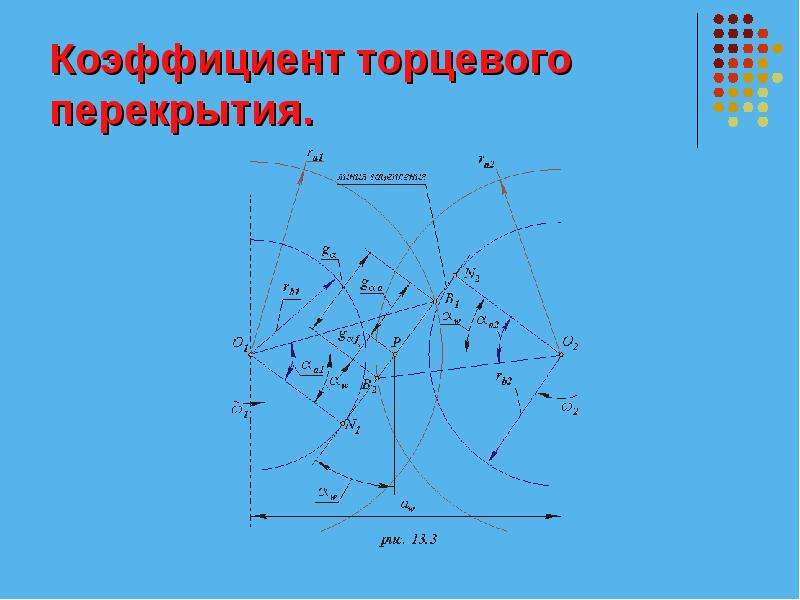
Коэффициент перекрытия: Коэффициент перекрытия косозубых передач — Лекции и примеры решения задач технической механики
Коэффициент перекрытия прямозубой передачи
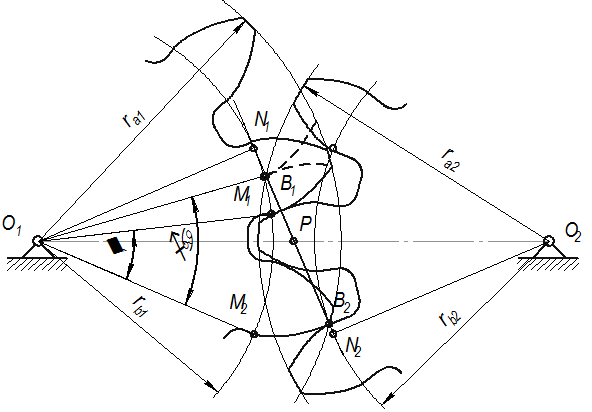
Начало контактов зубьев колес (рис.5.8), образующих зубчатую пару, происходит в момент, когда точка В1 зуба ведомого колеса, лежащая на окружности вершин, оказывается на линии зацеплени. Далее профиль ведущего зуба будет давить на профиль ведомого и скользить по нему до тех пор, пока зубья не выйдут из зацепления. Последняя точка В2 контакта зубьев располагается на пересечении линии зацепления с окружностью вершин ведущего колеса.
Отрезок линии зацепления В1В2, внутри которого происходит контакт сопряженных профилей зубьев, называется активным участком линии зацепления. Соответственно часть профиля зуба, точки которого последовательно контактируют с парным колесом, называется активным профилем. Он располагается между окружностью вершин и вспомогательной окружностью, проведенной из центра колеса через крайнюю точку активного участка линии зацепления.
|
Угол поворота колеса от положения, соответствующего входу зуба в зацепление, до положения, соответствующего выходу зуба из зацепления, называется углом перекрытия . Для прямозубых передач полный угол перекрытия равен углу торцового перекрытия , т.е. углу перекрытия в любом сечении, перпендикулярном оси колеса.
При работе зубчатых колес необходимо, чтобы в любой момент времени колеса находились в зацеплении.
Для этого требуется, чтобы угол перекрытия был больше углового шага, т.е. > . В противном случае пара зубьев выйдет из зацепления раньше, чем в
зацепление войдет следующая пара; причем это зацепление произойдет с ударом.
Отношение угла перекрытия к угловому шагу называется коэффициентом перекрытия:
.
Для прямозубых передач полный коэффициент перекрытия равен коэффициенту торцового перекрытия, т.е. коэффициенту перекрытия в торцовом сечении:
= В1В2 /(pm cosa) .
Коэффициент перекрытия характеризует плавность работы передачи. Чем больше этот коэффициент, тем плавнее, спокойнее работает передача; меньше шум, динамические нагрузки. Недопустимо, чтобы величина коэффициента перекрытия была меньше единицы.
При прочих равных условиях коэффициент перекрытия возрастает с увеличением числа зубьев колес (отрезок В1В2 увеличивается) и уменьшается с увеличением коэффициента суммы смещения колес (в этом случае активный участок В1В2 линии зацепления уменьшается).
Наибольший коэффициент торцового перекрытия соответствует фиктивному случаю зацепления двух реек: ( при
Читайте также:
Расчёт цилиндрического эвольвентного зубчатого зацепления (внешнего и внутреннего), оптимальный расчёт коэффициентов смещения — Kompas — блог
Расчёт цилиндрического эвольвентного зубчатого зацепления (внешнего и внутреннего), оптимальный расчёт коэффициентов смещения для прямозубого внешнего зацепления и расчёт профиля зуба.
Автором разработана программа позволяющая, производить указанные выше, вычисления. Она предназначена заменить, существующую на данный момент, программу для расчёта прямозубого зацепления (внешнего и внутреннего) http://www.chipmaker…les/file/12127/.
Программа и процесс по устранению ошибок и доводке её до нужных параметров, оказались очень даже не простыми, при возникновении сложных вопросов, я обращался за консультациями к Евгению (tmpr), я ему очень благодарен за оказанную помощь. Поэтому можно сказать, что получилась почти профессиональная программа, которая гарантирует высокую точность вычислений.
Для расчёта геометрии прямозубого внешнего зацепления, автор впервые ввёл понятие оптимального расчёта коэффициентов смещения.
Как известно, для расчёта шестерён с количеством зубьев более десяти и менее 16, без коэффициентов смещения никак не обойтись.
К расчёту эвольвентного зацепления предъявляется очень большое количество противоречивых требований:
1. Не должно быть подрезания ножки зуба;
Не должно быть подрезания ножки зуба;
2. Не должно быть интерференции зубьев;
3. Не должно быть заострения зубьев, т.е., толщина зуба на поверхности вершин не должна быть – Sa1, Sa2 < 0.3m;
4. Коэффициент перекрытия – Ea >1.0 , в литературе рекомендуется, чтобы коэффициент перекрытия был > 1.2.
5. Коэффициенты удельного скольжения должны быть близки друг к другу, а в лучшем случае равны, тогда износ зубьев будет относительно равномерным.
Всё это заложено в построении блокирующих контуров: см. ГОСТ- 16532-70 и ГОСТ – 19274-73, но, к сожалению, там приведены не все возможные случаи сочетания количества зубьев шестерён и колёс.
Автор попытался решить эту проблему с помощью компьютера, создать программу, которая позволяет производить оптимальный расчёт, с учётом указанных требований для прямозубого внешнего зацепления. Вручную эту работу сделать – невозможно.
Компьютеру приходится производить колоссальное количество вычислений при расчёте коэффициентов смещения X1 и X2.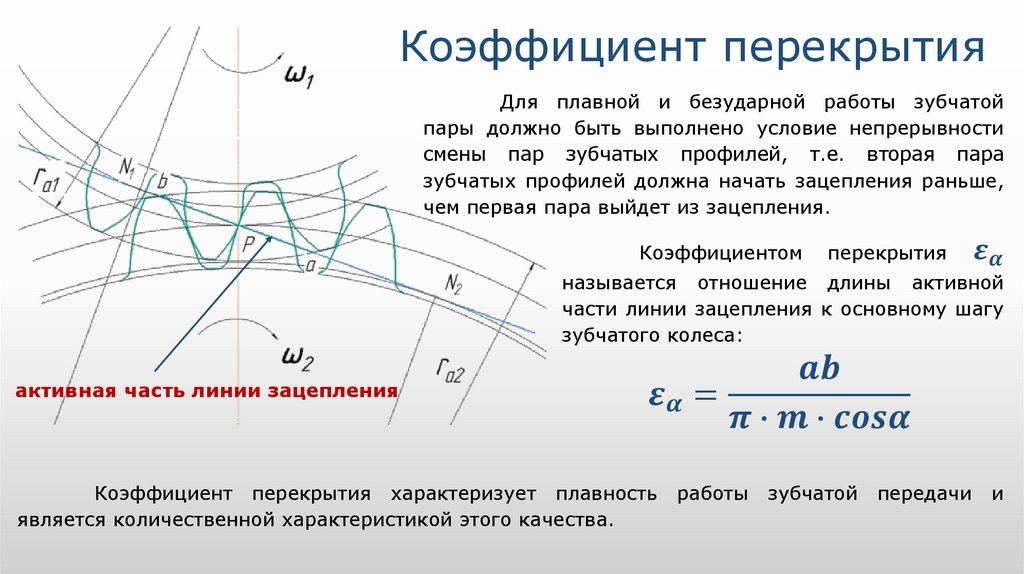
Например: при вычислении только одного угла зацепления, для достижения необходимой точности, требуется 5000 циклов, и все эти вычисления происходит до тех пор, пока все приведённые выше параметры не уложатся в заданный промежуток, удовлетворяющий всем требованиям к данному зубчатому зацеплению. На рисунке ниже, показан « оптимальный» расчёт внешнего эвольвентного зубчатого зацепления со смещением. Как видите, все выше перечисленные требования к зацеплению, выполняются.
А, вот тот же самый расчёт, выполненный программой, согласно ГОСТ-16532-70.
Коэффициент торцового перекрытия, в данном случае, уже не достигает оптимального Ea=1.2.
