Как выставить по уровню столбчатый фундамент: Как выровнять столбчатый фундамент по уровню
Как разметить столбчатый фундамент
Все знают, что фундамент – это конструкция, гарантирующая долговечность сооружения. Правильное его устройство – залог всего строительства дома. Первым шагом строительства любого здания считается разметка под фундамент. Разберёмся, как разметить столбчатый фундамент.
Все знают, что фундамент – это конструкция, гарантирующая долговечность сооружения. Правильное его устройство – залог всего строительства дома. Первым шагом строительства любого здания считается разметка под фундамент. Разберёмся, как разметить столбчатый фундамент.
Особенности столбчатого фундамента
Столбчатый фундамент – это упрощённый вариант свайного фундамента с одним принципом работы и схожей конструкцией. По осям здания в обоих случаях располагаются круглые или прямоугольные вертикальные опоры. Их устанавливают в самых нагруженных участках и во всех точках, где пересекаются несущие стены.
Если нет особых условий, столбы по периметру располагают равномерно с шагом 1,5 – 2 м. Опоры соединяются ростверком или балками, а пространство между ними заполняется «забиркой».
Опоры соединяются ростверком или балками, а пространство между ними заполняется «забиркой».
Некоторые термины:
- Обрез. Так называют верхнюю плоскость, на которой будет строиться надземная часть здания.
- Подошва. Так называется подземная часть строительной площадки.
- Репер. Это знак (шест, рейка, столб) который является контрольной отметкой и привязывается к местности, например, к уровню соседней дороги.
- Обноска. Это несколько пар сбитых рейкой и вкопанных в землю столбиков из дерева, которые отступают на 1,5 – 2 м от углов строящегося фундамента. Они являются визуальным продолжением стены и, соединённые бечёвкой, образуют точный контур вертикальной плоскости.
Подготовительные работы и разметка
Перед началом разметки нужно:
- исследовать грунт;
- замерить перепады высот;
- подготовить план-схему столбчатого фундамента;
- сделать временный водоотвод на участке, применив дренирующие канавы;
- строительную площадку очистить от дёрна.


После выполнения начальных операций выносим в натуру проектные отметки. Разметка представляет собой привязку дома к красным линиям и разбивку осей строящегося здания, а также контуров столбчатого фундамента. Делается обноска контрольными шнурами.
Выполняя разметку, надо обязательно выполнить следующие условия:
- Прямоугольность сопряжения основных линий должна быть идеальна (при расчёте примените теорему Пифагора о Египетском треугольнике).
- Верх всех столбов должен быть на одном уровне, подрезать позже оголовки крайне сложно. Контрольные шнуры должны быть натянуты по отметкам, сделанным гидроуровнем или нивелиром.
Разметку под фундамент начинаем с установки репера при помощи нивелира. Устанавливают его для надёжности в двух местах. Площадка под фундамент выравнивается с допуском незначительных отклонений в горизонтальной плоскости. Для разметки необходимы простейшие инструменты:
- бечёвка;
- рулетка;
- куски арматуры;
- деревянные колышки;
- отвес;
- доски для обноски.

Определяем оси строения, первоначально разметив прямоугольник, определяющий фундамент основной постройки. Дальше с помощью отвеса нужно определить угол дома и вбить столбик.
От него бечёвкой обозначаем перпендикулярно друг другу стороны прямоугольника. Вбиваем по углам арматуру и проверяем диагонали, которые должны соответствовать указанным в проекте размерам.
После выставления внешнего контура необходимо выставить внутренний контур, отмерив от внешних линий проектную ширину фундамента. По этому же принципу делаем разметку внутренних перегородок. Намечаем с учётом выбранного шага точки, где будут бурить скважины под опоры.
В результате размечаем внешний контур ростверка (внешние и несущие стены), точки, в которых нужно бурить ямы под опоры, и внутренний контур ростверка.
Обноска столбчатого фундамента
Надо подчеркнуть важность устройства обноски. Это фактически эталонная разметка, на которую возлагается контроль размеров. При проведении земляных работ бечёвка, которую применяли на первоначальном этапе разметки, не позволяет контролировать их правильное выполнение, т. к. мешает и часто рвётся. Ориентируются на обноску, которая помогает контролировать все размеры, включая проектную ширину и глубину ям под опоры, независимо от рельефа местности.
к. мешает и часто рвётся. Ориентируются на обноску, которая помогает контролировать все размеры, включая проектную ширину и глубину ям под опоры, независимо от рельефа местности.
Любой тип фундамента размечают одинаково. При этом наличие подвала или цокольного этажа, глубина и ширина траншеи, материал фундамента, размеры ростверка или количество ям под опоры на выполнение разметки не влияют. Для столбчатого фундамента очень важно точное определение осей, проходящих по линиям бурения скважин. Даже небольшое отклонение приведёт к потере прочности и стабильности будущего основания.
Теперь мы знаем, как разметить столбчатый фундамент своими силами. С помощником можно сделать эту работу за один час. При сложной конфигурации дома из основного прямоугольника вычленяют мелкие детали, что потребует больше времени и дополнительное количество обносок.
Пример создания разметки (видео)
Читайте также:
Как выровнять фундамент: ленточный, плитный, столбчатый
Содержание
- Виды фундаментных конструкций
- Методы предотвращения образования неровностей
- Устранение боковых неровностей
- Устранение верхних неровностей
- Ленточного фундамента
- Плитного фундамента
- Столбчатого фундамента
- Заключение
Застройщики чаще всего в качестве фундаментного основания выбирают ленточную конструкцию. Технология ее заливки вполне доступна, работы можно выполнять собственными силами, не привлекая опытных специалистов, но определенные навыки все же необходимы. Следует правильно представлять не только порядок работ, но и знать, как выровнять фундамент, если возникает такая необходимость. Ровность поверхности – немаловажное условие для строительства стен, и таким фактом пренебрегать не следует. И все же, как выровнять цоколь и боковые стенки, если фундамент неровный?
