thrift и веб-служба REST-ful, которая поддерживает параметры кодирования XML, Protobuf и двоичных данных.
Поддержка экспорта метрик через подсистему метрик Hadoop в файлы или Ganglia; или через JMX. - 19
Хранилище таблиц Azure
Майкрософт
Используйте хранилище таблиц Azure для хранения петабайт полуструктурированных данных и снижения затрат. В отличие от многих хранилищ данных — локальных или облачных — хранилище таблиц позволяет выполнять масштабирование без необходимости вручную сегментировать набор данных. Доступность также не вызывает беспокойства: благодаря геоизбыточному хранилищу сохраненные данные реплицируются три раза в одном регионе и еще три раза в другом регионе, удаленном на сотни километров. Хранилище таблиц отлично подходит для гибких наборов данных — данных пользователей веб-приложений, адресных книг, информации об устройствах и других метаданных — и позволяет создавать облачные приложения без привязки модели данных к конкретным схемам. Поскольку разные строки в одной и той же таблице могут иметь различную структуру — например, информация о заказе в одной строке, а информация о клиенте — в другой, вы можете развивать свое приложение и схему таблицы, не переводя их в автономный режим.
Хранилище таблиц использует модель строгой согласованности. - 20
Апач Куду
Фонд программного обеспечения Apache
В кластере Kudu хранятся таблицы, которые выглядят точно так же, как таблицы, к которым вы привыкли в реляционных (SQL) базах данных. Таблица может быть простой, состоящей из двоичного ключа и значения, или сложной, состоящей из нескольких сотен различных строго типизированных атрибутов. Как и в SQL, каждая таблица имеет первичный ключ, состоящий из одного или нескольких столбцов. Это может быть отдельный столбец, такой как уникальный идентификатор пользователя, или составной ключ, такой как кортеж (хост, метрика, отметка времени) для машинной базы данных временных рядов. Строки можно эффективно читать, обновлять или удалять по их первичному ключу. Простая модель данных Kudu позволяет с легкостью портировать устаревшие приложения или создавать новые, не нужно беспокоиться о том, как кодировать ваши данные в двоичные BLOB-объекты или разобраться в огромной базе данных, полной трудно интерпретируемых JSON.
Таблицы дают самоописание, поэтому для анализа данных можно использовать стандартные инструменты, такие как механизмы SQL или Spark. API-интерфейсы Kudu просты в использовании. - 21
Паркет Apache
Фонд программного обеспечения Apache
Мы создали Parquet, чтобы сделать преимущества сжатого и эффективного столбцового представления данных доступными для любого проекта в экосистеме Hadoop. Parquet создан с нуля с учетом сложных вложенных структур данных и использует алгоритм измельчения и сборки записей, описанный в статье Dremel. Мы считаем, что этот подход лучше, чем простое выравнивание вложенных пространств имен. Parquet поддерживает очень эффективные схемы сжатия и кодирования. Несколько проектов продемонстрировали влияние на производительность применения правильной схемы сжатия и кодирования данных. Parquet позволяет указывать схемы сжатия на уровне каждого столбца и рассчитан на будущее, позволяя добавлять больше кодировок по мере их изобретения и реализации.
Паркет создан для того, чтобы им мог пользоваться каждый. Экосистема Hadoop богата платформами обработки данных, и мы не заинтересованы в том, чтобы играть в фаворитов. - 22
Гипертаблица
Гипертаблица
Hypertable обеспечивает масштабируемую емкость базы данных при максимальной производительности, чтобы ускорить приложения для работы с большими данными и уменьшить потребность в оборудовании. Hypertable обеспечивает максимальную эффективность и превосходную производительность по сравнению с конкурентами, что приводит к значительной экономии средств. Проверенный масштабируемый дизайн, на котором работают сотни сервисов Google. Все преимущества открытого исходного кода с сильным и процветающим сообществом. Реализация C++ для оптимальной производительности. Круглосуточная поддержка вашего критически важного для бизнеса приложения для работы с большими данными. Беспрецедентный доступ к интеллектуальным возможностям Hypertable от работодателя всех основных разработчиков Hypertable.
Hypertable был разработан специально для решения проблемы масштабируемости, проблемы, с которой не справляется традиционная СУБД. Hypertable основан на дизайне, разработанном Google для удовлетворения их требований к масштабируемости, и решает проблему масштабирования лучше, чем любое другое решение NoSQL. - 23
ИнфиниДБ
База данных баз данных
InfiniDB — это СУБД со хранилищем столбцов, оптимизированная для рабочих нагрузок OLAP. Он имеет распределенную архитектуру для поддержки массивной параллельной обработки (MPP). Он использует MySQL в качестве внешнего интерфейса, поэтому пользователи, знакомые с MySQL, могут быстро перейти на InfiniDB. Благодаря этому пользователи могут подключаться к InfiniDB с помощью любого коннектора MySQL. InfiniDB применяет MVCC для управления параллелизмом. Он использует термин System Change Number (SCN) для обозначения версии системы. В своем диспетчере разрешения блоков (BRM) он использует три структуры: буфер версий, структуру подстановки версий и диспетчер блоков буфера версий для управления несколькими версиями.
InfiniDB применяет обнаружение взаимоблокировок для разрешения конфликтов. InfiniDB использует MySQL в качестве внешнего интерфейса и поддерживает все синтаксис MySQL, включая внешние ключи. InfiniDB — это столбцовая СУБД. Для каждого столбца InfiniDB применяет разбиение по диапазонам и сохраняет минимальное и максимальное значение каждого раздела в небольшой структуре, называемой картой экстентов. - 24
qikkDB
qikkDB
QikkDB — это столбцовая база данных с ускорением на GPU, обеспечивающая невероятную производительность для сложных полигональных операций и анализа больших данных. Когда вы считаете свои данные миллиардами и хотите видеть результаты в реальном времени, вам нужна qikkDB. Мы поддерживаем операционные системы Windows и Linux. Мы используем Google Tests в качестве основы для тестирования. В проекте сотни юнит-тестов и десятки интеграционных тестов. Для разработки под Windows Microsoft Visual Studio 2019рекомендуется, и его зависимости: минимальная версия CUDA 10.
2, CMake 3.15 или новее, vcpkg, boost. Для разработки под Linux необходимы минимальная версия CUDA версии 10.2, CMake 3.15 или новее и поддержка boost. Этот проект находится под лицензией Apache License, Version 2.0. Для установки qikkDB можно использовать сценарий установки или файл докер-файла. - 25
Апач Пино
Корпорация Apache
Pinot предназначен для ответа на запросы OLAP с малой задержкой на неизменяемых данных. Подключаемые технологии индексирования — Sorted Index, Bitmap Index, Inverted Index. Соединения в настоящее время не поддерживаются, но эту проблему можно решить, используя для запросов Trino или PrestoDB. SQL-подобный язык, который поддерживает выбор, агрегацию, фильтрацию, группировку, упорядочение, отдельные запросы к данным. Состоит как из оффлайн, так и из таблицы в реальном времени. Используйте таблицу в реальном времени только для охвата сегментов, для которых офлайн-данные еще могут быть недоступны.
Выявляйте правильные аномалии, настраивая поток обнаружения аномалий и поток уведомлений.
 Компания работает во многих секторах: банковском, страховом, лизинговом, коммерческом, медиа и телекоммуникационном, а также в государственном секторе. Инновационные программные решения для повседневного управления и процессов принятия решений в любой отрасли
Компания работает во многих секторах: банковском, страховом, лизинговом, коммерческом, медиа и телекоммуникационном, а также в государственном секторе. Инновационные программные решения для повседневного управления и процессов принятия решений в любой отрасли Независимо от того, переносите ли вы данные в Snowflake или извлекаете информацию из Snowflake, наши технологические партнеры и системные интеграторы помогут вам развернуть Snowflake для достижения успеха.