Разработанная программа позволяет рассчитать все данные для построения профиля зуба. Формулы для расчёта взяты из ГОСТ – 16532-70. Это позволило произвести построение профиля зубьев с высокой степенью точности. Ниже на рисунке показано построение зуба шестерни, эвольвентного зацепления, когда: Z1=11, Z2=25, m=5, x1=0.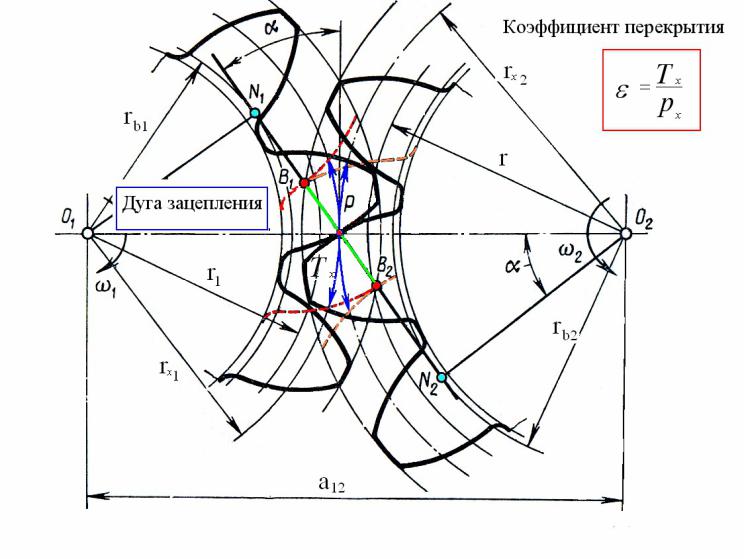 5, x2=0.5.
5, x2=0.5.
Метод построения профиля зуба по формулам с помощью программы, обеспечивает более точное его построение и как факт построение всего чертежа зацепления, чем графическое вычерчивание зубьев зацепления, как показано здесь:
Расчёт радиуса дуги переходной кривой равной 0,38m, программа рассчитывает для случаев, когда радиус основной окружности rb1 и rb2 больше радиуса впадин rf1 и rf2, для случая когда rf1 или rf2 > rb1 или rb2, автор не сумел составить и решить уравнения для расчёта переходной кривой, но если кто то сумеет решить эту задачу, я буду очень благодарен и внесу изменения в программу. На данный момент программа выдаёт результат «нет решения» и поэтому в данном случае конструктору придётся решать эту задачу графически, а не аналитически с помощью программы.
Точность построения чертежа подтверждается снятием размеров непосредственно с чертежа: количество зубьев в общей нормали шестерни и колеса, а также длина общей нормали, соответствуют расчётным.
Программа расположена по адресу:
Коэффициент торцового перекрытия — fiziku5.ru
(84)
(85)
Расстояние между центрами колёс называется межцентровым расстоянием
(86)
Расстояние между одноименными точками двух соседних зубьев измеренное по делительной окружности, называется шагом зубчатого колеса по делительной окружности
. (87)
Толщина зуба s и ширина впадины e по делительной окружности равны
(88)
Диаметр основной окружности колеса
(89)
шаг по основной окружности
(90)
Диаметр начальной окружности колеса dw, нарезанного без смещения инструментальной рейки равен диаметру делительной окружности d.
В случае зацепления двух колёс, нарезанных со смещениями x1 и x2 инструментальной рейки, угол зацепления определяется по формуле
(91)
В этом случае диаметр начальной окружности определяют по формуле
(92)
а начальное межосевое расстояние – по формуле
(93)
6. 7. Коэффициент торцового перекрытия
7. Коэффициент торцового перекрытия
Коэффициент торцового перекрытия учитывает непрерывность и плавность зацепления в передаче. Эти качества передачи обеспечиваются перекрытием работы одной пары зубьев работой другой пары. Для этого каждая последующая пара зубьев должна войти в зацепление ещё до того, как предшествующая пара выйдет из зацепления. О величине перекрытия судят по
(94)
здесь τ1=2π/z1 – угловой шаг шестерни, а τ2=2π/z2 – колеса.
Коэффициент торцового перекрытия для прямозубой цилиндрической передачи можно определять по следующей формуле:
(95)
Знак плюс в (92) соответствует внешнему зацеплению, а знак минус – внутреннему.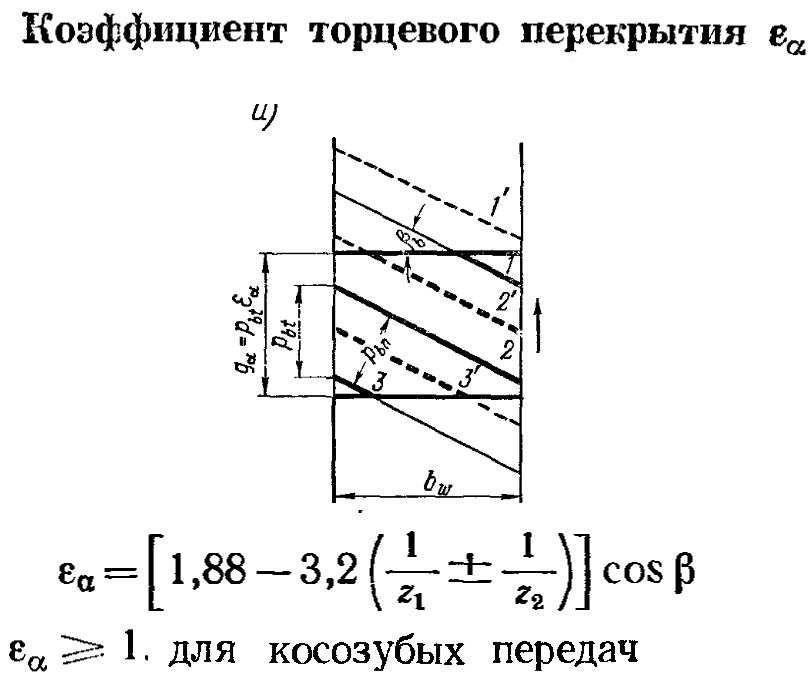
Для обеспечения непрерывности вращения рекомендуется εα >1,2. Обычно в прямозубых цилиндрических передачах εα=1,2…1,8.
Начальное межосевое расстояние аw, угол зацепления αw, передаточное число i и коэффициент торцового перекрытия εα являются основными параметрами зацепления.
6.8. Материалы зубчатых колёс
Определяющими факторами при выборе материала зубчатых колёс являются:
– режим работы передачи: степень нагруженности, окружная скорость;-
– габаритные и массовые требования;
– экономические соображения.
Наиболее распространёнными материалами зубчатых колёс силовых передач являются углеродистые стали.
Для цилиндрических и конических колёс, работающих с небольшими окружными скоростями (до 3 м/с), обычно применяют качественные конструкционные стали 20…35, при повышенных скоростях – стали 45. 50 и легированные стали 20Х, 40Х, 12ХН3А. Повышение долговечности зубчатых передач может быть достигнуто, если зубья малого колеса (шестерни), нагружаемые чаще, выполнить с более высокой твёрдостью рабочих поверхностей по сравнению со вторым колесом. С этой целью для изготовления шестерни выбирают более качественный материал или предусматривают упрочнение зубьев.
Повышение долговечности зубчатых передач может быть достигнуто, если зубья малого колеса (шестерни), нагружаемые чаще, выполнить с более высокой твёрдостью рабочих поверхностей по сравнению со вторым колесом. С этой целью для изготовления шестерни выбирают более качественный материал или предусматривают упрочнение зубьев.
В малонагруженных мелкомодульных передачах прочность зубьев не является определяющим фактором и почти всегда обеспечена с большим запасом. В таких передачах материалы колёс выбирают исходя из минимального износа зубьев. Из этих соображений шестерни изготовляют из углеродистых сталей (35, 45, 50, У8А, У10А) или легированных сталей (40Х, 12ХН3А и др.), а колёса – из цветных металлов и сплавов (бронза БрОЦС6-6-3, БрАЖ9-4), латуни (ЛС59-1) и др.
Вопросы для самопроверки
1. Для чего применяют передаточные механизмы? Виды передаточных механизмов, их основные внешние характеристики.
2. Зубчатые механизмы (передачи), область применения, достоинства и недостатки.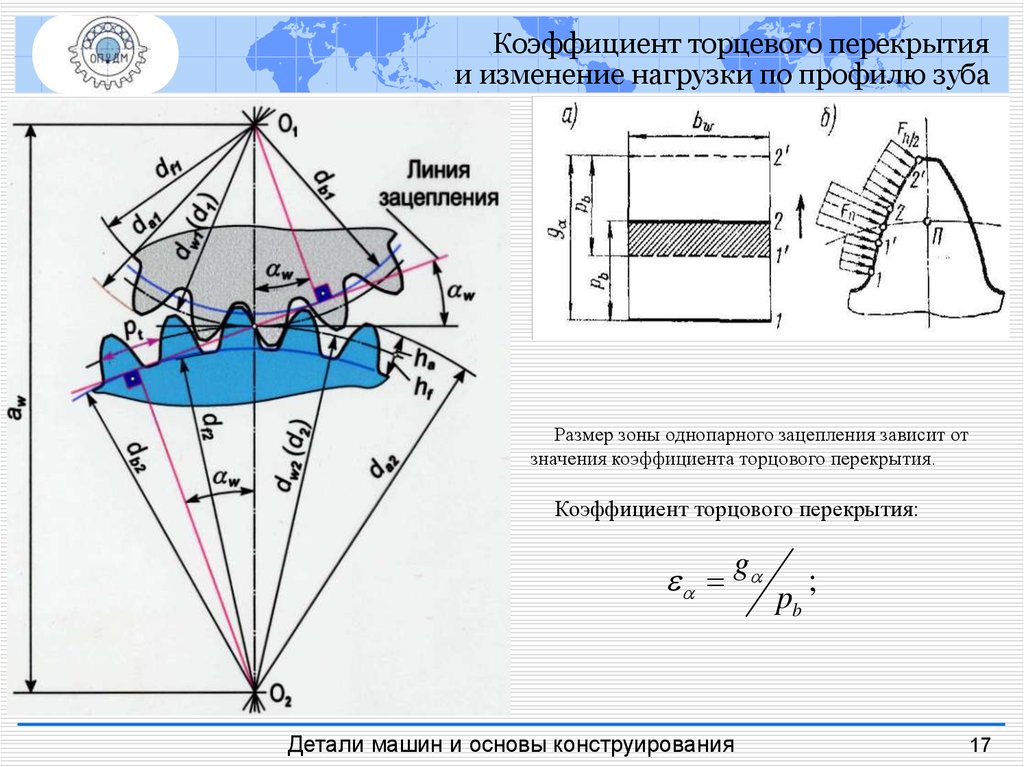
3. Как классифицируются зубчатые передачи по геометрическим и функциональным особенностям?
4. Назовите основные, на Ваш взгляд, пять основных требований, которые должны быть предъявлены к зубчатым передачам.
5. Сформулируйте основной закон зацепления. Какие кривые называют сопряжёнными?