Технология ее заливки вполне доступна, работы можно выполнять собственными силами, не привлекая опытных специалистов, но определенные навыки все же необходимы. Следует правильно представлять не только порядок работ, но и знать, как выровнять фундамент, если возникает такая необходимость. Ровность поверхности – немаловажное условие для строительства стен, и таким фактом пренебрегать не следует. И все же, как выровнять цоколь и боковые стенки, если фундамент неровный?
Виды фундаментных конструкций
При возведении жилых объектов и других сооружений возводя ленточные, столбчатые, плитные и свайные фундаментные основания. Для каждой разновидности конструкции имеются свои особенности возведения, которые следует знать.
В строительной сфере любая мелочь имеет свое значение, и если на определенном этапе нарушается технологический процесс, то фундаментная конструкция получается ненадежной и имеет существенные дефекты, которые приходится устранять.
Методы предотвращения образования неровностей
Чтобы верх вашего фундамента после завершения заливки получился ровным, рекомендуется в первую очередь правильно определить уровень.
Такая операция связана с обозначением крайних точек фундаментной основы, пределы которых нарушать запрещается.
Если требуется исправить дефекты уже залитой конструкции, придется повторно выставлять уровень и выполнять выравнивание.
Опытные мастера, попав в подобную ситуацию, утверждают, что в этом случае необходимо грамотно выводить цоколь фундамента «под ноль». Это означает, что все точки должны располагаться в единой плоскости.
Фундаментное дно уже не поправить, так что на материале для песчаной подсыпки экономить не следует. Кроме того, необходимо изучить характеристики почвенного состава и выдерживать требования СНиП, определяющие минимальную заглубленность железобетонной конструкции.
Монтажные работы, выполняемые по существующим требованиям, являются гарантом получения геометрически правильной опорной конструкции, не требующей реставрационных мероприятий.
Чтобы выполнить все работы правильно, следуйте советам специалистов:
- изначально для ленточного или плитного основания выравнивается подстилающий слой, состоящий из песка и щебенки. Проанализировав состояние грунта и предполагаемую массу строящегося объекта, проектировщики могут определить закладку дополнительных слоев. Одно из обязательных условий – заливка тонкого бетонного покрытия для подушки из раствора М 75 или М 100;
- очередное важное условие – качество опалубочной системы. Создавая фундаментную стену или монолитную плиту, следует использовать фанерные листы с ламинированной поверхностью, толщина которых начинается от двух сантиметров, либо крепкие доски. Все щиты выставляются плотно друг к другу, чтобы исключить протекание растворной смеси. Необходимую жесткость создают крепежными элементами и подпорками;
- проверка уровня поверхности залитого бетона выполняется сразу после завершения процесса бетонирования. Поверхности плитных фундаментов выравниваются длинными инструментами, для ленточного фундамента достаточно шпателя или мастерка;
- при установке свайного или столбчатого фундамента постоянно контролируется уровень высоты опорных элементов, для чего потребуется нивелир.
 Проанализировав состояние грунта и предполагаемую массу строящегося объекта, проектировщики могут определить закладку дополнительных слоев. Одно из обязательных условий – заливка тонкого бетонного покрытия для подушки из раствора М 75 или М 100;
Проанализировав состояние грунта и предполагаемую массу строящегося объекта, проектировщики могут определить закладку дополнительных слоев. Одно из обязательных условий – заливка тонкого бетонного покрытия для подушки из раствора М 75 или М 100;
Помните, что даже при выполнении перечисленных требований вероятность возникновения ошибок существенно велика.
Устранение боковых неровностей
Выравнивание их выполняется с учетом величины перекоса. Если расхождения небольшие, можно скобами либо дюбелями зафиксировать сетку-рабицу и по ней выложить новый слой штукатурного раствора.
В случае, когда разница достаточно большая, прибегают к следующим действиям:
- при небольших перекосах раствор распределяется по пустотным участкам, образовавшимся между стенками фундаментной основы и опалубочными щитами;
- когда промежутки превышают пять сантиметров, необходимо накладывать армирующую сеточку в местах, где планируется выполнить бетонирование.
Данный способ помогает достигать максимальной адгезии жидкого бетона и высохшей поверхности основания.
Устранение верхних неровностей
А как выровнять фундамент после заливки по горизонту? Считается, что такие работы относятся к наиболее ответственным мероприятиям, ведь именно на основу устраивается гидроизоляционный слой, и она непосредственно контактирует с несущими стенами.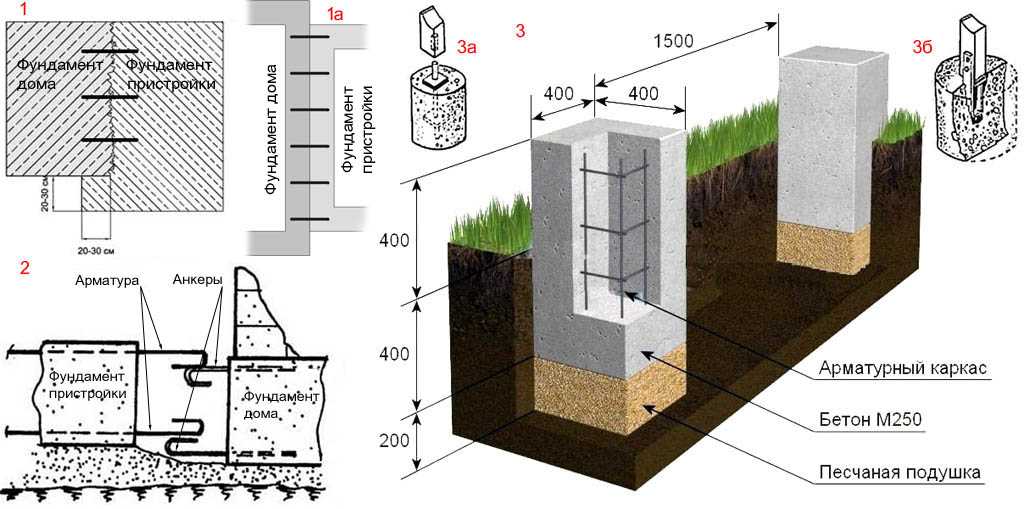
Так как выровнять фундамент под ноль? Алгоритм действий следующий:
- заново устанавливается опалубка, проверяется строительным уровнем высота;
- на опалубочных щитах делаются отметки, позволяющие вам отслеживать, чтобы растворная масса в этот раз распределилась равномерно.