Независимо от того, переносите ли вы данные в Snowflake или извлекаете информацию из Snowflake, наши технологические партнеры и системные интеграторы помогут вам развернуть Snowflake для достижения успеха.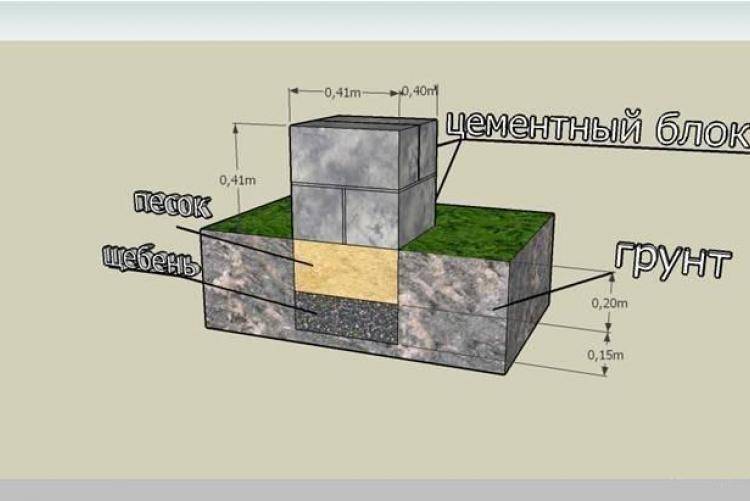 org/ListItem»>
4
org/ListItem»>
4ClickHouse
Яндекс
ClickHouse — это быстрая система управления базами данных OLAP с открытым исходным кодом. Он ориентирован на столбцы и позволяет создавать аналитические отчеты с использованием SQL-запросов в режиме реального времени. Производительность ClickHouse превосходит сопоставимые системы управления базами данных, ориентированные на столбцы, доступные в настоящее время на рынке. Он обрабатывает от сотен миллионов до более чем миллиарда строк и десятков гигабайт данных на один сервер в секунду. ClickHouse максимально использует все доступное оборудование для максимально быстрой обработки каждого запроса. Пиковая производительность обработки одного запроса составляет более 2 терабайт в секунду (после распаковки только используемые столбцы). При распределенной установке операции чтения автоматически распределяются между работоспособными репликами, чтобы избежать увеличения задержки. ClickHouse поддерживает асинхронную репликацию с несколькими мастерами и может быть развернут в нескольких центрах обработки данных. Все узлы равны, что позволяет избежать единых точек отказа.
Все узлы равны, что позволяет избежать единых точек отказа.
 Используйте знакомый SQL, включая соединения, фильтры и агрегации. Это невероятно быстро, поскольку Rockset автоматически индексирует все поля ваших данных. Обрабатывайте быстрые запросы, которые обеспечивают работу приложений, микросервисов, интерактивных информационных панелей и блокнотов по обработке и анализу данных, которые вы создаете. Масштабируйте, не беспокоясь о серверах, сегментах или пейджерах.
Используйте знакомый SQL, включая соединения, фильтры и агрегации. Это невероятно быстро, поскольку Rockset автоматически индексирует все поля ваших данных. Обрабатывайте быстрые запросы, которые обеспечивают работу приложений, микросервисов, интерактивных информационных панелей и блокнотов по обработке и анализу данных, которые вы создаете. Масштабируйте, не беспокоясь о серверах, сегментах или пейджерах. Redshift позволяет легко сохранять результаты ваших запросов обратно в озеро данных S3, используя открытые форматы, такие как Apache Parquet, для дальнейшего анализа с помощью других аналитических сервисов, таких как Amazon EMR, Amazon Athena и Amazon SageMaker. Redshift — это самое быстрое облачное хранилище данных в мире, которое с каждым годом становится все быстрее. Для рабочих нагрузок, требующих высокой производительности, вы можете использовать новые инстансы RA3, чтобы повысить производительность до трех раз по сравнению с любым облачным хранилищем данных.
Redshift позволяет легко сохранять результаты ваших запросов обратно в озеро данных S3, используя открытые форматы, такие как Apache Parquet, для дальнейшего анализа с помощью других аналитических сервисов, таких как Amazon EMR, Amazon Athena и Amazon SageMaker. Redshift — это самое быстрое облачное хранилище данных в мире, которое с каждым годом становится все быстрее. Для рабочих нагрузок, требующих высокой производительности, вы можете использовать новые инстансы RA3, чтобы повысить производительность до трех раз по сравнению с любым облачным хранилищем данных.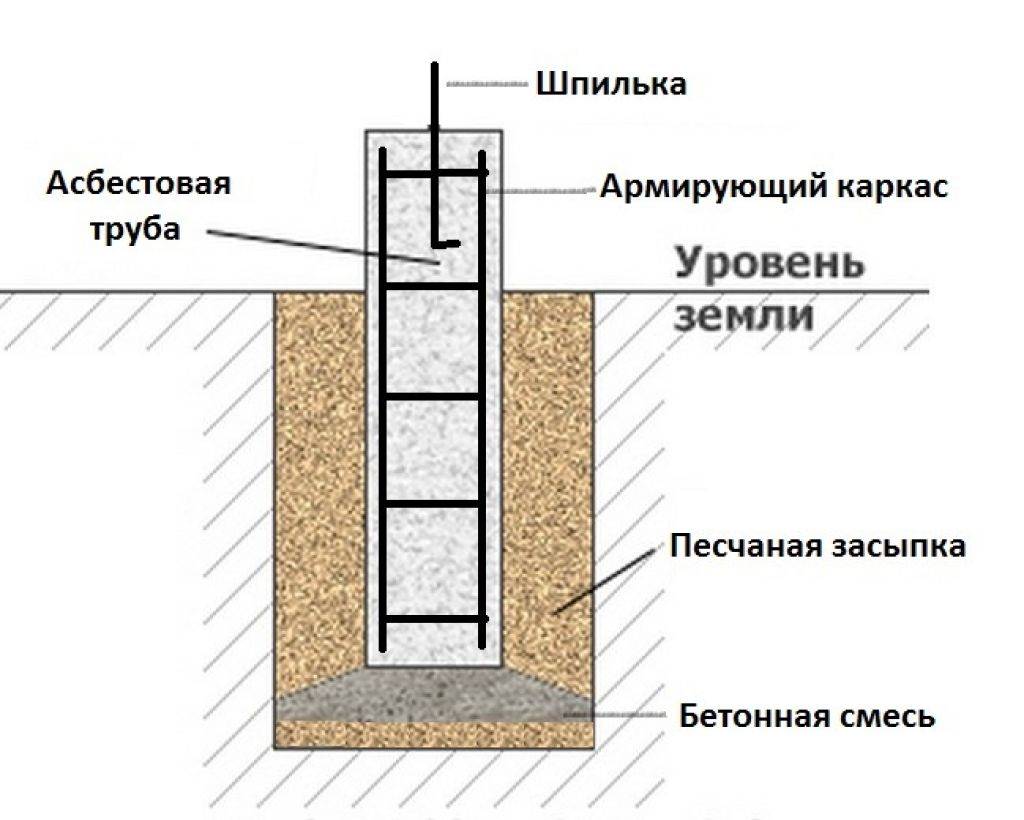 Если вы когда-либо сталкивались с нехваткой необходимых вам данных, временем на создание отчетов или длинной очередью к вашему эксперту по бизнес-аналитике, подумайте о Querona. Querona использует встроенный механизм больших данных для обработки растущих объемов данных. Повторяющиеся запросы могут кэшироваться или рассчитываться заранее. Оптимизация требует меньше усилий, поскольку Querona автоматически предлагает улучшения запросов. Querona расширяет возможности бизнес-аналитиков и специалистов по данным, предоставляя им возможности самообслуживания. Они могут легко обнаруживать и прототипировать модели данных, добавлять новые источники данных, экспериментировать с оптимизацией запросов и копаться в необработанных данных. Требуется меньше ИТ. Теперь пользователи могут получать оперативные данные независимо от того, где они хранятся. Если базы данных слишком заняты, чтобы к ним можно было обращаться в режиме реального времени, Querona кэширует данные.