6. Эвольвента окружности и её свойства. Уравнения эвольвенты в полярных координатах.
7. Покажите, что передаточное отношение зубчатой передачи с эвольвентным профилем зубьев величина постоянна. Что такое полюс зацепления, линия зацепления и угол зацепления?
8. Геометрические параметры эвольвентных прямозубых передач.
Заключение
При изучении данного курса студенты при необходимости смогут производить не сложные предварительные прочностные расчёты различных соединений (сварных, заклёпочных резьбовых, шпоночных, шлицевых и др.) деталей; сделать статический расчёт вала (оси) на прочность и жёсткость, производить необходимые расчёты и конструктивные разработки для улучшения производственных процессов. В первую очередь, это касается модернизации швейного оборудования, разработки средств механизации и автоматизации. Полученные знания позволят правильно оценивать действительные возможности машин, грамотно их эксплуатировать и совместно с другими специалистами создавать новую технику с целью повышения производительности труда.
В первую очередь, это касается модернизации швейного оборудования, разработки средств механизации и автоматизации. Полученные знания позволят правильно оценивать действительные возможности машин, грамотно их эксплуатировать и совместно с другими специалистами создавать новую технику с целью повышения производительности труда.
Библиографический список
1. Тарг, С. М. Краткий курс теоретической механики; М.: Высшая школа, 1995, − 416 с.
2. Теория механизмов и машин:Учеб. для втузов /под ред. К. В.Фролова.- М.: Высш. шк., 1987. — 496 с.: ил.
3. Семин, М. И. Основы сопротивления материалов : учеб. пособие для студентов вузов / М. И. Семин. – М. : Гуманитар. изд. центр ВЛАДОС, 2004. – 255 с.
5 Прикладная механика,: учебник для вузов / В. В. Джамай, Ю. Н. Дроздов, Е. А. Самойлов и др. ; под общ. ред. В. В. Джамая. – М. : Дрофа, 2004. – 414 с.
6. Иванов, С. Г. Теория механизмов и машин. Пособие к курсу и контрольной работе Омск, ОГИСа, 2003. — 54с.
— 54с.
7. Девятов С. А. Теоретическая механика : учебное пособие. – Омск ; ОГИС, 2008. – 116 с
8. Иванов, С. Г. Детали машин и основы конструирования : Учебное пособие. — Омск : ОГИС, 2006. 149 с.
9. Иванов, С. Г. Основы функционирования систем сервиса (раздел «Сопротивление материалов»): Учебное пособие. — Омск : ОГИС, 2010. — 95 с.
СОДЕРЖАНИЕ
Коэффициент перекрытия
Коэффициент перекрытияКоэффициентом перекрытия называется отношение длины активной линии зацепления к основному шагу зубчатого колеса, он обозначается и определяется отношением
.
Передача движения в зубчатом зацеплении происходит таким образом, что, прежде чем предыдущая пара зубьев выйдет из зацепления (из контакта), последующая должна войти в зацепление (в контакт). Чем раньше она вступит в зацепление, тем более плавно работает передача. Количественной характеристикой этого качества и является коэффициент перекрытия, т.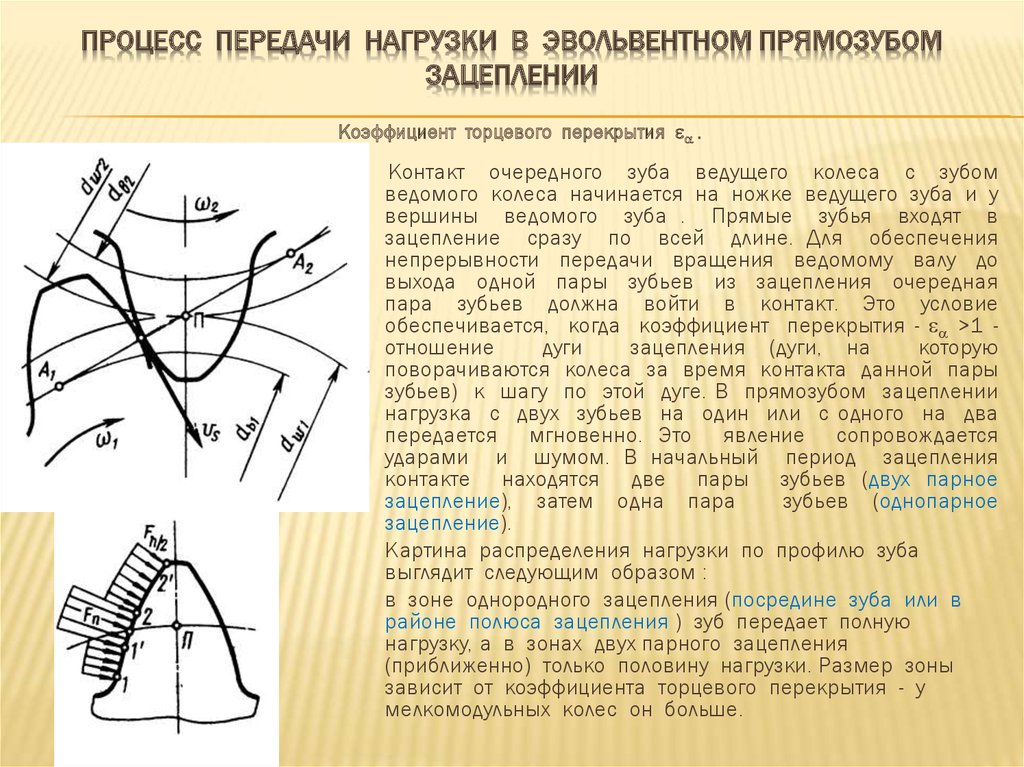 е. он, по существу, характеризует плавность работы зубчатой передачи. Обычно величина коэффициента перекрытия заключена между 1 и 2, при этом минимальное значение не должно быть меньше 1,1. Схематически соотношение между длиной активной лини зацепления и основным шагом показано на рис. 3.12. Точка контакта профилей зубьев перемещается вдоль активной линии зацепления от точки H1 к точке H2. Основной шаг короче активной линии зацепления, поэтому в пределах этой линии работают то одна, то две пары зубьев. Если отложить, как показано на рис. 3.12, основной шаг pb от точек H1 и H2, то отрезок H1H2 будет разделён на три части. Две крайние части соответствуют зонам двухпарного зацепления зубьев, а средняя – зоне однопарного зацепления. Чем короче средняя зона, тем плавнее работает зубчатая передача, так как суммарная длина двух крайних участков становится длиннее.
е. он, по существу, характеризует плавность работы зубчатой передачи. Обычно величина коэффициента перекрытия заключена между 1 и 2, при этом минимальное значение не должно быть меньше 1,1. Схематически соотношение между длиной активной лини зацепления и основным шагом показано на рис. 3.12. Точка контакта профилей зубьев перемещается вдоль активной линии зацепления от точки H1 к точке H2. Основной шаг короче активной линии зацепления, поэтому в пределах этой линии работают то одна, то две пары зубьев. Если отложить, как показано на рис. 3.12, основной шаг pb от точек H1 и H2, то отрезок H1H2 будет разделён на три части. Две крайние части соответствуют зонам двухпарного зацепления зубьев, а средняя – зоне однопарного зацепления. Чем короче средняя зона, тем плавнее работает зубчатая передача, так как суммарная длина двух крайних участков становится длиннее.
Дата добавления: 2015-07-08; просмотров: 209 | Нарушение авторских прав
Читайте в этой же книге: Механизм с рядовым соединением колес | Типовая схема эпициклического механизма | Аналитический расчет кинематики | Графический расчет кинематики | Основной закон зацепления | Уравнение эвольвенты | Элементы зубчатого колеса | Элементы и свойства эвольвентного зацепления | Методы изготовления | Геометрия реечного производящего исходного контура |
mybiblioteka.
 su — 2015-2020 год. (0.008 сек.)