Не следует ставить отметки маркером или карандашом – установите маяки из саморезов.
А чем выровнять фундамент после заливки? Для этого готовится свежий раствор, консистенция которого должна быть значительно жиже, чем при бетонировании основной конструкции.
Ленточного фундамента
Для исправления такого неровного фундамента вам потребуются:
- цемент;
- лопата совковая;
- песок;
- уровень и рулетка;
- сетка для армирования;
- опалубка;
- кирпичи;
- мастерок.
С помощью уровня определяется максимальная точка в расхождениях, которая берется за основной ориентир для выравнивания. Помните, что данное мероприятие более серьезное, чем исправление боковых поверхностей.
Помните, что данное мероприятие более серьезное, чем исправление боковых поверхностей.
Процесс выравнивания выполняется кирпичным камнем, который предварительно распиливается перед укладкой. От ровности поверхности зависит эксплуатационный период всего сооружения, поэтому все расхождения должны быть исключены.
Для исправления проблем можно выставить опалубку, определить границу заливки, приготовить раствор и провести бетонирование на необходимую высоту.
Выравнивание ленточного фундамента после заливки с помощью кирпича – отличный вариант, если планируется монтаж цокольной части.
Плитного фундамента
Выравнивание такого монолитного фундамента перед кладкой представляет собой сложный процесс. Заливая плитную основу, необходимо тщательным образом подготовить дно котлована, заложить и уплотнить фундаментную подушку, провести отсыпку щебнем. Если выявятся дефектные участки на плоскости и по горизонту, придется провести дополнительные мероприятия:
- определить нулевую точку;
- на необходимой высоте выставить и укрепить опалубку под фундамент, выровнять ее по горизонту;
- залить жидкую растворную смесь и выровнять его поверхность длинным правилом.
Столбчатого фундамента
Такая опорная конструкция считается экономичной по сравнению с мелкозаглубленной ленточной основой, и по этой причине ее используют достаточно часто.
Опоры изготавливаются отдельными столбами из бетонного раствора или кирпичного камня. На них в дальнейшем воздействую нагрузочные усилия от всего сооружения, так что установка подобного фундамента требует предельной точности.
Как выровнять неровности фундамента и проверить его диагональ? Для этого воспользуйтесь следующими советами:
- столбчатые опоры, возведенные из кирпичного материала, размещаются с определенном интервалом по всей строительной площадке. Чтобы вывести верх опорных элементов по одной высоте, можно использовать гидроуровень и передавать нулевую точку каждому опорному элементу. Определив отклонения от общего проектного параметра высоты, опора «поднимается» кирпичной кладкой;
- если отклонение незначительное и превышает высоту кирпичного камня, на столб укладывается бетон высокой марки. Только перед этим придется установить опалубку.
Заключение
Устранить дефектные места и выровнять фундаментное основание реально, но для этого придется потрудиться. Дело в том, что исправление строительных промахов – вопрос сложный и затратный. Перед началом работ рекомендуется изучить технологический процесс, чтобы исключить вероятность ошибок.
Построение сжатия по столбцам в базе данных, ориентированной на строки
Как мы добились сжатия 91%-96% в последней версии TimescaleDB
Сегодня мы рады объявить о новой собственной возможности сжатия для TimescaleDB, временного ряда БД на PostgreSQL. Эта новая функция, которая находилась в закрытом бета-тестировании в течение нескольких месяцев, использует лучшие в своем классе алгоритмы сжатия, а также новый метод создания гибридного хранилища строк и столбцов. Во время нашего бета-тестирования мы приглашали членов сообщества попробовать его и оставить нам отзыв, и в результате сейчас мы видим до 9Коэффициент сжатия без потерь 6% для различных реальных и смоделированных рабочих нагрузок временных рядов.
В этом выпуске размер хранилища TimescaleDB теперь сопоставим со специально созданными и более ограниченными хранилищами NoSQL — без ущерба для наших уникальных возможностей. TimescaleDB по-прежнему предлагает полноценный SQL, реляционные JOIN и функции, мощные возможности автоматизации, а также надежность и огромную экосистему, основанную на использовании основы PostgreSQL. Мы знаем, что хранилище могло быть ограничивающим фактором для некоторых людей, заинтересованных в TimescaleDB в прошлом, но мы рекомендуем вам попробовать собственное сжатие и сообщить нам, что вы думаете.