Если вы когда-либо сталкивались с нехваткой необходимых вам данных, временем на создание отчетов или длинной очередью к вашему эксперту по бизнес-аналитике, подумайте о Querona. Querona использует встроенный механизм больших данных для обработки растущих объемов данных. Повторяющиеся запросы могут кэшироваться или рассчитываться заранее. Оптимизация требует меньше усилий, поскольку Querona автоматически предлагает улучшения запросов. Querona расширяет возможности бизнес-аналитиков и специалистов по данным, предоставляя им возможности самообслуживания. Они могут легко обнаруживать и прототипировать модели данных, добавлять новые источники данных, экспериментировать с оптимизацией запросов и копаться в необработанных данных. Требуется меньше ИТ. Теперь пользователи могут получать оперативные данные независимо от того, где они хранятся. Если базы данных слишком заняты, чтобы к ним можно было обращаться в режиме реального времени, Querona кэширует данные. org/ListItem»>
8
org/ListItem»>
8кдб+
Кх Системы
Высокопроизводительная кросс-платформенная столбцовая база данных исторических временных рядов, включающая: — Вычислительный движок в памяти — Потоковый процессор в реальном времени — Выразительный язык запросов и программирования под названием q
. Наша серия веб-трансляций «Под капотом» позволит вам подробно изучить функции Vertica, предоставленные инженерами и техническими экспертами Vertica, и узнать, что делает эту базу данных самой быстрой и масштабируемой передовой аналитической базой данных на рынке. От приложений для совместного использования и интеллектуального сельского хозяйства до профилактического обслуживания и клиентской аналитики — Vertica поддерживает ведущих мировых революционеров, использующих данные, в их стремлении к трансформации отрасли и бизнеса.
Наша серия веб-трансляций «Под капотом» позволит вам подробно изучить функции Vertica, предоставленные инженерами и техническими экспертами Vertica, и узнать, что делает эту базу данных самой быстрой и масштабируемой передовой аналитической базой данных на рынке. От приложений для совместного использования и интеллектуального сельского хозяйства до профилактического обслуживания и клиентской аналитики — Vertica поддерживает ведущих мировых революционеров, использующих данные, в их стремлении к трансформации отрасли и бизнеса. Извлекайте ценные сведения из данных, хранящихся в облаках, с помощью гибкого многооблачного аналитического решения. Запрашивайте потоковые данные в режиме реального времени и получайте актуальную информацию обо всех ваших бизнес-процессах. Легко прогнозируйте результаты бизнеса с помощью встроенного машинного обучения и без необходимости перемещения данных. Безопасный доступ и обмен аналитическими данными в вашей организации с помощью нескольких щелчков мыши. С легкостью создавайте потрясающие отчеты и информационные панели, используя популярные инструменты бизнес-аналитики, готовые к использованию. Положитесь на надежные средства управления безопасностью, управлением и надежностью BigQuery, которые обеспечивают высокую доступность и 9SLA 9,99% времени безотказной работы. Защитите свои данные с помощью шифрования по умолчанию и ключей шифрования, управляемых клиентом.
Извлекайте ценные сведения из данных, хранящихся в облаках, с помощью гибкого многооблачного аналитического решения. Запрашивайте потоковые данные в режиме реального времени и получайте актуальную информацию обо всех ваших бизнес-процессах. Легко прогнозируйте результаты бизнеса с помощью встроенного машинного обучения и без необходимости перемещения данных. Безопасный доступ и обмен аналитическими данными в вашей организации с помощью нескольких щелчков мыши. С легкостью создавайте потрясающие отчеты и информационные панели, используя популярные инструменты бизнес-аналитики, готовые к использованию. Положитесь на надежные средства управления безопасностью, управлением и надежностью BigQuery, которые обеспечивают высокую доступность и 9SLA 9,99% времени безотказной работы. Защитите свои данные с помощью шифрования по умолчанию и ключей шифрования, управляемых клиентом. Быстрота и производительность. Используйте Cloud Bigtable в качестве механизма хранения, который растет вместе с вами от первого гигабайта до петабайта для приложений с малой задержкой, а также для высокопроизводительной обработки данных и аналитики.
Плавное масштабирование и репликация: начните с одного узла на кластер и плавно масштабируйте до сотен узлов, динамически поддерживающих пиковую нагрузку. Репликация также обеспечивает высокую доступность и изоляцию рабочей нагрузки для приложений, работающих в режиме реального времени.
Простой и интегрированный: полностью управляемый сервис, который легко интегрируется с такими инструментами для работы с большими данными, как Hadoop, Dataflow и Dataproc. Кроме того, поддержка стандарта HBase API с открытым исходным кодом упрощает начало работы для групп разработчиков.
Быстрота и производительность. Используйте Cloud Bigtable в качестве механизма хранения, который растет вместе с вами от первого гигабайта до петабайта для приложений с малой задержкой, а также для высокопроизводительной обработки данных и аналитики.
Плавное масштабирование и репликация: начните с одного узла на кластер и плавно масштабируйте до сотен узлов, динамически поддерживающих пиковую нагрузку. Репликация также обеспечивает высокую доступность и изоляцию рабочей нагрузки для приложений, работающих в режиме реального времени.
Простой и интегрированный: полностью управляемый сервис, который легко интегрируется с такими инструментами для работы с большими данными, как Hadoop, Dataflow и Dataproc. Кроме того, поддержка стандарта HBase API с открытым исходным кодом упрощает начало работы для групп разработчиков. Он обеспечивает мощную и быструю аналитику объемов данных в петабайтах. База данных Greenplum, специально ориентированная на аналитику больших данных, оснащена самым передовым в мире оптимизатором запросов на основе затрат, обеспечивающим высокую производительность аналитических запросов для больших объемов данных. Проект Greenplum Database® выпущен под лицензией Apache 2. Мы хотим поблагодарить всех наших нынешних участников сообщества и заинтересованы во всех новых потенциальных вкладах. Для сообщества базы данных Greenplum ни один вклад не является слишком маленьким, мы приветствуем все типы вкладов. Платформа массивных параллельных данных с открытым исходным кодом для аналитики, машинного обучения и искусственного интеллекта. Быстро создавайте и развертывайте модели для сложных приложений в области кибербезопасности, профилактического обслуживания, управления рисками, обнаружения мошенничества и многих других областей. Испытайте полнофункциональную интегрированную платформу аналитики с открытым исходным кодом.