su — 2015-2020 год. (0.008 сек.)| Каталоги комплексных поставщиков для предприятий и служб сервиса / Catalogues of one-stop shop suppliers HOFFMANN GROUP | Справочник HOFFMANN GROUP 2012 Обработка резанием Garant (Всего 1091 стр.) | ||||||||
1060 Справочник HOFFMANN GROUP 2012 Обработка материалов резанием Garant ToolScout Стр.1036 | ||||||||
Волнистость шлифовального круга ( шаг резьбы ) определяется через коэффициент перекрытия Ud. Коэффициент перекрытия рассчитывается на основе количества оборотом шлифовального круга во время смещения правящего инструмента (подача при правке fad) на его рабочую ширину bd. При увеличении коэффициента перекрытия волнистость поверхности шлифовального круга уменьшается и шлифовальный круг становится более гладким, что, в свою очередь, ведет к уменьшению эффективной высоты микронеровностей Rth. | ||||||||
См.  также / See also : также / See also : | ||||||||
Соотношение твердостей Таблица / Hardness equivalent table | Аналоги марок стали / Workpiece material conversion table | |||||||
Отклонение размера детали / Fit tolerance table | Перевод оборотов в скорость / Surface speed to RPM conversion | |||||||
Диаметр под резьбу / Tap drill sizes | Виды резьбы в машиностроении / Thread types and applications | |||||||
Дюймы в мм Таблица / Inches to mm Conversion table | Современные инструментальные материалы / Cutting tool materials | |||||||
Справочник HOFFMANN GROUP 2012 Обработка резанием Garant (Всего 1091 стр. ) ) | ||||||||
| | 1057 Выбор и рекомендации по использованию неподвижного правящего инструмента Выбор однокристальных правящих инструментов и алмазно-металлическ | 1058 | 1059 | 1061 | 1062 | 1063 | ||
| Справочники по резанию и каталоги инструмента HOFFMANN GROUP | ||||||||
| | ||||||||
Каталог HOFFMANN GROUP 2020 Режущий и вспомогательный инструмент для станков (1098 страниц) | Каталог HOFFMANN GROUP 2020 Измерительный и ручной инструмент Инвентарь (1194 страницы) | Каталог HOFFMANN GROUP 2020 Промышленная мебель и складское оборудование (666 страниц) | Каталог HOFFMANN GROUP 2020 Средства индивидуальной защиты (англ.яз / ENG) (442 страницы) | Каталог HOFFMANN GROUP 2018 Инструмент вспомогательный и режущий (1034 страницы) | Каталог HOFFMANN GROUP 2018 Инструмент Приборы Инвентарь (1162 страницы) | |||
Каталог HOFFMANN GROUP 2017 Вспомогательный и режущий инструмент (998 страниц) | Каталог HOFFMANN GROUP 2017 Ручной и измерительный инструмент (1126 страниц) | Каталог HOFFMANN GROUP 2017 Производственная мебель и системы хранения (624 страницы) | Каталог HOFFMANN GROUP 2016 Станочный режущий инструмент и оснастка (англ.  яз / ENG) яз / ENG)(934 страницы) | Каталог HOFFMANN GROUP 2016 Слесарно- монтажный и мерительный инструмент (англ.яз / ENG) (1094 страницы) | Каталог HOFFMANN GROUP 2016 Производственная мебель (англ.яз / ENG) (562 страницы) | |||
Каталог HOFFMANN GROUP 2016 Режущий инструмент и оснастка (нем.яз / DEU) (932 страницы) | Каталог HOFFMANN GROUP 2016 Ручной и измерительный инструмент (нем.яз / DEU) (1094 страницы) | Справочник HOFFMANN GROUP 2016 Режимы резания для режущего инструмента (EN DE ES IT FR) (904 страницы) | Каталог HOFFMANN GROUP 2015 Инструмент Оборудование Инвентарь (1643 страницы) | Каталог HOFFMANN GROUP 2015 Производственная мебель (459 страниц) | Справочник HOFFMANN GROUP 2012 Обработка резанием Garant (1091 страница) | |||
Каталоги комплексных поставщиков для предприятий и служб сервиса / | ||||||||
— — | ||||||||
 Ud Коэффициент перекрытия (уравн. 11.48) bd Рабочая ширина мм fad Осевая подача мм nsd Частота вращения шлифовального круга при правке об/мин Vfad Скорость осевой подачи мм/мин и f = fad nsd bd fad Коэффициент перекрытия Ud Грубое шлифование (черновая обработка) 2-3 Нормальное шлифование (обработка средней чистоты) 4-6 Тонкое шлифование (чистовая обработка) > 7 Таблица 11.15 Ориентировочные значения для коэффициента перекрытия при правке Рис. 11.28 Зависимость между коэффициентом перекрытия и волнистостью шлифовального круга Коэфф. перекрытия Волнистость Поверх. шлиф. круга Производит. резания Поверхность детали Опасность прижога и трещин на теплочувствительных деталях высокая слабая гладкая низкая чистая повышенная низкий сильная шероховатая высокая грубая низкая Таблица 11.16 Зависимости при структурировании поверхностей шлифовальных кругов 1036 Коэффициент перекрытия Ud
Ud Коэффициент перекрытия (уравн. 11.48) bd Рабочая ширина мм fad Осевая подача мм nsd Частота вращения шлифовального круга при правке об/мин Vfad Скорость осевой подачи мм/мин и f = fad nsd bd fad Коэффициент перекрытия Ud Грубое шлифование (черновая обработка) 2-3 Нормальное шлифование (обработка средней чистоты) 4-6 Тонкое шлифование (чистовая обработка) > 7 Таблица 11.15 Ориентировочные значения для коэффициента перекрытия при правке Рис. 11.28 Зависимость между коэффициентом перекрытия и волнистостью шлифовального круга Коэфф. перекрытия Волнистость Поверх. шлиф. круга Производит. резания Поверхность детали Опасность прижога и трещин на теплочувствительных деталях высокая слабая гладкая низкая чистая повышенная низкий сильная шероховатая высокая грубая низкая Таблица 11.16 Зависимости при структурировании поверхностей шлифовальных кругов 1036 Коэффициент перекрытия Udкоэффициент перекрытия зуба 🎓 ⚗ перевод с английского на русский
Все языкиАбхазскийАдыгейскийАзербайджанскийАймараАйнский языкАканАлбанскийАлтайскийАнглийскийАрабскийАрагонскийАрмянскийАрумынскийАстурийскийАфрикаансБагобоБаскскийБашкирскийБелорусскийБолгарскийБретонскийБурятскийВаллийскийВарайскийВенгерскийВепсскийВерхнелужицкийВьетнамскийГаитянскийГреческийГрузинскийГуараниГэльскийДатскийДолганскийДревнерусский языкИвритИдишИнгушскийИндонезийскийИнупиакИрландскийИсландскийИспанскийИтальянскийЙорубаКазахскийКарачаевскийКаталанскийКвеньяКечуаКиргизскийКитайскийКлингонскийКомиКорейскийКриКрымскотатарскийКумыкскийКурдскийКхмерскийЛатинскийЛатышскийЛингалаЛитовскийЛожбанЛюксембургскийМайяМакедонскийМалайскийМаньчжурскийМаориМарийскийМикенскийМокшанскийМонгольскийНауатльНемецкийНидерландскийНогайскийНорвежскийОрокскийОсетинскийОсманскийПалиПапьяментоПенджабскийПерсидскийПольскийПортугальскийРумынский, МолдавскийРусскийСанскритСеверносаамскийСербскийСефардскийСилезскийСловацкийСловенскийСуахилиТагальскийТаджикскийТайскийТатарскийТвиТибетскийТофаларскийТувинскийТурецкийТуркменскийУдмурдскийУзбекскийУйгурскийУкраинскийУрдуУрумскийФарерскийФинскийФранцузскийХиндиХорватскийЦерковнославянский (Старославянский)ЧеркесскийЧерокиЧеченскийЧешскийЧувашскийШайенскогоШведскийШорскийШумерскийЭвенкийскийЭльзасскийЭрзянскийЭсперантоЭстонскийЮпийскийЯкутскийЯпонский
Все языкиАзербайджанскийАлбанскийАрабскийАрмянскийАфрикаансБаскскийБолгарскийВенгерскийВьетнамскийГаитянскийГреческийГрузинскийДатскийДревнерусский языкИвритИндонезийскийИрландскийИсландскийИспанскийИтальянскийЙорубаКазахскийКаталанскийКвеньяКитайскийКлингонскийКорейскийКурдскийЛатинскийЛатышскийЛитовскийМакедонскийМалайскийМальтийскийМаориМарийскийМокшанскийМонгольскийНемецкийНидерландскийПалиПапьяментоПерсидскийПольскийПортугальскийРумынский, МолдавскийРусскийСербскийСловацкийСловенскийСуахилиТагальскийТайскийТамильскийТатарскийТурецкийУдмурдскийУйгурскийУкраинскийУрдуФарерскийФинскийФранцузскийХиндиХорватскийЦерковнославянский (Старославянский)ЧаморроЧерокиЧешскийЧувашскийШведскийЭрзянскийЭстонскийЯпонский
tool. overlap function | R Документация
overlap function | R Документация
 overlap function | R Документация
overlap function | R Документация Вычислить перекрытия между группами указанных элементов
tool.overlap проверяет каждую пару блоков, находит количество общих
items и получает значения значимости разделения для пар блоков.
Использование
tool.overlap (items, groups, nbackground = NULL)
Аргументы
- предметы
- массив идентификаторов товаров
- группы
- массив групповых идентификаторов для товаров
- n фон
- общее количество позиций
Значение
- A
- название группы
- B
- название группы
- POSa
- ранг названия группы
- POSb
- ранг названия группы
- Na
- размер группы A
- Nb
- размер группы B
- Nab
- общие элементы
- R
- коэффициент перекрытия
- F
- кратное изменение до нулевого ожидания
- P
- перекрытие P-значение (тест Фишера)
Псевдонимы
Примеры
## в качестве примера прочтите файл модуля coexpr:
moddata <- инструмент. читать (system.file ("extdata",
"modules.mousecoexpr.liver.human.txt", package = "Mergeomics"))
## найдем коэффициент перекрытия двух модулей:
## выбираем первый и последний модули:
mod.names <- unique (moddata $ MODULE) [c (1, length (unique (moddata $ MODULE)))]
if (length (mod.names)> 0) {
modA.members <- moddata [which (moddata $ MODULE == mod.names [1]),]
modB.members <- moddata [which (moddata $ MODULE == mod.names [2]),]
}
mod.pool <- rbind (modA.members, modB.members)
overlap.stats <- tool.overlap (мод.бассейн [, 2], mod.pool [, 1])
Документация воспроизведена из пакета Mergeomics, версия 1.0.0,
Лицензия: GPL (> = 2)  читать (system.file ("extdata",
"modules.mousecoexpr.liver.human.txt", package = "Mergeomics"))
## найдем коэффициент перекрытия двух модулей:
## выбираем первый и последний модули:
mod.names <- unique (moddata $ MODULE) [c (1, length (unique (moddata $ MODULE)))]
if (length (mod.names)> 0) {
modA.members <- moddata [which (moddata $ MODULE == mod.names [1]),]
modB.members <- moddata [which (moddata $ MODULE == mod.names [2]),]
}
mod.pool <- rbind (modA.members, modB.members)
overlap.stats <- tool.overlap (мод.бассейн [, 2], mod.pool [, 1])
читать (system.file ("extdata",
"modules.mousecoexpr.liver.human.txt", package = "Mergeomics"))
## найдем коэффициент перекрытия двух модулей:
## выбираем первый и последний модули:
mod.names <- unique (moddata $ MODULE) [c (1, length (unique (moddata $ MODULE)))]
if (length (mod.names)> 0) {
modA.members <- moddata [which (moddata $ MODULE == mod.names [1]),]
modB.members <- moddata [which (moddata $ MODULE == mod.names [2]),]
}
mod.pool <- rbind (modA.members, modB.members)
overlap.stats <- tool.overlap (мод.бассейн [, 2], mod.pool [, 1])
Примеры сообщества
Похоже, примеров пока нет.
определение, формула, нормы и ограничения
Коэффициент текущей ликвидности Определение
Коэффициент текущей ликвидности является балансовым показателем финансовых показателей ликвидности компании.
Коэффициент текущей ликвидности указывает на способность компании выполнять краткосрочные долговые обязательства. Коэффициент текущей ликвидности определяет, достаточно ли у фирмы ресурсов для выплаты своих долгов в течение следующих 12 месяцев. Потенциальные кредиторы используют этот коэффициент при принятии решения о выдаче краткосрочных ссуд. Коэффициент текущей ликвидности также может дать представление об эффективности операционного цикла компании или ее способности превращать свой продукт в наличные. Коэффициент текущей ликвидности также известен как коэффициент оборотного капитала .
Расчет (формула)
Коэффициент текущей ликвидности рассчитывается путем деления оборотных активов на краткосрочные обязательства:
Коэффициент текущей ликвидности = оборотные активы / текущие обязательства.