TimescaleDB достигает такой степени сжатия за счет использования лучших в своем классе алгоритмов сжатия различных типов данных. Мы используем следующие алгоритмы (и позволим пользователям выбрать алгоритм в будущих выпусках):
- Сжатие Gorilla для чисел с плавающей запятой подобные типы
- Сжатие словаря всей строки для столбцов с несколькими повторяющимися значениями (+ сжатие LZ сверху)
- Сжатие массива на основе LZ для всех остальных типов
Мы расширили Gorilla и Simple-8b для обработки распаковки данных в обратном порядке, что позволяет нам ускорить запросы, использующие обратное сканирование. Для супер технических подробностей, пожалуйста, смотрите наш пресс-релиз по компрессии.
(Мы обнаружили, что это типоспецифичное сжатие довольно мощное: в дополнение к более высокой сжимаемости, некоторые из методов, таких как Gorilla и дельта-дельта, могут быть до 40 раз быстрее, чем сжатие на основе LZ во время декодирования, что приводит к значительному увеличению производительности. улучшенная производительность запросов.)
В будущем мы планируем предоставить расширенные алгоритмы для других собственных типов, таких как данные JSON, но даже сегодня, используя описанные выше подходы, все типы данных PostgreSQL могут использоваться в собственном сжатии TimescaleDB.
Встроенное сжатие (и TimescaleDB 1.5) сегодня широко доступно для загрузки по всем нашим каналам распространения, включая Managed Service for TimescaleDB. Эта возможность выпущена под нашей лицензией Timescale Community (поэтому ее можно использовать совершенно бесплатно).
Базы данных, ориентированные на строки и столбцы
Традиционно базы данных относятся к одной из двух категорий: базы данных, ориентированные на строки, и базы данных, ориентированные на столбцы (они же «столбцы»).
Вот пример: Допустим, у нас есть таблица, в которой хранятся следующие данные для 1 млн пользователей: user_id, name, # logins, last_login . Таким образом, у нас фактически есть 1 миллион строк и 4 столбца. Хранилище данных, ориентированное на строки, будет физически хранить данные каждого пользователя (т. е. каждую строку) на диске непрерывно. Напротив, хранилище столбцов будет хранить все user_id вместе, все имена вместе и так далее, так что данные каждого столбца будут храниться на диске непрерывно.
В результате поверхностные и широкие запросы будут выполняться быстрее в хранилище строк (например, «извлечь все данные для пользователя X»), а глубокие и узкие запросы будут выполняться быстрее в хранилище столбцов (например, « рассчитать среднее количество входов в систему для всех пользователей»).
В частности, хранилища столбцов очень хорошо справляются с узкими запросами к очень большим данным. При таком хранилище необходимо считывать с диска только указанные столбцы (вместо того, чтобы загружать страницы данных с диска со всеми строками, а затем выбирать один или несколько столбцов только в памяти).
Кроме того, поскольку отдельные столбцы данных обычно относятся к одному типу и часто берутся из более ограниченной области или диапазона, они обычно сжимаются лучше, чем целая широкая строка данных, содержащая множество различных типов данных и диапазонов. Например, наш столбец количества входов в систему будет иметь целочисленный тип и может охватывать небольшой диапазон числовых значений.
Тем не менее, магазины в виде колонн не обходятся без компромиссов. Во-первых, вставки занимают гораздо больше времени: системе нужно разбить каждую запись на соответствующие столбцы и соответствующим образом записать ее на диск. Во-вторых, хранилищам на основе строк проще использовать индекс (например, B-дерево) для быстрого поиска подходящих записей. В-третьих, с помощью хранилища строк легче нормализовать набор данных, чтобы вы могли более эффективно хранить связанные наборы данных в других таблицах.
В результате выбор между базой данных, ориентированной на строки, и базой данных, ориентированной на столбцы, сильно зависит от вашей рабочей нагрузки. Как правило, хранилища, ориентированные на строки, используются с транзакционными (OLTP) рабочими нагрузками, а хранилища по столбцам — с аналитическими (OLAP) рабочими нагрузками.
Но рабочие нагрузки временных рядов уникальны
Если вы раньше работали с данными временных рядов, вы знаете, что рабочие нагрузки уникальны во многих отношениях:
- Запросы временных рядов могут быть отдельный запрос обращается ко многим столбцам данных, а также к данным на многих различных устройствах/серверах/элементах. Например, « Что происходит в моем развертывании за последние K минут? »
- Запросы временных рядов также могут быть глубокими и узкими, когда отдельный запрос выбирает меньшее количество столбцов для определенного устройства/сервера/элемента за более длительный период времени. Например, « Какова средняя загрузка ЦП для этого сервера за последние 24 часа? ”
- Рабочие нагрузки временных рядов обычно требуют большого количества вставок. Скорость вставки в сотни тысяч операций записи в секунду является нормальной.
- Наборы данных временных рядов также очень детализированы, эффективно собирая данные с более высоким разрешением, чем OLTP или OLAP, что приводит к гораздо большим наборам данных. Терабайты данных временных рядов также вполне нормальны.
В результате оптимальное хранилище временных рядов должно:
- Поддерживать высокую скорость вставки, легко достигающую сотен тысяч операций записи в секунду
- Эффективно обрабатывать как мелкие и широкие, так и глубокие и узкие запросы в этом большом наборе данных
- Эффективно хранить, т. е. сжимать, этот большой набор данных, чтобы он был управляемым и экономически эффективным
Именно это мы сделали с последней версией TimescaleDB.
Сочетание лучшего из обоих миров
Архитектура TimescaleDB представляет собой базу данных временных рядов, построенную на основе PostgreSQL. При этом он наследует все самое лучшее, что есть в PostgreSQL: полноценный SQL, огромную гибкость модели запросов и данных, проверенную надежность, активную и ярую базу разработчиков и пользователей, а также одну из крупнейших экосистем баз данных.