Он обеспечивает мощную и быструю аналитику объемов данных в петабайтах. База данных Greenplum, специально ориентированная на аналитику больших данных, оснащена самым передовым в мире оптимизатором запросов на основе затрат, обеспечивающим высокую производительность аналитических запросов для больших объемов данных. Проект Greenplum Database® выпущен под лицензией Apache 2. Мы хотим поблагодарить всех наших нынешних участников сообщества и заинтересованы во всех новых потенциальных вкладах. Для сообщества базы данных Greenplum ни один вклад не является слишком маленьким, мы приветствуем все типы вкладов. Платформа массивных параллельных данных с открытым исходным кодом для аналитики, машинного обучения и искусственного интеллекта. Быстро создавайте и развертывайте модели для сложных приложений в области кибербезопасности, профилактического обслуживания, управления рисками, обнаружения мошенничества и многих других областей. Испытайте полнофункциональную интегрированную платформу аналитики с открытым исходным кодом.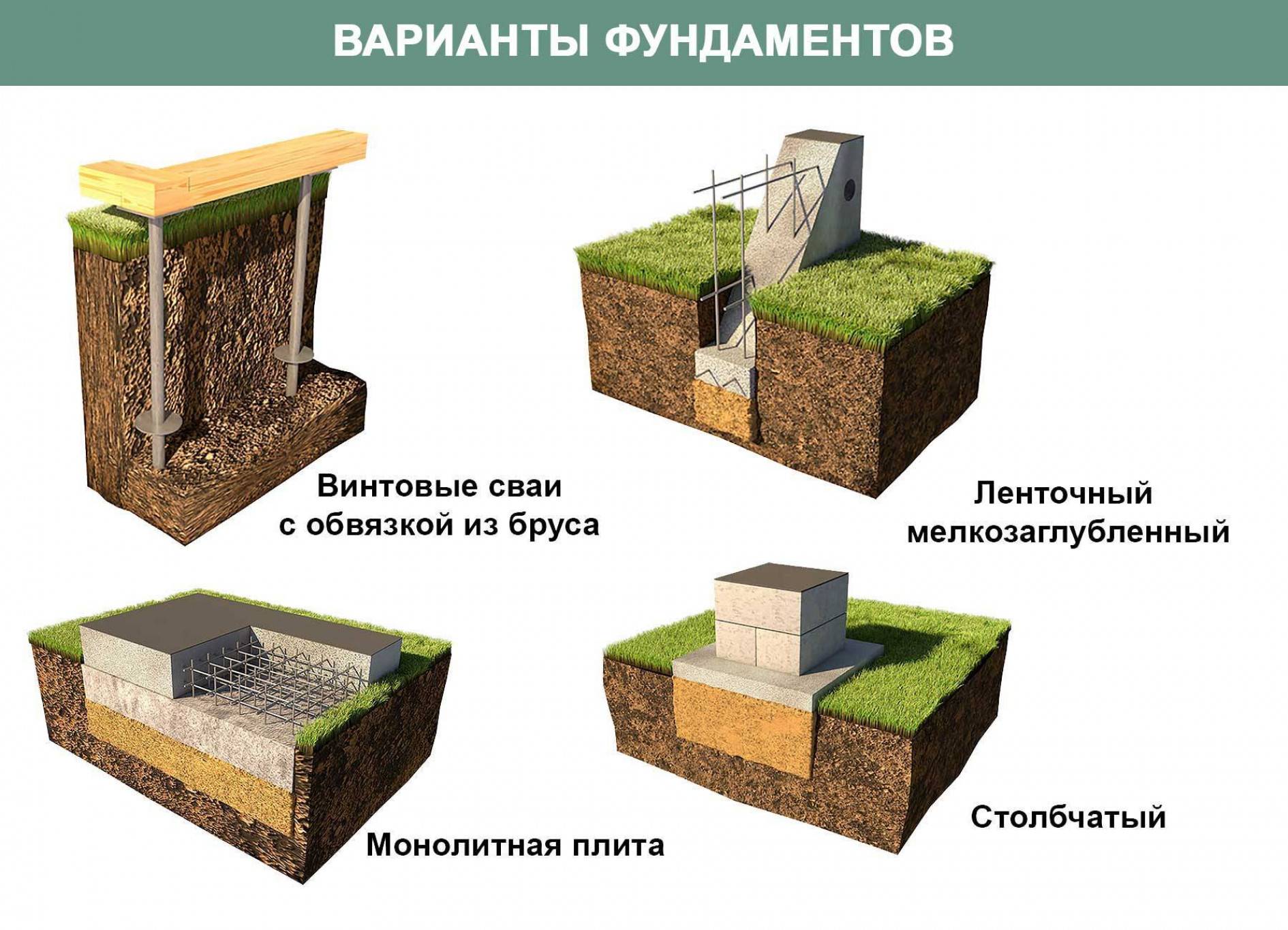
 Масштабируйтесь вверх или вниз, просто добавляя или удаляя серверы, и Druid автоматически перебалансирует. Отказоустойчивая архитектура обходит сбои сервера.
Масштабируйтесь вверх или вниз, просто добавляя или удаляя серверы, и Druid автоматически перебалансирует. Отказоустойчивая архитектура обходит сбои сервера.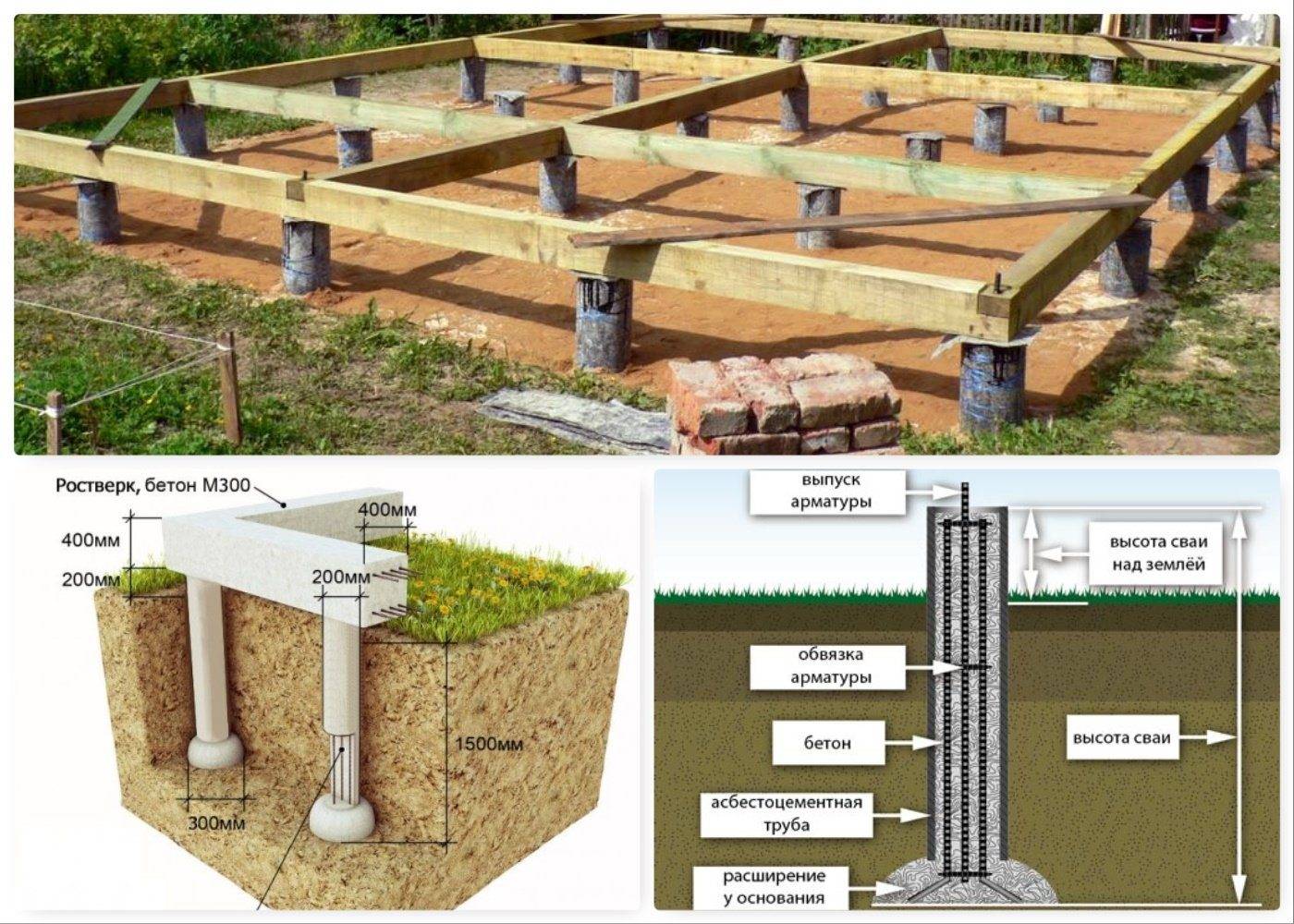 Это связано с тем, что CrateDB позволяет легко и экономично обрабатывать скорость, объем и разнообразие машинных и журнальных данных.
Crate.io был удостоен почетного упоминания в магическом квадранте Gartner 2021 года для систем управления облачными базами данных.
Это связано с тем, что CrateDB позволяет легко и экономично обрабатывать скорость, объем и разнообразие машинных и журнальных данных.
Crate.io был удостоен почетного упоминания в магическом квадранте Gartner 2021 года для систем управления облачными базами данных. Идеально подходит для коммерции, мобильных устройств, искусственного интеллекта и машинного обучения, Интернета вещей, микросервисов, социальных сетей, игр и многофункциональных интерактивных приложений, масштабирование которых необходимо в зависимости от спроса. Получите возможность создавать современные приложения для работы с данными с помощью Astra, базы данных как услуги на базе Apache Cassandra™. Используйте REST, GraphQL, JSON с вашим любимым фреймворком с полным стеком. Богатые интерактивные приложения, эластичные и готовые к распространению вирусов с первого дня. Apache Cassandra DBaaS с оплатой по мере использования, масштабируемая без усилий и по доступной цене.