Обе переменные показаны в балансе (отчете о финансовом положении).
Нормы и ограничения
Чем выше коэффициент, тем более ликвидна компания.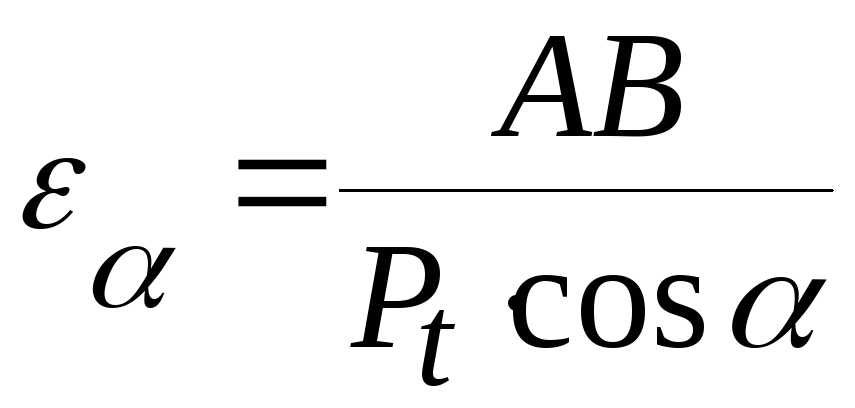 Обычно приемлемый коэффициент текущей ликвидности - 2; это удобное финансовое положение для большинства предприятий.Приемлемые текущие коэффициенты варьируются от отрасли к отрасли. Для большинства промышленных компаний коэффициент текущей ликвидности 1,5 может быть приемлемым.
Обычно приемлемый коэффициент текущей ликвидности - 2; это удобное финансовое положение для большинства предприятий.Приемлемые текущие коэффициенты варьируются от отрасли к отрасли. Для большинства промышленных компаний коэффициент текущей ликвидности 1,5 может быть приемлемым.
Низкие значения коэффициента текущей ликвидности (значения менее 1) указывают на то, что у фирмы могут возникнуть трудности с выполнением текущих обязательств. Однако инвестор также должен учитывать операционный денежный поток компании, чтобы лучше понять ее ликвидность. Низкий коэффициент текущей ликвидности часто может поддерживаться сильным операционным денежным потоком.
Если коэффициент текущей ликвидности слишком высок (намного больше 2), значит, компания может неэффективно использовать свои оборотные активы или средства краткосрочного финансирования.Это также может указывать на проблемы в управлении оборотным капиталом.
При прочих равных условиях кредиторы считают, что высокий коэффициент текущей ликвидности лучше, чем низкий коэффициент текущей ликвидности, потому что высокий коэффициент текущей ликвидности означает, что компания с большей вероятностью выполнит свои обязательства, которые подлежат погашению в течение следующих 12 месяцев.
Точная формула в аналитическом программном обеспечении ReadyRatios
Коэффициент текущей ликвидности = F1 [CurrentAssets] / F1 [CurrentLiabilities]
F1 - Отчет о финансовом положении (МСФО).
Коэффициент текущей ликвидности Отраслевой эталон
Средние значения коэффициента вы можете найти в нашем справочнике по отраслевому сравнительному анализу - Коэффициент текущей ликвидности.
Шкала интервалови шкала соотношения: в чем разница?
Шкала интервалов и шкала отношений представляют собой шкалы переменных измерений. Они предлагают количественное определение переменных атрибутов.
Разница между шкалами интервалов и соотношений связана с их способностью опускаться ниже нуля.Шкалы интервалов не содержат истинного нуля и могут представлять значения ниже нуля. Например, вы можете измерить температуру ниже 0 градусов Цельсия, например -10 градусов.
С другой стороны, переменные отношения никогда не опускаются ниже нуля. Рост и вес измеряются от 0 и выше, но никогда не опускаются ниже него.
Рост и вес измеряются от 0 и выше, но никогда не опускаются ниже него.
Интервальная шкала позволяет измерять все количественные атрибуты. Любое измерение шкалы интервалов может быть ранжировано, подсчитано, вычтено или добавлено, и равные интервалы разделяют каждое число на шкале.Однако эти измерения не дают никакого представления о соотношении между собой.
Шкала отношений имеет те же свойства, что и шкалы интервалов. Вы можете использовать его для сложения, вычитания или подсчета измерений. Шкалы отношения различаются наличием символа происхождения, который является начальной или нулевой точкой шкалы.
Соотношение интервалов Сравнение масштабов
Измерение температуры - отличный пример интервальных шкал. Температура в помещении с кондиционером составляет 16 градусов по Цельсию, а температура за пределами помещения - 32 градуса по Цельсию.Можно сделать вывод, что температура на улице на 16 градусов выше, чем внутри помещения.
Но если бы вы сказали: «На улице в два раза жарче, чем внутри», вы ошиблись бы. Указав, что температура снаружи вдвое выше, чем внутри, вы используете 0 градусов в качестве точки отсчета для сравнения двух температур. Поскольку можно измерить температуру ниже 0 градусов, вы не можете использовать ее в качестве ориентира для сравнения. Вместо этого вы должны использовать фактическое число (например, 16 градусов).
Интервальные переменные обычно называются масштабируемыми переменными.Они часто выражаются в виде единиц, например, градусов. В статистике среднее значение, режим и медиана также могут определять интервальные переменные.
Масштаб отношения отображает порядок и количество объектов между значениями шкалы. Ноль - это вариант. Эта шкала позволяет исследователю применять статистические методы, такие как геометрическое и гармоническое среднее.
Если вы не можете подразумевать, что температура на улице вдвое теплее, потому что это интервальная шкала, вы можете сказать, что вы вдвое старше другого, потому что это переменная отношения.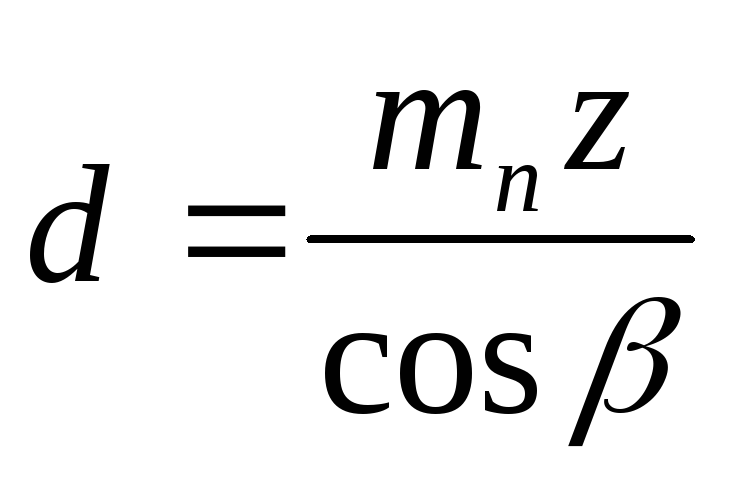
Возраст, деньги и вес являются общими переменными шкалы отношения. Например, если вам 50 лет, а вашему ребенку 25 лет, вы можете точно указать, что вы вдвое старше его.
Соотношение интервалов Масштаб измерений
Понимание различных шкал измерения позволяет вам видеть различные типы данных, которые вы можете собрать. Эти различия помогут вам определить тип статистического анализа, необходимый для вашего исследования.
Вот краткое описание разницы в интервале и уровнях отношения измерения:
Интервальный уровень измерения классифицирует и упорядочивает измерение.Он определяет расстояние между каждым интервалом эквивалентной шкалы, от нижнего интервала до верхнего интервала. Например, разница между 90 градусами по Фаренгейту и 100 градусами по Фаренгейту такая же, как 110 градусов по Фаренгейту и 120 градусов по Фаренгейту.
В дополнение к тому же качеству, что и уровни интервалов, уровни отношения могут иметь нулевое значение. Разница в стоимости между двумя парами обуви, которые составляют 10 и 20 долларов соответственно, такая же, как между двумя парами, которые составляют 20 и 30 долларов.Однако вы не найдете туфли дешевле 0 долларов.
Разница в стоимости между двумя парами обуви, которые составляют 10 и 20 долларов соответственно, такая же, как между двумя парами, которые составляют 20 и 30 долларов.Однако вы не найдете туфли дешевле 0 долларов.
Шкала интервалов по шкале соотношений: точки различия
| Характеристики | Интервальная шкала | Масштаб отношения |
| Переменное свойство | Все переменные, измеренные в интервальной шкале, можно складывать, вычитать и умножать. Вы не можете рассчитать соотношение между ними. | Масштаб отношения имеет все характеристики интервальной шкалы, кроме того, он позволяет вычислять отношения. То есть вы можете использовать цифры на шкале против 0. |
| Абсолютная нулевая точка | Нулевая точка на интервальной шкале произвольна. Например, температура может быть ниже 0 градусов по Цельсию и иметь отрицательные значения. | Шкала отношения имеет абсолютный ноль или знак происхождения. Рост и вес не могут быть нулевыми или ниже нуля. |
| Расчет | Статистически в интервальной шкале вычисляется среднее арифметическое. | Статистически в шкале соотношений вычисляется среднее геометрическое или гармоническое. |
| Измерение | Интервальная шкала может измерять размер и величину как несколько коэффициентов определенной единицы. | Шкала отношения может измерять размер и величину как коэффициент одной определенной единицы по отношению к другой. |
| Пример | Классическим примером интервальной шкалы является температура в градусах Цельсия.Разница в температуре между 50 и 60 градусами составляет 10 градусов; это такая же разница между 70 градусами и 80 градусами. | Классическими примерами шкалы соотношений являются любые переменные, которые обладают характеристиками абсолютного нуля, такими как возраст, вес, рост или показатели продаж. |
Создать бесплатный счет
Доверительный интервал Отношение рисков Отношение шансов Отношение ставок
Рабочий пример II
В нашем втором примере используются результаты поперечного исследования распространенности дистоции у кошек.Ранее мы рассматривали эту работу в отношении доверительных интервалов, связанных с оценками распространенности. Мы рассчитаем как отношение шансов (используемое авторами), так и отношение рисков с соответствующими интервалами.