Но низкоуровневое хранилище TimescaleDB использует ориентированный на строки формат хранения PostgreSQL, который добавляет скромные накладные расходы на каждую строку и снижает сжимаемость, поскольку непрерывные значения данных имеют множество различных типов — строки, целые числа, числа с плавающей запятой и т. д. — и взяты из разных диапазонов. И сам по себе PostgreSQL на сегодняшний день не предлагает никакого встроенного сжатия (за исключением очень больших объектов, хранящихся на их собственных «TOAST-страницах», которые неприменимы для большей части содержимого).
В качестве альтернативы некоторые пользователи запускают TimescaleDB в сжатой файловой системе, такой как ZFS или BTRFS, для экономии места на диске, часто в режиме 3x-9. х диапазон. Но это приводит к некоторым проблемам развертывания, учитывая, что это внешняя зависимость, и на ее сжимаемость по-прежнему влияет ориентированный на строки характер базовой базы данных (поскольку данные сопоставляются со страницами диска).
Теперь, с TimescaleDB 1.5, мы смогли объединить лучшее из обоих миров: (1) все преимущества PostgreSQL, включая производительность вставки и производительность поверхностных и широких запросов для последних данных из хранилища строк, в сочетании с (2) сжатием и дополнительной производительностью запросов — чтобы гарантировать, что мы только читать сжатые столбцы, указанные в запросе — для глубоких и узких запросов хранилища столбцов.
Вот результаты.
Результаты: экономия пространства на уровне 91-96 % (по данным независимого бета-тестирования)
Перед выпуском мы попросили некоторых членов сообщества и существующих клиентов TimescaleDB провести бета-тестирование новых функций сжатия с некоторыми из их реальных наборов данных, а также как проверенное сжатие по наборам данных Time-Series Benchmarking Suite.
Ниже приведены результаты, которые включают тип рабочей нагрузки, общее количество несжатых байтов, сжатые байты (размер, который они увидели после сжатия) и экономию при сжатии. И эта экономия только при кодировании без потерь для сжатия.
| Рабочая нагрузка | Несжатый | Сжатый | Экономия на хранении |
| Показатели ИТ (от бета-тестера Telco) | 1396 ГБ | 77,0 ГБ | 94% экономии |
| Данные мониторинга промышленного IoT (из бета-тестера) | 1,445 ГБ | 0,077 ГБ | 95% экономии |
| Показатели ИТ (набор данных DevOps из TSBS) | 125 ГБ | 5,5 ГБ | 96% экономии |
| Данные мониторинга IoT (набор данных IoT из TSBS) | 251 ГБ | 23,8 ГБ | Экономия 91% |
«Коэффициент сжатия невероятно высок :)» — Тамихиро Ли, сетевой инженер, Sakura Internet
Дополнительные результаты: экономия затрат и более быстрые запросы
Но такое сжатие не только академическое, оно дает два реальных преимущества:
- Стоимость. Хранение в масштабе стоит дорого. Дисковый том объемом 10 ТБ в облаке сам по себе стоит более 12 000 долларов США в год (из расчета 0,10 долларов США/ГБ/месяц для хранилища AWS EBS), а дополнительные реплики высокой доступности и резервные копии могут увеличить эту цифру еще в 2–3 раза. Достижение 9Хранилище 5 % может сэкономить вам более 10 000 – 25 000 долларов США в год только на расходах на хранение (например, 12 000 $/10 ТБ * 10 ТБ/машина * 2 машины [один мастер и одна реплика] * экономия 95 % = 22,8 000 $ ) .
- Производительность запросов. Сжатие приводит к немедленному повышению производительности для многих типов запросов. Чем больше данных помещается в меньшем пространстве, тем меньше страниц диска (со сжатыми данными) необходимо прочитать для ответа на запросы. (Ниже приведен краткий обзор бенчмаркинга, а более подробное описание будет в следующем посте.)
Дальнейшие действия
Собственное сжатие сегодня широко доступно в TimescaleDB 1. 5. Вы можете либо установить TimescaleDB, либо обновить текущее развертывание TimescaleDB. Если вы ищете полностью управляемый размещенный вариант, мы рекомендуем вам ознакомиться с управляемой службой для TimescaleDB (мы предлагаем бесплатную 30-дневную пробную версию).
Мы также рекомендуем вам подписаться на наш предстоящий веб-семинар «Как снизить общую стоимость владения базой данных с помощью TimescaleDB», чтобы узнать больше.
Теперь, если вы хотите узнать больше о забавных технических деталях — о построении колоночного хранилища в системах на основе строк, индексации и запросах к сжатым данным, а также о некоторых тестах — пожалуйста, продолжайте читать.
Все заслуги в этих результатах принадлежат нашим замечательным инженерам и менеджерам по проектам: Джошу Локерману, Гаятри Айяпану, Свену Клемму, Дэвиду Кону, Анте Крешичу, Мату Арье, Дайане Хси и Бобу Булю. (И да, мы набираем сотрудников по всему миру.)
Построение колоночного хранилища на основе построчной системы
Признавая, что рабочие нагрузки временных рядов обращаются к данным во временном порядке, наш высокоуровневый подход к построению столбцового хранилища заключается в преобразовании множества широких строк данных (скажем, 1000) в одну строку данных. Но теперь каждое поле (столбец) этой новой строки хранит упорядоченный набор данных, включающий весь столбец из 1000 строк.