Идеально подходит для коммерции, мобильных устройств, искусственного интеллекта и машинного обучения, Интернета вещей, микросервисов, социальных сетей, игр и многофункциональных интерактивных приложений, масштабирование которых необходимо в зависимости от спроса. Получите возможность создавать современные приложения для работы с данными с помощью Astra, базы данных как услуги на базе Apache Cassandra™. Используйте REST, GraphQL, JSON с вашим любимым фреймворком с полным стеком. Богатые интерактивные приложения, эластичные и готовые к распространению вирусов с первого дня. Apache Cassandra DBaaS с оплатой по мере использования, масштабируемая без усилий и по доступной цене.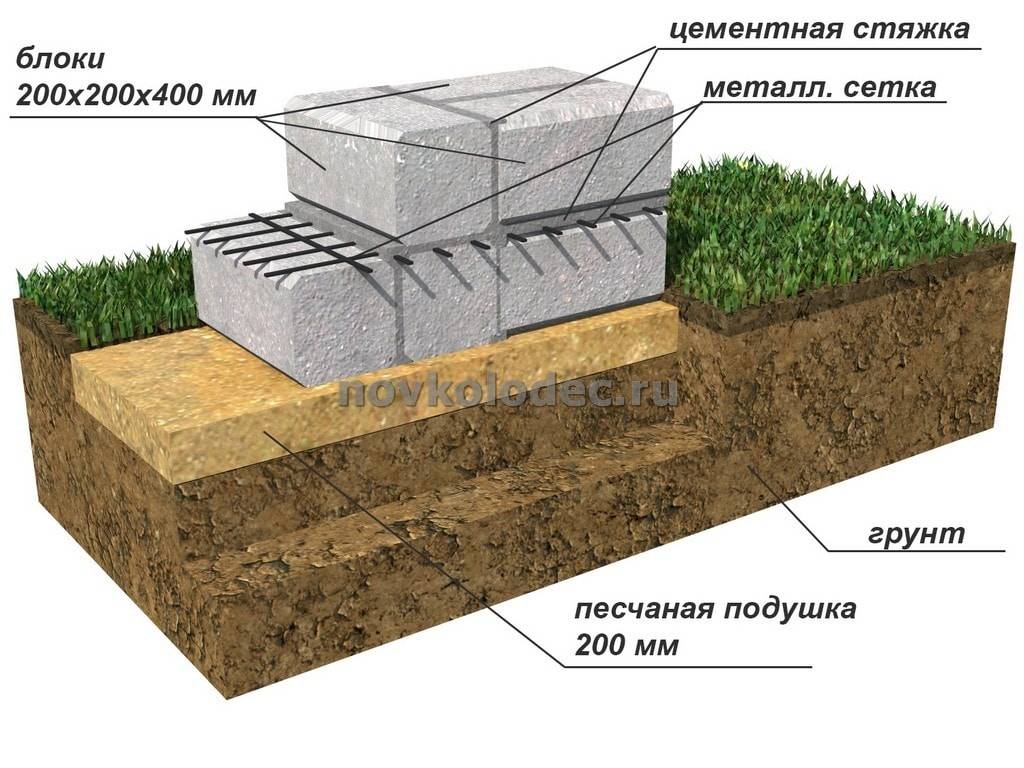 Кроме того, он может масштабироваться от автономных баз данных и хранилищ данных до полностью распределенного SQL для выполнения миллионов транзакций в секунду и выполнения интерактивной специальной аналитики миллиардов строк. MariaDB может быть развернута локально на обычном оборудовании, доступна во всех основных общедоступных облаках и через MariaDB SkySQL в качестве полностью управляемой облачной базы данных. Чтобы узнать больше, посетите mariadb.com.
Кроме того, он может масштабироваться от автономных баз данных и хранилищ данных до полностью распределенного SQL для выполнения миллионов транзакций в секунду и выполнения интерактивной специальной аналитики миллиардов строк. MariaDB может быть развернута локально на обычном оборудовании, доступна во всех основных общедоступных облаках и через MariaDB SkySQL в качестве полностью управляемой облачной базы данных. Чтобы узнать больше, посетите mariadb.com. Присоединяйтесь к нам и расширяйте сообщество MonetDB в более чем 130 странах со студентами, преподавателями, исследователями, стартапами, малыми предприятиями и многонациональными предприятиями. Присоединяйтесь к ведущей базе данных в сфере аналитических вакансий и исследуйте инновации! Не теряйте время на сложной установке, используйте простую настройку MonetDB, чтобы быстро настроить и запустить свою СУБД.
Присоединяйтесь к нам и расширяйте сообщество MonetDB в более чем 130 странах со студентами, преподавателями, исследователями, стартапами, малыми предприятиями и многонациональными предприятиями. Присоединяйтесь к ведущей базе данных в сфере аналитических вакансий и исследуйте инновации! Не теряйте время на сложной установке, используйте простую настройку MonetDB, чтобы быстро настроить и запустить свою СУБД. Поддержка экспорта метрик через подсистему метрик Hadoop в файлы или Ganglia; или через JMX.
Поддержка экспорта метрик через подсистему метрик Hadoop в файлы или Ganglia; или через JMX. Хранилище таблиц использует модель строгой согласованности.
Хранилище таблиц использует модель строгой согласованности.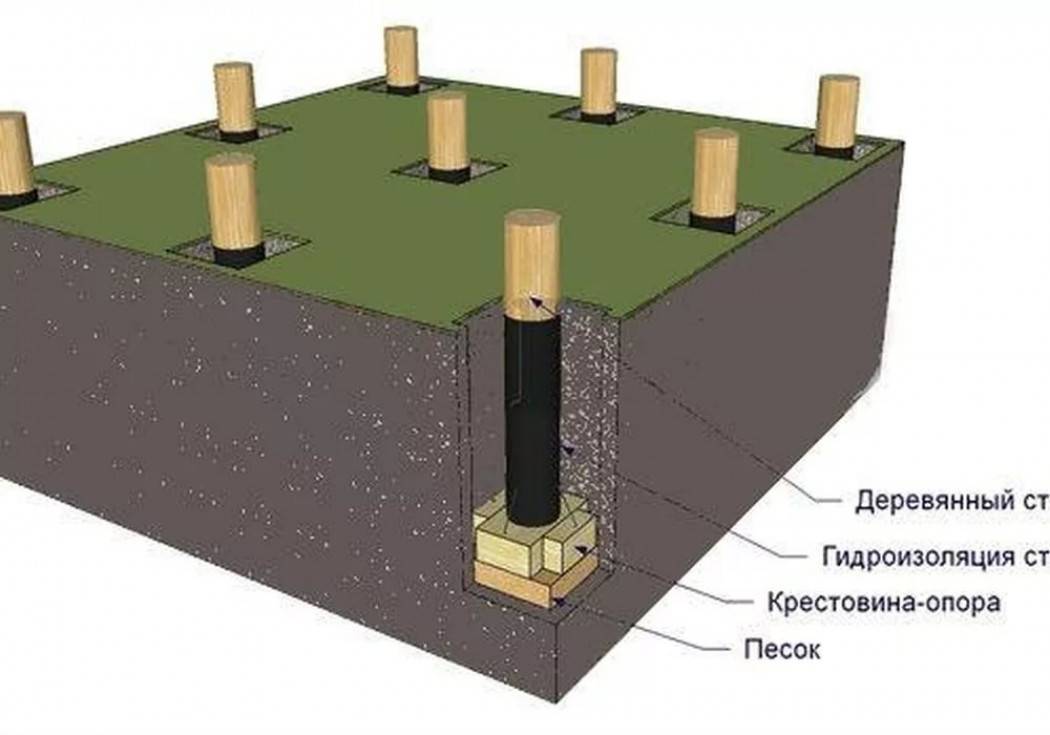 Таблицы дают самоописание, поэтому для анализа данных можно использовать стандартные инструменты, такие как механизмы SQL или Spark. API-интерфейсы Kudu просты в использовании.
Таблицы дают самоописание, поэтому для анализа данных можно использовать стандартные инструменты, такие как механизмы SQL или Spark. API-интерфейсы Kudu просты в использовании. Паркет создан для того, чтобы им мог пользоваться каждый. Экосистема Hadoop богата платформами обработки данных, и мы не заинтересованы в том, чтобы играть в фаворитов.