| |||||
 55
55В этом случае один из размеров выборки мал, а одна из пропорций мала. Следовательно, вычисленный ниже интервал Вальда может быть ненадежным, поэтому нам лучше также вычислить условный точный интервал, используя функцию отношения шансов эпитулов для R:
Использование
| |||||||||||||
Для отношения шансов в R мы получаем то же самое для интервала Вальда (OR = 15,69, 95% CI от 1,55 до 158,60), но условный точный интервал перекрывает 1 (OR = 15.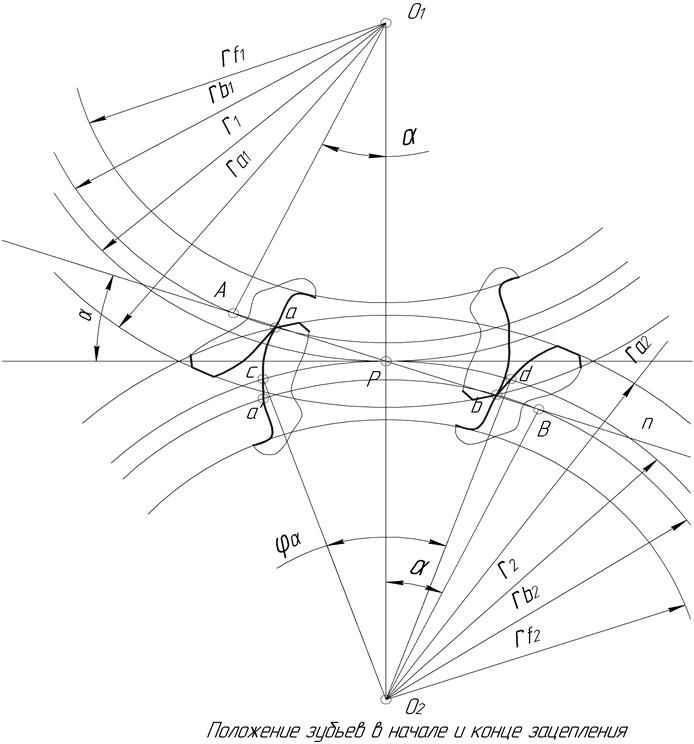 48, 95% ДИ от 0,28 до 204,67), как и (более надежный) средний интервал P (OR = 16,77, 95% ДИ от 0,56 до 153,09). Следовательно, сейчас очень сомнительно, действительно ли мы продемонстрировали, что существует какая-либо разница между породами.
48, 95% ДИ от 0,28 до 204,67), как и (более надежный) средний интервал P (OR = 16,77, 95% ДИ от 0,56 до 153,09). Следовательно, сейчас очень сомнительно, действительно ли мы продемонстрировали, что существует какая-либо разница между породами.
Для отношения рисков мы получили отношение рисков 14,87 с интервалом Вальда от 1,62 до 136,2, то же самое, что дает функция riskratio пакета epitool для доверительного интервала нормального приближения (Вальда). Используя ту же R-функцию, нормальное приближение Вальда с небольшой поправкой на выборку дало коэффициент риска 11.17 с интервалом от 1,22 до 102,25. Однако точное среднее значение P было 0,0876, что несколько выше обычного уровня 0,05.
Использование
1. Введение 2. Основная информация
3. Скачать и общие примечания
4. Справочная таблица команд
5. Базовое использование / форматы данных
6. Управление данными
7. Сводная статистика
8. Пороги включения
9. Стратификация населения
10. Оценка IBS / IBD
11.Ассоциация
12. Семейные ассоциации
13. Процедуры перестановки
14. Расчеты LD
15. Мультимаркерные тесты.
16. Условные тесты гаплотипов.
17. Прокси-ассоциация
18. Вменение (бета)
19. Данные по дозировке
20. Мета-анализ
21. Аннотация
22. Объединение результатов на основе LD
23. Генный отчет
24. Эпистаз.
25. Редкие CNV
26. Общие CNP
27. R-плагины
28. Поиск аннотаций в Интернете.
29. Инструменты моделирования.
30. Оценка профиля
31. ID помощник
32. Ресурсы
33. Блок-схема
34. Разное
35. Часто задаваемые вопросы и подсказки 36. gPLINK Управление данными
7. Сводная статистика
8. Пороги включения
9. Стратификация населения
10. Оценка IBS / IBD
11.Ассоциация
12. Семейные ассоциации
13. Процедуры перестановки
14. Расчеты LD
15. Мультимаркерные тесты.
16. Условные тесты гаплотипов.
17. Прокси-ассоциация
18. Вменение (бета)
19. Данные по дозировке
20. Мета-анализ
21. Аннотация
22. Объединение результатов на основе LD
23. Генный отчет
24. Эпистаз.
25. Редкие CNV
26. Общие CNP
27. R-плагины
28. Поиск аннотаций в Интернете.
29. Инструменты моделирования.
30. Оценка профиля
31. ID помощник
32. Ресурсы
33. Блок-схема
34. Разное
35. Часто задаваемые вопросы и подсказки 36. gPLINK | Базовый ассоциативный тест предназначен для признака болезни и основан на
сравнение частот аллелей между случаями и контролем (асимптотический
и эмпирические p-значения доступны).Также реализованы
Тест трендов Кокрана-Армитиджа, точный тест Фишера, различные генетические модели
(доминантный, рецессивный и общий), тесты для стратифицированных выборок (например,
Cochran-Mantel-Haenszel, Breslow-Day tests), тест для количественной
черта; тест на различия в частоте пропущенных генотипов между случаями и
элементы управления; мультилокусные тесты с использованием статистики Хотеллинга T (2) или
Суммарно-статистический подход (оцениваемый перестановкой), а также тесты гаплотипов. Базовый
тесты могут выполняться с перестановкой, описанной в
в следующем разделе представлены эмпирические
p-значения и учитывают различные конструкции (например,грамм. за счет использования структурированных,
внутрикластерная перестановка). Семейные тесты описаны в
следующий раздел HINT Основные команды ассоциации (--assoc,
--model, --fisher, --linear и --logistic) будет
проверить только один фенотип. Если ваш файл альтернативного фенотипа содержит более одного
фенотипа, затем добавление флага --all-pheno сделает цикл PLINK для каждого
фенотип, например вместо одного выходного файла plink.assoc, если есть
100 фенотипов, теперь PLINK покажет Базовый
тесты могут выполняться с перестановкой, описанной в
в следующем разделе представлены эмпирические
p-значения и учитывают различные конструкции (например,грамм. за счет использования структурированных,
внутрикластерная перестановка). Семейные тесты описаны в
следующий раздел HINT Основные команды ассоциации (--assoc,
--model, --fisher, --linear и --logistic) будет
проверить только один фенотип. Если ваш файл альтернативного фенотипа содержит более одного
фенотипа, затем добавление флага --all-pheno сделает цикл PLINK для каждого
фенотип, например вместо одного выходного файла plink.assoc, если есть
100 фенотипов, теперь PLINK покажет
Плинк.P1.assoc
plink.P2.assoc
...
plink.P100.assoc
Естественно, это займет в 100 раз больше времени ... Если вы тестируете очень большое количество
фенотипов, возможно, стоит также указать --pfilter, чтобы уменьшить
количество суммы (например, вывод только тестов, значимых при p = 1e-4, если --pfilter
1e-4).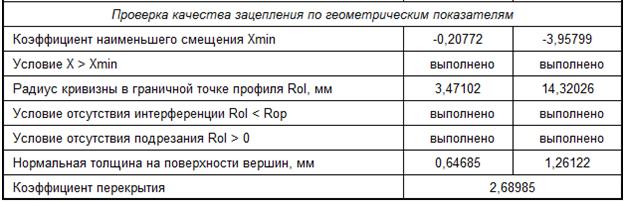 Базовый тест ассоциации случай / контрольЧтобы выполнить стандартный анализ ассоциации случай / контроль, используйте опцию:plink --file mydata --assocкоторый генерирует файл
Плинк.ассоциированный
который содержит поля:
Хромосома CHR
SNP ID SNP
BP Физическое положение (пара оснований)
Название минорного аллеля A1 (на основе всей выборки)
F_A Частота данного аллеля в случаях
F_U Частота данного аллеля в контроле
Название основного аллеля A2
CHISQ Базовый аллельный тест хи-квадрат (1df)
P Асимптотическое p-значение для этого теста
ИЛИ Расчетное отношение шансов (для A1, т.е. A2 является справочным)
Подсказка Кроме того, если необязательная команда
--ci X (где X - желаемое покрытие для
доверительный интервал, e.грамм. 0.95 или 0.99), затем два дополнительных
к этому выводу добавляются поля:
L95 Нижняя граница 95% доверительного интервала для отношения шансов
U95 Верхняя граница 95% доверительного интервала для отношения шансов
(где 95 изменится, если использовать другое значение с
--ci вариант, естественно). Добавление опции Добавление опции
--счетов
с --assoc будет указывать количество аллелей в отчетах PLINK, а не частоты в случаях и элементах управления. См. Следующий раздел о перестановке, чтобы узнать, как
для генерации эмпирических p-значений и использования других аспектов основанных на перестановках
тестирование.См. Раздел о многомаркерных тестах, чтобы узнать, как выполнять тесты на основе гаплотипов.