Итак, рассмотрим упрощенный пример, используя таблицу со следующей схемой:
| Отметка времени | Идентификатор устройства | Код состояния | Температура |
| 12:00:01 | А | 0 | 70.11 |
| 12:00:01 | Б | 0 | 69,70 |
| 12:00:02 | А | 0 | 70.12 |
| 12:00:02 | Б | 0 | 69,69 |
| 12:00:03 | А | 0 | 70.14 |
| 12:00:03 | Б | 4 | 69,70 |
После преобразования этих данных в одну строку данные в форме «массива»:
| Отметка времени | Идентификатор устройства | Код состояния | Температура |
| [12:00:01, 12:00:01, 12:00:02, 12:00:02, 12:00:03, 12:00:03] | [А, Б, А, Б, А, Б] | [0, 0, 0, 0, 0, 4] | [70. 11, 69.70, 70.12, 69.69, 70.14, 69.70] |
Даже до использования сжатия данных этот формат сразу экономит место, значительно снижая наши внутренние накладные расходы на строку. PostgreSQL обычно добавляет ~ 27 байт служебных данных на строку (например, для управления версиями MVCC). Таким образом, даже без сжатия, если наша схема выше, скажем, 32 байта, то 1000 строк данных, которые ранее занимали [1000 * (32 + 27)] ~= 59 килобайт теперь занимает [1000 * 32 + 27] ~= 32 килобайта в этом формате.
Но, учитывая формат, в котором схожие данные (временные метки, идентификаторы устройств, показания температуры и т. д.) хранятся непрерывно, мы можем применить к нему алгоритмы сжатия для конкретного типа, чтобы каждый массив сжимался отдельно.
Затем, если запрос запрашивает подмножество этих столбцов:
ВЫБРАТЬ time_bucket(‘1 minute’, timestamp) как минуту СРЕДНЯЯ (температура) ИЗ таблицы WHERE timestamp > now() - интервал «1 день» ЗАКАЗАТЬ ПО МИНУТАМ DESC СГРУППИРОВАТЬ ПО минутам
Механизм запросов может извлекать (и распаковывать во время запроса) только столбцы метки времени и температуры для вычисления и возврата этой агрегации.
Но, учитывая, что формат хранения Postgres в стиле MVCC может записывать несколько строк на одну и ту же страницу диска, как мы можем получить с диска только нужные сжатые массивы, а не более широкий набор окружающих данных? Здесь мы используем невстроенные страницы диска для хранения этих сжатых массивов, т. е. они подвергаются TOAST, так что данные в строке теперь указывают на вторичную страницу диска, на которой хранится сжатый массив (фактическая строка в основной таблице кучи становится очень маленькой). , потому что это просто указатели на данные TOAST). Таким образом, с диска загружаются только сжатые массивы для необходимых столбцов, что еще больше повышает производительность запросов за счет сокращения дискового ввода-вывода. (Помните, что каждый массив может содержать от 100 до 1000 элементов данных, а не 6, как показано.)
Индексирование и запросы к сжатым данным
Однако этот формат сам по себе имеет серьезную проблему: какие строки должна извлекать и распаковывать база данных для выполнения запроса? В приведенной выше схеме база данных не может легко определить, какие строки содержат данные за прошедший день, поскольку сама метка времени находится в сжатом столбце. Нужно ли распаковывать все данные в порции (или даже всю гипертаблицу), чтобы определить, какие строки соответствуют последнему дню? Точно так же пользовательские запросы обычно могут фильтроваться или группироваться по определенному устройству (например, ВЫБЕРИТЕ температуру… ГДЕ device_id = ‘A’ ).
Распаковка всех данных будет очень неэффективной. Но поскольку мы оптимизируем эту таблицу для запросов временных рядов, мы можем сделать больше и автоматически включать больше информации в эту строку для повышения производительности запросов.
TimescaleDB делает это, автоматически создавая подсказки данных и включая дополнительные группы при преобразовании данных в этот столбчатый формат. При сжатии несжатой гипертаблицы (либо с помощью специальной команды, либо с помощью асинхронной политики) пользователь указывает столбцы «упорядочить по» и, при необходимости, «сегментировать по» столбцам. Столбцы ORDER BY определяют, как упорядочены строки, являющиеся частью сжатого исправления. Как правило, это временная метка, как в нашем рабочем примере, хотя она также может быть составной, например, ORDER BY time, then location.
Для каждого столбца «ORDER BY» TimescaleDB автоматически создает дополнительные столбцы, в которых хранятся минимальное и максимальное значение этого столбца. Таким образом, планировщик запросов может просмотреть этот специальный столбец, указывающий диапазон меток времени в сжатом столбце, без предварительного выполнения какой-либо распаковки, чтобы определить, может ли строка соответствовать предикату времени, указанному в SQL-запросе пользователя. .
Мы также можем сегментировать сжатые строки по определенному столбцу, чтобы каждая сжатая строка соответствовала данным об одном элементе, например, определенному идентификатору устройства. В следующем примере TimescaleDB выполняет сегментацию по device_id, так что для устройств A и B существуют отдельные сжатые строки, и каждая сжатая строка содержит данные из 1000 несжатых строк об этом устройстве.
| Идентификатор устройства | Отметка времени | Код состояния | Температура | Мин. метка времени | Максимальная отметка времени |
| А | [12:00:01, 12:00:02, 12:00:03] | [0, 0, 0] | [70.11, 70.12, 70.14] | 12:00:01 | 12:00:03 |
| Б | [12:00:01, 12:00:02, 12:00:03] | [0, 0, 0] | [70.11, 70.12, 70.14] | 12:00:01 | 12:00:03 |
Теперь запрос для устройства «А» между временными интервалами выполняется довольно быстро: планировщик запросов может использовать индекс для поиска тех строк для «А», которые содержат хотя бы несколько временных меток, соответствующих указанному интервалу, и даже последовательное сканирование выполняется довольно быстро, так как оценка предикатов идентификаторов устройств или минимальных/максимальных временных меток не требует распаковки. Затем исполнитель запроса распаковывает только столбцы отметки времени и температуры, соответствующие этим выбранным строкам.