Паркет создан для того, чтобы им мог пользоваться каждый. Экосистема Hadoop богата платформами обработки данных, и мы не заинтересованы в том, чтобы играть в фаворитов. Hypertable был разработан специально для решения проблемы масштабируемости, проблемы, с которой не справляется традиционная СУБД. Hypertable основан на дизайне, разработанном Google для удовлетворения их требований к масштабируемости, и решает проблему масштабирования лучше, чем любое другое решение NoSQL.
Hypertable был разработан специально для решения проблемы масштабируемости, проблемы, с которой не справляется традиционная СУБД. Hypertable основан на дизайне, разработанном Google для удовлетворения их требований к масштабируемости, и решает проблему масштабирования лучше, чем любое другое решение NoSQL.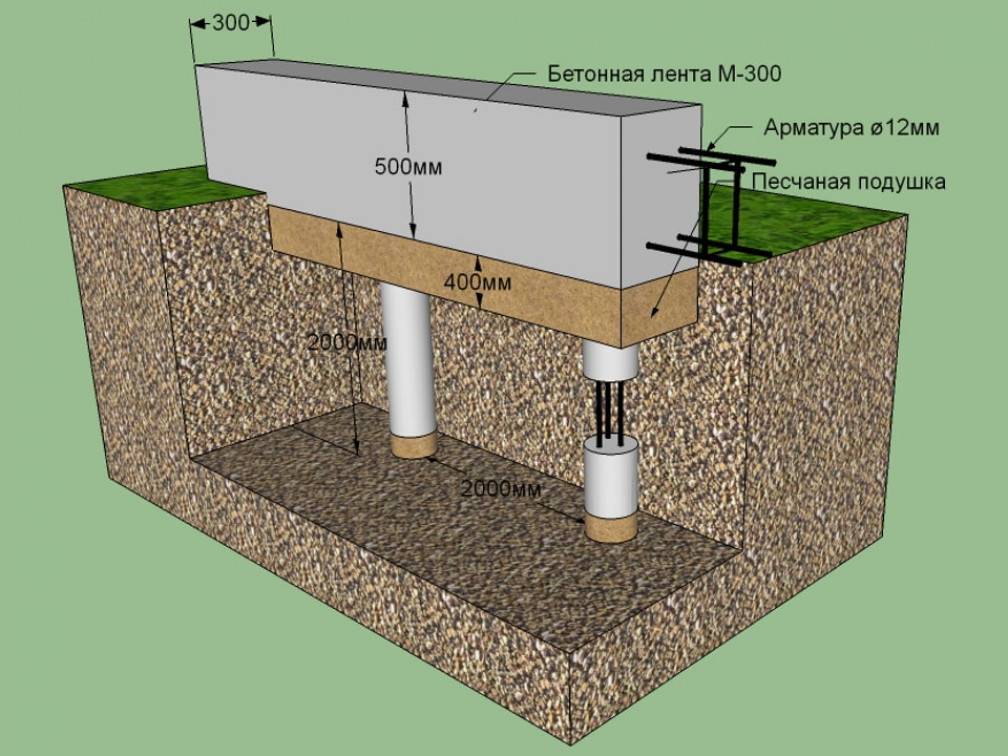 InfiniDB применяет обнаружение взаимоблокировок для разрешения конфликтов. InfiniDB использует MySQL в качестве внешнего интерфейса и поддерживает все синтаксис MySQL, включая внешние ключи. InfiniDB — это столбцовая СУБД. Для каждого столбца InfiniDB применяет разбиение по диапазонам и сохраняет минимальное и максимальное значение каждого раздела в небольшой структуре, называемой картой экстентов.
InfiniDB применяет обнаружение взаимоблокировок для разрешения конфликтов. InfiniDB использует MySQL в качестве внешнего интерфейса и поддерживает все синтаксис MySQL, включая внешние ключи. InfiniDB — это столбцовая СУБД. Для каждого столбца InfiniDB применяет разбиение по диапазонам и сохраняет минимальное и максимальное значение каждого раздела в небольшой структуре, называемой картой экстентов. 2, CMake 3.15 или новее, vcpkg, boost. Для разработки под Linux необходимы минимальная версия CUDA версии 10.2, CMake 3.15 или новее и поддержка boost. Этот проект находится под лицензией Apache License, Version 2.0. Для установки qikkDB можно использовать сценарий установки или файл докер-файла.
2, CMake 3.15 или новее, vcpkg, boost. Для разработки под Linux необходимы минимальная версия CUDA версии 10.2, CMake 3.15 или новее и поддержка boost. Этот проект находится под лицензией Apache License, Version 2.0. Для установки qikkDB можно использовать сценарий установки или файл докер-файла. Выявляйте правильные аномалии, настраивая поток обнаружения аномалий и поток уведомлений.
Выявляйте правильные аномалии, настраивая поток обнаружения аномалий и поток уведомлений.Руководство по столбцовой базе данных
Традиционно данные хранились в реляционных базах данных с использованием формата хранения на основе строк. Однако при работе с большими объемами данных этот формат может стать узким местом, что приведет к снижению производительности запросов. Именно здесь в игру вступают столбцовые базы данных.
Традиционно данные хранились в реляционных базах данных с использованием формата хранения на основе строк. Однако при работе с большими объемами данных этот формат может стать узким местом, что приведет к снижению производительности запросов. Именно здесь в игру вступают столбцовые базы данных. Сохраняя данные в формате на основе столбцов, можно значительно повысить производительность запросов за счет минимизации объема операций ввода-вывода, необходимых во время выполнения запроса. Эта же фундаментальная функция используется современными реляционными хранилищами, такими как Amazon Redshift и Snowflake. Теперь давайте углубимся в эту статью и узнаем все о столбцовых базах данных и о том, что они привносят в таблицу.
Теперь давайте углубимся в эту статью и узнаем все о столбцовых базах данных и о том, что они привносят в таблицу.
Что такое столбцовая база данных?
Система управления столбцовыми базами данных (СУБД) — это тип базы данных, в которой информация хранится в столбцах, а не в строках. В традиционной базе данных на основе строк каждая строка содержит полную запись со всеми атрибутами записи. Однако в столбцовой базе данных в каждом столбце хранится определенный атрибут записи, и все значения этого атрибута хранятся вместе в этом столбце.
Реляционная база данных лучше всего подходит для хранения данных в виде строк, что обычно используется для транзакционных приложений. С другой стороны, столбчатая база данных предназначена для быстрого доступа к данным в столбцах, что обычно требуется для аналитических приложений. Хранение таблиц по столбцам имеет решающее значение для эффективного выполнения запросов, поскольку оно значительно снижает требования к дисковому вводу-выводу и объем данных, которые необходимо загрузить с диска.
Базы данных, ориентированные на столбцы, как и другие базы данных NoSQL, разработаны для «масштабирования» за счет использования кластеров недорогого оборудования для повышения пропускной способности, что делает их идеальными для хранения данных и обработки больших объемов данных.
Базы данных на основе строк и столбцов
Базы данных на основе строк упорядочивают данные, группируя всю информацию, связанную с определенной записью, вместе в памяти. Это традиционный метод организации данных, который предлагает определенные преимущества для быстрого хранения данных. Базы данных на основе строк специально разработаны для облегчения эффективного чтения и записи строк.
Система хранения данных на основе строк организует данные, сохраняя и извлекая данные построчно, при этом все атрибуты конкретной строки находятся в одном и том же физическом блоке данных. Этот метод оптимизирован для извлечения полных строк данных и обычно используется в традиционных системах СУБД.
Хранение данных в базе данных, ориентированной на строки, будет выглядеть следующим образом:
ID Имя Возраст Отдел
1 Steve 35 Tech
2 Дженсон 28 HR
3 Рохан 32 Продажи
В системе хранения данных на основе строк выполнение запроса извлекает все атрибуты, связанные с указанной строкой, включая те, которые не относятся к запросу. Следовательно, скорость запросов может быть снижена, особенно для запросов, которым нужны только определенные атрибуты в строке.