тесты ассоциации. Этот анализ должен автоматически обрабатывать SNP X / Y хромосомы.Точный тест Фишера (аллельная ассоциация)Чтобы выполнить стандартный анализ ассоциации случай / контроль, используя Для получения значимости используйте точный критерий Фишера:plink --file mydata --fisherкоторый генерирует файл
plink.fisher
который содержит поля:
Хромосома CHR
SNP ID SNP
BP Физическое положение (пара оснований)
Название минорного аллеля A1 (на основе всей выборки)
F_A Частота данного аллеля в случаях
F_U Частота данного аллеля в контроле
Название основного аллеля A2
P Точное значение p для этого теста
ИЛИ Расчетное отношение шансов (для A1)
Как описано ниже, если --fisher также указан с --model,
PLINK выполнит генотипические тесты с использованием точного теста Фишера. Примечание Вы также можете использовать перестановку для генерации точных,
эмпирические значения значимости, которые также будут действительны для небольших выборок,
и т.п. Примечание Вы также можете использовать перестановку для генерации точных,
эмпирические значения значимости, которые также будут действительны для небольших выборок,
и т.п.Альтернативные / полные тесты ассоциации моделейМожно провести тесты ассоциации между заболеванием и вариантом, отличным от базовый аллельный тест (который сравнивает частоты аллелей в случаях по сравнению с контролем), используя параметр --model. Предлагаемые здесь тесты (в дополнение к основному аллельному тесту):
 Генотипический тест представляет собой общий тест на ассоциацию в таблице 2 на 3 для распределения болезней по генотипам. В
Доминантная и рецессивная модели - это тесты на минорный аллель (который является
минорный аллель можно найти в выходных данных --assoc
или команды --freq. То есть, если D младший
аллель (а d - основной аллель): Генотипический тест представляет собой общий тест на ассоциацию в таблице 2 на 3 для распределения болезней по генотипам. В
Доминантная и рецессивная модели - это тесты на минорный аллель (который является
минорный аллель можно найти в выходных данных --assoc
или команды --freq. То есть, если D младший
аллель (а d - основной аллель):
Аллельный: D против d
Доминант: (DD, Dd) по сравнению с dd
Рецессивный: DD против (Dd, dd)
Генотип: DD против Dd против dd
Как упоминалось выше, эти тесты создаются с опцией:plink --file mydata --modelкоторый генерирует файл
Плинк.модель
который содержит следующие поля:
CHR Номер хромосомы
SNP Идентификатор SNP
ТЕСТ Тип теста
AFF Генотипы / аллели в случаях
UNAFF Генотипы / аллели в контроле
Статистика CHISQ Хи-квадрат
DF Степени свободы для теста
P Асимптотическое p-значение
Каждый SNP будет представлен в пяти строках вывода, что соответствует
применено пять тестов. Столбец ТЕСТ относится к
либо АЛЛИК, ТРЕНД, ГЕНО,
DOM или REC, относящиеся к различным типам тестов
упомянутое выше.Генотипический или аллельный подсчет дан для случаев
и контролирует отдельно. Для рецессивных и доминантных тестов
представляют собой генотипы с двумя объединенными классами. Эти тесты рассматривают только диплоидные генотипы: то есть для X
хромосомные самцы будут исключены даже из теста АЛЛЛИК. Сюда
те же данные используются для пяти представленных здесь тестов. Обратите внимание, что,
напротив, основные команды ассоциации (--assoc
и --linear и т. д.) включают одиночные мужские X-хромосомы, и поэтому
результаты могут отличаться.Генотипические и доминантные / рецессивные тесты будут проводиться только в том случае, если
минимальное количество наблюдений на ячейку в 2х3
таблица: по умолчанию, если хотя бы одна из ячеек имеет частоту меньше
чем 5, то пропускаем альтернативные тесты (NA записывается на
файл результатов). Тесты Кокрана-Армитажа и аллельные тесты
выполняется во всех случаях. Столбец ТЕСТ относится к
либо АЛЛИК, ТРЕНД, ГЕНО,
DOM или REC, относящиеся к различным типам тестов
упомянутое выше.Генотипический или аллельный подсчет дан для случаев
и контролирует отдельно. Для рецессивных и доминантных тестов
представляют собой генотипы с двумя объединенными классами. Эти тесты рассматривают только диплоидные генотипы: то есть для X
хромосомные самцы будут исключены даже из теста АЛЛЛИК. Сюда
те же данные используются для пяти представленных здесь тестов. Обратите внимание, что,
напротив, основные команды ассоциации (--assoc
и --linear и т. д.) включают одиночные мужские X-хромосомы, и поэтому
результаты могут отличаться.Генотипические и доминантные / рецессивные тесты будут проводиться только в том случае, если
минимальное количество наблюдений на ячейку в 2х3
таблица: по умолчанию, если хотя бы одна из ячеек имеет частоту меньше
чем 5, то пропускаем альтернативные тесты (NA записывается на
файл результатов). Тесты Кокрана-Армитажа и аллельные тесты
выполняется во всех случаях. Этот порог можно изменить с помощью
Опция --cell: Этот порог можно изменить с помощью
Опция --cell:plink --file mydata --model --cell 20Если перестановка (с параметрами --mperm или --perm) указан, опция -model по умолчанию выполнит перестановочный тест на основе наиболее значимого результата моделей ALLELIC, DOM и REC.То есть, для каждого SNP лучший исходный результат будет сравниваться с лучший из этих трех тестов для этого SNP для каждой реплики. В макс. (Т) режим перестановки, это также будет сравниваться с лучшим результатом из всех SNP для поля EMP2. Эта процедура контролирует тот факт, что мы выбрали лучшее из трех коррелированных тестов для каждого SNP. Вывод будет создан в файле
plink.model.best.perm
или
plink.model.best.mperm
в зависимости от того, использовалась ли перестановка адаптивная или max (T).Поведение команды --model можно изменить, добавив
--model-gen, --model-trend, --model-dom
или --model-rec, чтобы перестановка использовала
генотипический, тест тенденции Кокрэма-Армитиджа, доминантный тест или
вместо этого рецессивный тест как основа для перестановки. В этом случае один
из следующих файлов будут созданы: В этом случае один
из следующих файлов будут созданы:
plink.model.gen.perm plink.model.gen.mperm
plink.model.trend.perm plink.model.trend.mperm
plink.model.dom.perm plink.model.dom.mperm
plink.model.rec.perm plink.model.rec.mperm
Также можно добавить флаг --fisher для получения точных p-значений:./plink --bfile mydata --model --fisher, в этом случае поле CHISQ не отображается. Заметка что генотипические, аллельные, доминантные и рецессивные модели используют Точный Фишера; тренд-тест не дает и даст то же значение p, что и без флаг --fisher. Также по умолчанию при добавлении --fisher Поле --cell установлено в 0, т.е.е. включить все SNP.Стратифицированный анализКогда переменная кластера была указана, указав файл содержащий эту информацию, с помощью команды --within, можно выполнить ряд тестов на связь случай / контроль которые принимают во внимание эту кластеризацию или явно проверяют однородность эффекта между кластерами. Примечание Во многих случаях процедуры перестановки также могут
использоваться для учета кластеров в
данные. См. Более подробную информацию в следующем разделе.Представленные ниже тесты
применимы только для данных случая / контроля, поэтому перестановка может быть полезна
для количественных результатов по признаку,
и т.п. Есть два основных класса тестов: Примечание Во многих случаях процедуры перестановки также могут
использоваться для учета кластеров в
данные. См. Более подробную информацию в следующем разделе.Представленные ниже тесты
применимы только для данных случая / контроля, поэтому перестановка может быть полезна
для количественных результатов по признаку,
и т.п. Есть два основных класса тестов:
 Предлагаемые тесты: Предлагаемые тесты:
 В настоящее время тест 2x2xK представляет {болезнь x SNP |
cluster} test.Обобщенная форма, IxJxK, представляет собой
тест {кластера x SNP | болезнь}, т.е. меняется ли SNP
между кластерами, с контролем любого возможного истинного SNP / заболевания
ассоциация. Последний тест может быть полезен при интерпретации
значимые ассоциации в стратифицированных выборках. Обычно первые
Однако форма теста будет более интересной. Эти два теста
запускаются с использованием параметров: В настоящее время тест 2x2xK представляет {болезнь x SNP |
cluster} test.Обобщенная форма, IxJxK, представляет собой
тест {кластера x SNP | болезнь}, т.е. меняется ли SNP
между кластерами, с контролем любого возможного истинного SNP / заболевания
ассоциация. Последний тест может быть полезен при интерпретации
значимые ассоциации в стратифицированных выборках. Обычно первые
Однако форма теста будет более интересной. Эти два теста
запускаются с использованием параметров:plink --file mydata --mh --within mycluster.datдля основного теста CMH, илиplink --file mydata --mh3 - внутри mycluster.Датдля теста IxJxK. Параметр --mh создает файл
plink.cmh
который содержит поля
CHR Номер хромосомы
SNP Идентификатор SNP
Код минорного аллеля A1
Код основного аллеля A2
BP Физическое положение (пара оснований)
Статистика CHISQ Cochran-Mantel-Haenszel (1df)
P Асимптотическое значение p для теста CMH
ИЛИ отношение шансов CMH
L95 Нижняя граница доверительного интервала для отношения шансов CMH
U95 Верхняя граница доверительного интервала для отношения шансов CMH
Диапазон доверительного интервала с параметром --mh может быть
изменено опцией --ci: plink --file mydata --mh - внутри mycluster. Параметр --mh3 создает файл |
 dat --ci 0.99
dat --ci 0.99  Аналогичный тест на однородность тестов отношения шансов на основе
разделение статистики хи-квадрат определяется следующим образом:
Аналогичный тест на однородность тестов отношения шансов на основе
разделение статистики хи-квадрат определяется следующим образом: Параметр --set следует использовать для указания
какие SNP должны быть сгруппированы следующим образом:
Параметр --set следует использовать для указания
какие SNP должны быть сгруппированы следующим образом: С помощью
перестановка создаст один из следующих файлов:
С помощью
перестановка создаст один из следующих файлов: Если фенотип (столбец 6 файла PED или
фенотип, указанный с параметром --pheno)
количественный (т.е. содержит значения, отличные от 1, 2, 0 или отсутствующие)
тогда PLINK автоматически обработает анализ как
количественный анализ признаков.То есть та же команда, что и для
ассоциация болезнь-признак:
Если фенотип (столбец 6 файла PED или
фенотип, указанный с параметром --pheno)
количественный (т.е. содержит значения, отличные от 1, 2, 0 или отсутствующие)
тогда PLINK автоматически обработает анализ как
количественный анализ признаков.То есть та же команда, что и для
ассоциация болезнь-признак: следующий раздел
Детали). Эмпирические p-значения основаны на статистике Вальда.
следующий раздел
Детали). Эмпирические p-значения основаны на статистике Вальда.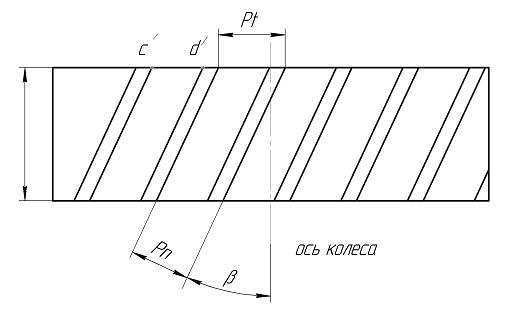 е. каждый SNP занимает 5 строк.
е. каждый SNP занимает 5 строк. е.е. 1 или 2 представляют первую или вторую группу.
Значения 0 или -9 могут использоваться для обозначения отсутствующих значений ковариант в
в этом случае этот человек будет исключен из анализа.
е.е. 1 или 2 представляют первую или вторую группу.