Эта возможность поддерживается встроенной структурой планировщика заданий TimescaleDB. Ранее мы использовали его для различных задач управления жизненным циклом данных, таких как политики хранения данных, изменение порядка данных и непрерывное агрегирование. Теперь мы используем его для асинхронного преобразования последних данных из несжатой формы на основе строк в эту сжатую форму столбцов в фрагментах гипертаблиц TimescaleDB: как только фрагмент станет достаточно старым, фрагмент будет транзакционно преобразован из строки в форму столбца.
Производительность запросов
Краткий обзорВ этот момент можно было бы задать один логичный вопрос: «Как сжатие влияет на производительность запросов?»
Мы обнаружили, что сжатие также приводит к немедленному повышению производительности для многих типов запросов. Чем больше данных помещается в меньшее пространство, тем меньше страниц диска (со сжатыми данными) необходимо прочитать для ответа на запросы.
Учитывая длину этого поста, мы подробно рассмотрим производительность запросов в другом, следующем посте блога, в том числе рассмотрим производительность для запросов, как касающихся диска, так и для доступа к данным в памяти, а также для рабочих нагрузок DevOps и IoT.
А пока мы решили показать результаты.
Тесты производительности запросов
Мы используем набор тестов временных рядов (TSBS) с открытым исходным кодом, в котором TimescaleDB работает на облачных виртуальных машинах с удаленным хранилищем SSD (в частности, типы инстансов Google Cloud n1-highmem-8 с 8 ВЦП и 52 ГБ памяти с использованием как локальный твердотельный накопитель NVMe, так и удаленный жесткий диск).
В этом наборе запросов мы уделяем особое внимание производительности, связанной с диском, с которой часто приходится сталкиваться при выполнении более специальных или рандомизированных запросов к большим наборам данных; в каком-то смысле эти результаты служат «худшим случаем» по сравнению с «теплыми» данными, которые, возможно, уже кэшированы в памяти. Для этого мы позаботились о том, чтобы все запросы выполнялись к данным, находящимся на диске, чтобы подсистема виртуальной памяти ОС еще не кэшировала дисковые страницы в памяти.
Как видно из приведенной ниже таблицы (в которой указано среднее значение 10 испытаний для двух экспериментальных установок, в одной из которых используется локальный твердотельный накопитель, а в другой — удаленный жесткий диск для хранения), практически все запросы TSBS выполняются быстрее при собственном сжатии.
| Типы запросов | ||||||
| Холодные запросы (от TSBS) | Несжатый (мс/запрос) | Сжатый (мс/запрос) | Соотношение | Несжатый (мс/запрос) | Сжатый (мс/запрос) | Соотношение |
| процессор-макс-все-1 | 42. 517 | 42.314 | 1,00 | 814.863 | 383,698 | 2,12 |
| процессор-макс-все-8 | 46.657 | 40.342 | 1,16 | 2987,42 | 1779.795 | 1,68 |
| группа по заказу по лимиту | 1373.309 | 6065.812 | 0,23 | 95202.022 | 6178.808 | 15.41 |
| высокопроизводительный процессор-1 | 46.657 | 40.342 | 1,16 | 1033.286 | 482.911 | 2,14 |
| высокопроизводительный процессор-все | 3551.953 | 8084.623 | 0,44 | 53995.25 | 8180.856 | 6,60 |
| одиночная группа по 1-1-12 | 49. 546 | 38,46 | 1,29 | 1058.517 | 293,941 | 3,60 |
| одиночная группа по 1-1-1 | 33,54 | 25.695 | 1,31 | 286.307 | 234.785 | 1,22 |
| одиночная группа по-1-8-1 | 50.805 | 40.495 | 1,25 | 995.306 | 598,26 | 1,66 |
| одиночная группа по 5-1-12 | 49.406 | 42.013 | 1,18 | 1083.432 | 432.758 | 2,50 |
| одиночная группа по 5-1-1 | 30.734 | 27.674 | 1.11 | 278.793 | 241 537 | 1,15 |
| одиночная группа по 5-8-1 | 45,91 | 43. 002 | 1,07 | 1000.578 | 627,39 | 1,59 |
| двойная группа-1 | 5925.591 | 1823.033 | 3,25 | 56676.155 | 1986.937 | 28,52 |
| двойная группа по 5 | 7568.038 | 2980.089 | 2,54 | 62681.04 | 2915.941 | 21.50 |
| двойная группа по всем | 9286.914 | 4399.367 | 2.11 | 65202.448 | 4257.638 | 15.31 |
| последняя точка | 1674,194 | 264.666 | 6,33 | 37998.325 | 539.368 | 70,45 |
В приведенной выше таблице указана задержка «холодных» запросов TSBS DevOps к TimescaleDB со всеми данными, находящимися на диске, как для несжатых, так и для сжатых данных. «Улучшение» определяется как «задержка несжатого запроса / задержка сжатого запроса».
Тем не менее, можно создавать запросы, которые работают медленнее со сжатыми данными. В частности, сжатие TimescaleDB в настоящее время ограничивает типы индексов, которые можно построить на основе сжатых данных; в частности, b-деревья могут быть построены только на основе сегментированных столбцов. Но на практике мы обнаруживаем, что запросы, которые были бы быстрее с этими индексами, как правило, встречаются редко (например, они также требуют большого количества отдельных проиндексированных элементов, так что любой элемент отсутствует на большинстве страниц диска).
Ограничения и работа в будущем
Первоначальный выпуск встроенного сжатия TimescaleDB является довольно мощным, с пользовательскими расширенными алгоритмами сжатия для различных типов данных и реализуется через нашу непрерывную асинхронную структуру планирования. Кроме того, у нас уже запланированы некоторые улучшения, например, улучшенное сжатие данных JSON.