Базы данных на основе столбцов упорядочивают данные, группируя всю информацию, связанную с определенным полем, вместе в памяти. Они становятся все более популярными и предлагают значительные преимущества в производительности при запросе данных. Базы данных на основе столбцов специально разработаны для облегчения эффективного чтения и вычислений в столбцах.
Система хранения данных, основанная на столбцовом подходе, организует и хранит данные по столбцам, а не по строкам. Этот метод предназначен для эффективного извлечения определенных столбцов данных и обычно используется в системах анализа данных и хранилищ.
Этот метод предназначен для эффективного извлечения определенных столбцов данных и обычно используется в системах анализа данных и хранилищ.
Организация и хранение данных в хранилище данных, ориентированном на столбцы, будет выглядеть следующим образом:
ID Имя Возраст Отдел
1 Steve 35 Tech
2 Дженсон 28 HR
3 Рохан 32 Продажи
В системе хранения данных, ориентированной на столбцы, выполнение запроса извлекает только определенные столбцы запрошенных данных, что приводит к более высокой производительности запроса. Кроме того, хранилища данных, ориентированные на столбцы, могут использовать методы сжатия для уменьшения объема памяти и повышения производительности.
| Серийный номер 1 | База данных на основе строк | База данных на основе столбцов |
|---|---|---|
| 1 | Когда данные сохраняются и извлекаются построчно, существует возможность извлечения ненужных данных, если нужны только определенные данные в строке | Однако в системе хранения данных на основе столбцов данные хранятся и извлекаются по столбцам, что позволяет считывать только релевантные данные, когда это необходимо |
| 2 | Они лучше всего подходят для систем онлайн-транзакций (OLTP) | Базы данных на основе столбцов лучше всего подходят для оперативной аналитической обработки (OLAP) |
| 3 | Они неэффективны при выполнении операций, применимых ко всем наборам данных.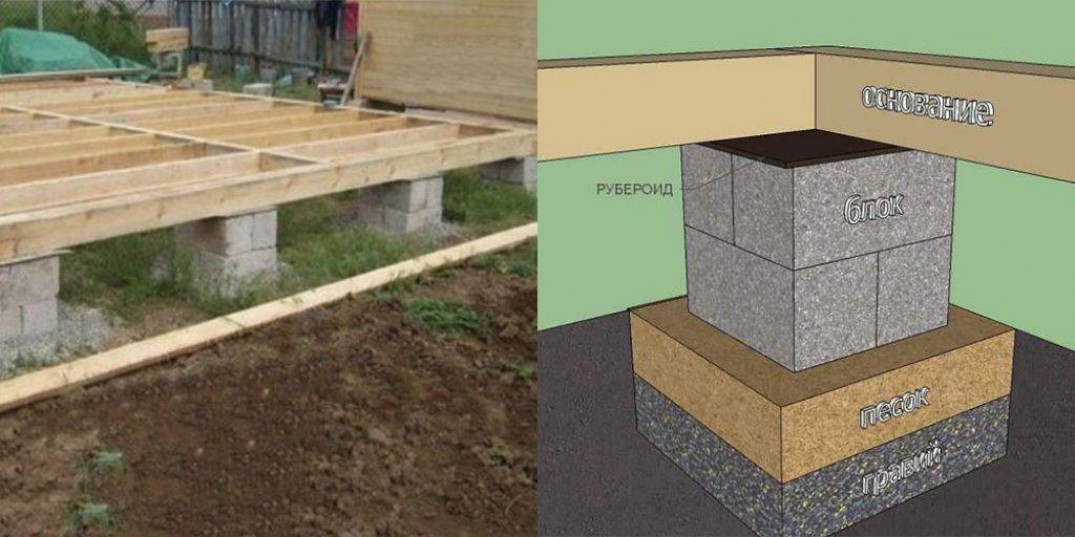 В результате выполнение задач или операций агрегирования в системе хранения данных на основе строк может быть довольно дорогостоящим В результате выполнение задач или операций агрегирования в системе хранения данных на основе строк может быть довольно дорогостоящим | .Они эффективны при выполнении операций, применимых ко всему набору данных. Это позволяет выполнять агрегацию по многочисленным строкам и столбцам в системе хранения данных на основе столбцов | .
| 4 | Примеры: PostgreSQL, MySQL | Примеры: Redshift, BigQuery, Snowflake |
Ограничения построчных баз данных
Вот несколько ограничений построчных баз данных:
- степень сжатия ограничена, поскольку все столбцы хранятся вместе на странице данных и имеют разные типы данных и значения.
- В построчной базе данных каждая запись сохраняется как строка на одной странице данных. Следовательно, невозможно получить доступ к отдельным столбцам или обработать их без предварительного доступа ко всей строке.
- Когда несколько потоков или узлов пытаются получить доступ к одной и той же странице данных, база данных на основе строк может столкнуться с конфликтами, которые ограничивают ее способность обрабатывать параллельную обработку, что влияет на ее масштабируемость.
Как столбцовые базы данных хранят данные?
Столбчатые базы данных хранят данные путем организации и хранения данных по столбцам, а не по строкам. Это означает, что все значения в данном столбце хранятся вместе, а не все значения для конкретной записи или строки. Например, все значения для столбца «возраст» будут храниться вместе, за ними следуют все значения для столбца «имя» и т. д. Это позволяет столбчатым базам данных извлекать только определенные столбцы данных, необходимые для запроса, что приводит к более высокой производительности запроса. Кроме того, базы данных, ориентированные на столбцы, могут применять методы сжатия для уменьшения необходимой емкости хранилища и повышения его эффективности.
Например,
ID Имя Возраст
1 Стив 35
2 Дженсон 28
3 Рохан 32
В этом случае он будет сохранен как: 1-2-3-Стив-Дженсон-Рохан. -35-28-32.
Преимущества хранения данных в столбцах
Хранение данных в столбцах предлагает несколько преимуществ по сравнению с хранением данных на основе строк:
- Более высокая производительность запросов: поскольку столбцовые базы данных хранят данные по столбцам, они могут извлекать только определенные столбцы данных, необходимые для запроса. , что приводит к более высокой производительности запросов.
- Эффективность сжатия. Методы сжатия, используемые в базах данных по столбцам, специально разработаны для хранения данных по столбцам, что приводит к более эффективному использованию дискового пространства и повышению производительности системы.
- Многоцелевой: столбцовые базы данных становятся все более популярными в приложениях для работы с большими данными и имеют множество вариантов использования, например для запуска кубов OLAP, хранения метаданных и выполнения аналитики в реальном времени. Эта универсальность обусловлена их способностью быстро загружать новые данные.
- Самоиндексация. Одним из преимуществ СУБД на основе столбцов является их способность использовать меньше места на диске, чем РСУБД с теми же данными, благодаря функции самоиндексации.
- Скорость и эффективность. По сравнению с другими подходами к базам данных столбцовые базы данных обладают превосходной скоростью и эффективностью при выполнении аналитических запросов. Они также эффективны при выполнении соединений, которые могут быть медленным и неэффективным методом слияния данных из двух таблиц в реляционной базе данных. И наоборот, столбчатая база данных может быстро объединять несколько наборов данных и суммировать результаты запросов в единый вывод.
 , что приводит к более высокой производительности запросов.