Значения 0 или -9 могут использоваться для обозначения отсутствующих значений ковариант в
в этом случае этот человек будет исключен из анализа. Все остальные команды в этом разделе одинаково применимы к обеим этим моделям. Эти команды либо сгенерируют выходной файл
Все остальные команды в этом разделе одинаково применимы к обеим этим моделям. Эти команды либо сгенерируют выходной файл ПРИМЕЧАНИЕ В других местах данной документации термин
Ссылочный аллель иногда используется для обозначения A1,
то есть команда --reference-allele может использоваться для указания
какой аллель - A1. Обратите внимание, что в ассоциативном тестировании отношения шансов,
и т. д. обычно рассчитываются с использованием A2 как фактического референсного аллеля
(я.е. положительное ИЛИ означает, что A1 увеличивает риск по сравнению с A2). СОВЕТ Добавление --ci 0.95, например,
вариант предоставит 95% доверительный интервал для предполагаемого
параметров в дополнительных полях L95 и U95 в
выходные файлы. Сама по себе команда --linear даст идентичные результаты для команды
Тест Вальда из команды --assoc применительно к количественному
черты. Команда --logistic может немного отличаться
результаты команды --assoc для признаков болезни, но это
потому что применяется другой тест / модель (т.е. логистическая регрессия
а не подсчет аллелей). Разница может быть особенно большой для
очень редкие аллели (т.
ПРИМЕЧАНИЕ В других местах данной документации термин
Ссылочный аллель иногда используется для обозначения A1,
то есть команда --reference-allele может использоваться для указания
какой аллель - A1. Обратите внимание, что в ассоциативном тестировании отношения шансов,
и т. д. обычно рассчитываются с использованием A2 как фактического референсного аллеля
(я.е. положительное ИЛИ означает, что A1 увеличивает риск по сравнению с A2). СОВЕТ Добавление --ci 0.95, например,
вариант предоставит 95% доверительный интервал для предполагаемого
параметров в дополнительных полях L95 и U95 в
выходные файлы. Сама по себе команда --linear даст идентичные результаты для команды
Тест Вальда из команды --assoc применительно к количественному
черты. Команда --logistic может немного отличаться
результаты команды --assoc для признаков болезни, но это
потому что применяется другой тест / модель (т.е. логистическая регрессия
а не подсчет аллелей). Разница может быть особенно большой для
очень редкие аллели (т. е. если SNP мономорфен в случаях или в контроле,
то модель логистической регрессии не является четко определенной и асимптотической
результаты могут не соответствовать базовому тесту). При использовании --linear добавляется опция
е. если SNP мономорфен в случаях или в контроле,
то модель логистической регрессии не является четко определенной и асимптотической
результаты могут не соответствовать базовому тесту). При использовании --linear добавляется опция То есть ДОМДЕВ
термин подбирается вместе с членом ADD в одной модели. ПРИМЕЧАНИЕ! Кодировка, которую PLINK использует с 2
df - генотипическая модель включает две переменные, представляющие
аддитивный эффект и отклонение доминирования;
То есть ДОМДЕВ
термин подбирается вместе с членом ADD в одной модели. ПРИМЕЧАНИЕ! Кодировка, которую PLINK использует с 2
df - генотипическая модель включает две переменные, представляющие
аддитивный эффект и отклонение доминирования;Коэффициенты | Purplemath
Purplemath
Пропорции строятся из соотношений.«Отношение» - это просто сравнение или соотношение двух разных вещей. Например, кто-то может посмотреть на группу людей, сосчитать носы и сослаться на «соотношение мужчин и женщин» в группе. Предположим, есть тридцать пять человек, пятнадцать из которых - мужчины. Остальные - женщины, итак:
... в группе двадцать женщин. Выражение «отношение (этого) к (этому)» означает, что (это) стоит перед (этим) в сравнении. Итак, если бы можно было выразить «соотношение мужчин и женщин», то соотношение, выражаясь английскими словами, было бы «15 мужчин к 20 женщинам» (или просто «15 к 20»).
MathHelp.com
Порядок элементов в соотношении очень важен и должен соблюдаться; какое бы слово ни было первым в соотношении (если оно выражено словами), его номер должен стоять первым в соотношении.Если бы выражение было «соотношение женщин и мужчин», то словесным выражением было бы «20 женщин к 15 мужчинам» (или просто «20 к 15»).
Соотношение мужчин и женщин выражается как «15 к 20», что выражается словами. Есть два других обозначения этого отношения "15 к 20":
обозначение шансов: 15: 20
дробное представление:
15 / 20Вы должны уметь распознать все три обозначения; вы, вероятно, должны будете знать их и как конвертировать между ними на следующем тесте.Например:
В определенном парке живут 16 уток и 9 гусей. Выразите соотношение уток и гусей через двоеточие, через дробь (не уменьшать) и прописью.
Они хотят «соотношение уток и гусей», поэтому число уток идет первым (или, в дробной форме, сверху). Итак, мой ответ:
Рассмотрим вышеупомянутый парк с 16 утками и 9 гусями.Выразите соотношение гусей и уток во всех трех форматах.
На этот раз они хотят, чтобы я дал им «соотношение гусей и уток». Я буду использовать те же самые числа, но в этом случае количество гусей идет первым (или, для дробной формы, сверху). Итак, мой ответ:
Числа были одинаковыми в каждом из двух упражнений, описанных выше, но порядок , , в котором они были перечислены, различается в зависимости от порядка, в котором были выражены элементы соотношения.В соотношениях очень важен порядок.
Давайте вернемся к 15 мужчинам и 20 женщинам в нашей первоначальной группе. Я выразил это отношение дробью, а именно:
15 / 20 . Эта фракция уменьшается до 3 / 4 . Это означает, что мы также можем выразить соотношение мужчин и женщин в группе как 3 / 4 , 3: 4 или «от 3 до 4».Это указывает на одну важную вещь о соотношениях: числа, используемые в соотношении, могут не быть абсолютными измеренными значениями.Соотношение «15 к 20» относится к абсолютным числам мужчин и женщин, соответственно, в группе из тридцати пяти человек. Упрощенное или сокращенное соотношение «3 к 4» говорит нам только о том, что на каждых трех мужчин приходится четыре женщины. Упрощенное соотношение также говорит нам, что в любой репрезентативной выборке из семи человек (3 + 4 = 7) из этой группы трое будут мужчинами. Другими словами, мужчины составляют
3 / 7 человек в группе. Эти отношения и рассуждения - то, что мы используем для решения многих словесных задач:В определенном классе соотношение положительных и отрицательных оценок составляет 7 к 5.Сколько из 36 студентов не прошли курс?
Соотношение «7 к 5» (или 7: 5 или
7 / 5 ) говорит мне, что из каждой репрезентативной группы студентов пять не смогли. Под «репрезентативной группой» я подразумеваю группу, в которой количество учеников такое же, как и во всем классе. Я могу определить размер этой группы, используя соотношение, которое они мне дали. Размер репрезентативной группы будет суммой ее частей:Итак, в репрезентативной группе 12 учеников, из которых 7 сдали экзамен, а 5 - нет.В частности, доля отказавшейся группы определяется путем деления количества отказавшихся студентов на общее количество студентов в репрезентативной группе. То есть:
Итак,
5/12 группы завалили, и, поскольку эта группа репрезентативна, завалили 5/12 всего класса. Это означает, что теперь я могу найти количество студентов во всем классе, которые провалились (это упражнение удручает!), Умножив долю из репрезентативной группы на размер всего класса:Итак, из класса 36 учеников класс не прошли:
Коэффициент из репрезентативной группы также может использоваться для получения информации о процентах.
Какой процент учащихся в вышеприведенном классе успешно сдал его? (Округлите ответ до одного десятичного знака.)
Я уже знаю, что в репрезентативной группе 12 учеников, из которых 7 сдали класс. Преобразуя это в проценты (разделив, а затем переместив десятичную точку, как описано здесь), я получу:
7/12 = 0.583333 ... = 58,3333 ...%
Они хотят, чтобы ответ был округлен до одного десятичного знака, поэтому мой ответ:
В парке, упомянутом ранее, соотношение уток и гусей составляет 16 к 9. Сколько из 300 птиц гуси?
Это соотношение говорит мне, что из каждой репрезентативной группы из 16 + 9 = 25 птиц 9 - гуси.То есть
9 / 25 птиц составляют гуси. Я могу использовать эту дробь из репрезентативной группы, чтобы найти ответ для всей группы:Это номер, который им нужен. Всего в парке насчитывается:
Как правило, проблемы с соотношениями сводятся к их установлению или упрощению. Например:
Выразите в простейшей форме следующее соотношение: от 10 до 45 долларов
Это упражнение требует, чтобы я записал отношение в виде уменьшенной дроби.Итак, сначала я сформирую дробь, а затем сделаю отмену, которая приведет к «простейшей форме».
Знаки доллара тоже погасли, потому что они были одинаковыми, верхняя и нижняя в дробной форме отношения. Итак, мой ответ:
Эта уменьшенная дробь является выражением отношения в простейшей дробной форме. Единицы (являющиеся знаками «доллар») отменены на дроби, потому что единицы (а именно, символы «$») были одинаковыми для обоих значений.
Если оба значения в соотношении имеют одну и ту же единицу измерения или обозначение, в сокращенной форме отношения не должно быть единиц или обозначения. Единицы - это не факторы, но они отменяются так же, как и факторы.
Выразите в простейшей форме следующее соотношение: 240 миль к 8 галлонам
Члены этого отношения имеют разные единицы измерения, поэтому они не отменяются; по моему упрощенному соотношению будут единицы.Мое упрощение выглядит так:
(240 миль) / (8 галлонов)
= (30 миль) / (1 галлон)
Это конкретное соотношение единиц, «(мили) / (галлон)», имеет свою собственную упрощенную форму; а именно «миль на галлон», сокращенно «миль на галлон». Итак, на стандартном английском мой ответ:
.В отличие от ответа в предыдущем упражнении, в ответе из этого упражнения не нужно было указывать единицы измерения, поскольку единицы измерения двух частей отношения (а именно «мили» и «галлоны») не были то же самое, и, таким образом, не отменяли друг друга.Когда отношение заканчивается единицами (или размерами) на нем, это отношение также может называться «ставкой». В случае с упражнением, описанным выше, тариф был пройденным расстоянием на единицу объема топлива.
Коэффициенты пересчета - это упрощенные соотношения, поэтому они могут быть рассмотрены примерно в то же время, когда вы изучаете соотношения и пропорции. Например:
Какова длина игрового поля на поле для американского футбола в футах (то есть длина поля без учета «концевых» зон)?
Я знаю, что длина поля для американского футбола без учета «конечных» зон составляет 100 ярдов.