, что приводит к более высокой производительности запросов.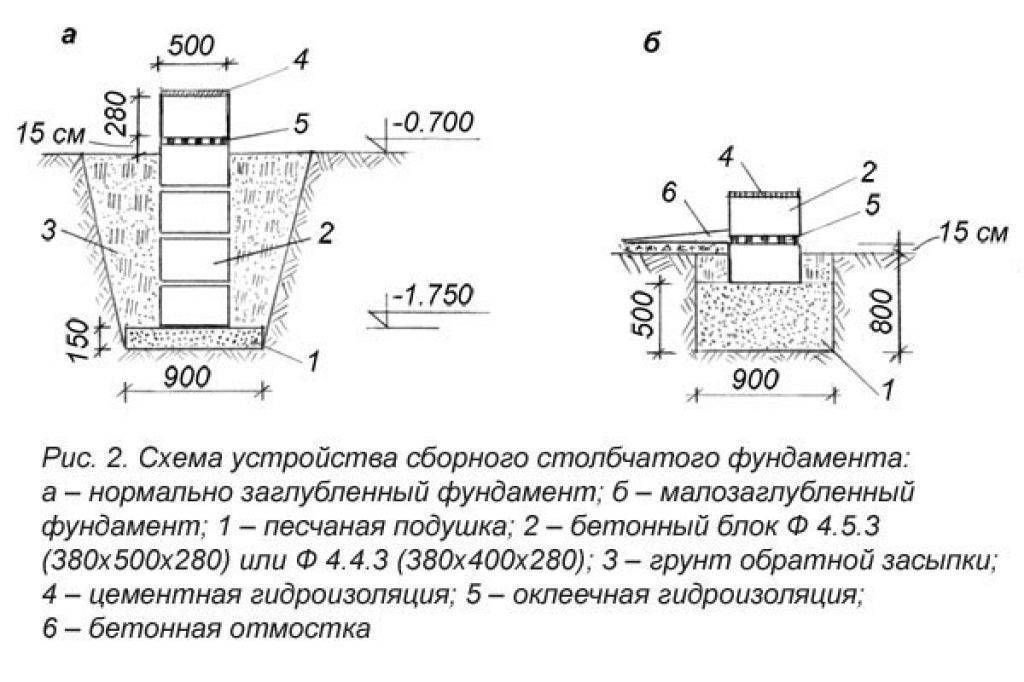 Они также эффективны при выполнении соединений, которые могут быть медленным и неэффективным методом слияния данных из двух таблиц в реляционной базе данных. И наоборот, столбчатая база данных может быстро объединять несколько наборов данных и суммировать результаты запросов в единый вывод.
Они также эффективны при выполнении соединений, которые могут быть медленным и неэффективным методом слияния данных из двух таблиц в реляционной базе данных. И наоборот, столбчатая база данных может быстро объединять несколько наборов данных и суммировать результаты запросов в единый вывод.
Как столбцовые базы данных используют методы сжатия?
Методы сжатия используются столбчатыми базами данных для снижения требований к хранилищу и повышения производительности запросов. Это достигается несколькими способами:
- Кодирование по словарю: этот метод использует словарь для хранения уникальных значений столбца и заменяет исходные значения более короткими кодами. Это приводит к уменьшению объема памяти, необходимого для хранения данных, особенно для столбцов с высокой кардинальностью.
- Кодирование длин серий. Этот метод сохраняет повторяющиеся значения в столбце как одну пару значений и счетчиков. Например, если столбец содержит 1000 последовательных значений «А», его можно сохранить как «А-1000». Этот метод особенно эффективен для столбцов с длинными сериями повторяющихся значений.
- Битовая упаковка: этот метод позволяет хранить несколько значений в одном машинном слове, уменьшая объем памяти, необходимый для хранения данных. Например, если столбец содержит логические значения, каждое значение может храниться как один бит, а не как полный байт.
- Дельта-кодирование: этот метод сохраняет разницу между соседними значениями в столбце вместо фактических значений. Это полезно для столбцов с последовательными данными, такими как даты или метки времени.
 Этот метод особенно эффективен для столбцов с длинными сериями повторяющихся значений.
Этот метод особенно эффективен для столбцов с длинными сериями повторяющихся значений.
Используя эти методы сжатия, столбцовые базы данных могут значительно снизить требования к хранилищу и повысить производительность запросов, что делает их хорошо подходящими для аналитических рабочих нагрузок.
Как столбцовые базы данных обеспечивают более высокую производительность запросов?
Столбчатые базы данных обеспечивают более высокую производительность запросов благодаря своей уникальной архитектуре хранения и обработки. Вместо того, чтобы хранить и обрабатывать данные по строкам, столбцовые базы данных хранят данные и управляют ими по столбцам. Этот метод способствует более эффективному поиску и обработке данных.
Вместо того, чтобы хранить и обрабатывать данные по строкам, столбцовые базы данных хранят данные и управляют ими по столбцам. Этот метод способствует более эффективному поиску и обработке данных.
В столбцовой базе данных из памяти извлекаются только определенные столбцы, необходимые для конкретного запроса, тогда как в построчной базе данных извлекаются целые строки данных. Столбчатые базы данных могут повысить производительность запросов, извлекая только релевантные данные и избегая нерелевантных данных. Это возможно благодаря тому, как данные организованы и управляются столбцами.
Кроме того, столбцовые базы данных используют расширенные методы сжатия, такие как кодирование длин серий, кодирование словаря и кодирование растровых изображений, которые могут значительно сократить объем памяти и повысить производительность запросов. Сжимая данные по столбцам, а не по строкам, столбцовые базы данных могут достигать более высоких коэффициентов сжатия и более быстрого извлечения данных.
Кроме того, столбцовые базы данных оптимизированы для параллельной обработки, что позволяет выполнять запросы одновременно на нескольких процессорных ядрах или узлах, что приводит к еще более высокой производительности запросов.
Популярные столбцовые базы данных, в том числе:
Apache Parquet
Apache Parquet — это формат хранения столбцов, разработанный для эффективного хранения и обработки больших наборов данных в распределенных вычислительных средах. Это формат файла с открытым исходным кодом, обеспечивающий высокооптимизированный и сжатый способ хранения структурированных данных.
Parquet совместим с различными платформами обработки данных, включая Hadoop, Apache Spark и Apache Arrow. Он основан на документе Google Dremel, в котором представлен столбчатый формат хранения для анализа крупномасштабных наборов данных.
Parquet предназначен для поддержки как сложных вложенных структур данных, так и высокопроизводительных выталкиваний предикатов для эффективной фильтрации данных во время выполнения запроса. Эта функция делает столбцовые базы данных идеальными для сценариев, связанных с хранением данных, бизнес-аналитикой и анализом данных.
Эта функция делает столбцовые базы данных идеальными для сценариев, связанных с хранением данных, бизнес-аналитикой и анализом данных.
Apache ORC
Apache ORC (Optimized Row Columnar) — формат столбцового хранилища с открытым исходным кодом, разработанный Hortonworks и позже принятый Apache Software Foundation. Он предназначен для хранения структурированных данных в сильно сжатом и оптимизированном виде, что делает его идеальным для обработки и анализа больших данных. ORC хранит данные в столбчатой конфигурации, что улучшает и ускоряет обработку и анализ данных. Он предлагает поддержку нескольких типов данных, включая сложные типы данных, такие как массивы, карты и структуры. ORC широко используется в средах обработки больших данных, таких как Apache Hadoop, Apache Spark и Apache Hive, для высокопроизводительной обработки и анализа данных.
Amazon Redshift
Amazon Redshift — это облачный сервис хранения данных от Amazon Web Services (AWS). Он предназначен для обработки крупномасштабных наборов данных и сложных запросов высокопроизводительным и экономичным способом. Amazon Redshift основан на архитектуре хранения данных по столбцам, что делает его хорошо подходящим для аналитических рабочих нагрузок и приложений для работы с большими данными.
Amazon Redshift основан на архитектуре хранения данных по столбцам, что делает его хорошо подходящим для аналитических рабочих нагрузок и приложений для работы с большими данными.
Google BigQuery
Google BigQuery — это хранилище данных корпоративного уровня, работающее в облачной инфраструктуре и позволяющее пользователям хранить и запрашивать обширные наборы данных с помощью языка, похожего на SQL. Он был создан Google и является частью набора инструментов Google Cloud Platform. BigQuery — это полностью управляемая служба, а это означает, что Google занимается всеми аспектами управления инфраструктурой, включая масштабирование, доступность и безопасность. Это позволяет пользователям сосредоточиться на запросах и анализе своих данных, а не беспокоиться о базовой инфраструктуре. BigQuery предназначен для крупномасштабной обработки данных и может использоваться для аналитики в реальном времени, машинного обучения и хранения данных.
Как FiveTran увеличивает скорость и гибкость передачи данных с помощью столбцовой базы данных?
FiveTran — это облачная платформа для интеграции данных, которая позволяет компаниям копировать данные из нескольких источников в свое облачное хранилище или хранилище данных.