Одно из основных ограничений нашего первоначального выпуска версии 1.5 заключается в том, что после преобразования фрагментов в форму сжатого столбца в настоящее время мы не разрешаем дальнейшие модификации данных (например, вставки, обновления, удаления) без ручной распаковки. Другими словами, куски неизменяемы в сжатой форме. Попытки изменить данные чанков либо завершатся ошибкой, либо пропадут молча (по желанию пользователя).
Тем не менее, учитывая, что рабочие нагрузки временных рядов в основном вставляют (или реже обновляют) последние данные, это гораздо меньшее ограничение для временных рядов, чем для варианта использования без временных рядов. Кроме того, пользователи могут настроить возраст фрагментов до того, как они будут преобразованы в эту сжатую столбчатую форму, что обеспечивает гибкость для умеренно неупорядоченных данных или во время запланированной обратной засыпки. Пользователи также могут явно распаковывать фрагменты перед их изменением. Мы также планируем ослабить/удалить это ограничение в будущих выпусках.
Резюме
Мы очень рады этой новой возможности и тому, как она обеспечит большую экономию средств, производительность запросов и масштабируемость хранилища для TimescaleDB и нашего сообщества.
Как мы упоминали выше, если вы заинтересованы в том, чтобы попробовать собственное сжатие сегодня, вы можете установить TimescaleDB или обновить текущую развертывание TimescaleDB. Если вы ищете полностью управляемый размещенный вариант, мы рекомендуем вам ознакомиться с управляемой службой для TimescaleDB (мы предлагаем бесплатную 30-дневную пробную версию). Вы также можете подписаться на наш предстоящий веб-семинар «Как снизить общую стоимость владения базой данных с помощью TimescaleDB», чтобы узнать больше.
За последние пару месяцев мы анонсировали как масштабируемую кластеризацию, так и собственное сжатие для TimescaleDB. В совокупности они помогают реализовать наше видение TimescaleDB как мощной, производительной и экономичной платформы для данных временных рядов, от малых до очень больших, от периферии до облака.
Мы все неоднократно слышали ошибочное представление о том, что для достижения необходимого масштаба, производительности и эффективности необходимо пожертвовать SQL, реляционными возможностями, гибкостью запросов и моделей данных, а также закаленной в боях надежностью и надежностью баз данных временных рядов. . Точно так же мы все слышали скептицизм в отношении PostgreSQL: хотя PostgreSQL является прекрасной и надежной базой данных, он не может работать с данными временных рядов.
С помощью TimescaleDB 1.5 мы продолжаем опровергать эти представления и демонстрируем, что благодаря целенаправленному подходу и разработке проблем с данными временных рядов не нужно идти на эти компромиссы.
Если у вас есть данные временных рядов, попробуйте последнюю версию TimescaleDB. Мы приветствуем ваши отзывы. И вместе давайте создадим единственную базу данных временных рядов, которая не заставит вас идти на трудные компромиссы. Давай, возьми свой торт и съешь его тоже.
Реляционная база данных с открытым исходным кодом для временных рядов и аналитики.
Попробуйте шкалу времени бесплатно
столбчатых деревьев | Deborah Silver & Co.
Любой ландшафт основан на ограниченном пространстве. Собственность может быть описана определенным количеством квадратных метров на плоскости земли. Пейзаж состоит из множества различных элементов, самым крупным из которых является небо. Далее деревья. Я предполагаю, что небольшая городская собственность может быть покрыта лесом, как лесной массив, но это предполагает, что садовник имеет в виду только одно использование своего ландшафта. К счастью, деревья бывают всех размеров и форм. Ряд деревьев имеют фастигиатную или столбчатую форму. Это означает именно то, что подразумевает это слово. Листва или иглы растут естественно в столбце. Дерево с ограниченным размахом — отличный выбор для небольших садов, для садов, требующих экранирования, и для садов, требующих естественного декора. Много лет назад этот боковой сад был на виду у соседнего дома. Сегодня все, что осталось от этого вида, — это дымоход. Расположение пар столбчатых грабов создало естественную беседку, в которой есть тенистая зона отдыха.
Мой первый визит в этот дом сразу же натолкнул меня на мысль о столбчатых деревьях. Задний двор очень маленький, а соседние дома очень близко. Отличительная черта двора — красиво построенная стена. У стены насыпали землю, а у ее основания посадили самшит. Перед кроватью коллекция многолетников. Самшит и многолетники скорее заслоняли стену, чем украшали ее, и они не могли обеспечить экран от соседнего дома. Завеса болиголова на заднем дворе истончилась и стала очень широкой в нижней части, где в ней не было особой необходимости.
Эти столбчатые клены Боухолл в конечном итоге полностью скроют стену гаража соседа от глаз. Снижение уровня означало, что для просмотра была доступна гораздо большая часть стены. Болиголов был заменен Thuja Nigra, туей, которая становится узкой и высокой. Очень маленький двор теперь полностью частный, учитывая посадку высоких деревьев. Клены занимают только воздушное пространство; их шестоподобные стволы не занимают места. Туи узкие как снизу, так и сверху. Это помогает сделать очень маленькое пространство просторным.
Этот задний двор круто спускался к основанию дома; вода в подвале была проблемой. Подпорная стена позволяла отделить почву на уровне земли от дома. Верх стены был засажен грабами, расположенными на расстоянии 12 футов друг от друга; они срастутся быстрее, чем вы думаете. Carpinus fastigiata от природы имеет широкояйцевидную форму, но вполне терпим к обрезке. Гортензии сделают ожидание роста деревьев немного более терпимым. Будет интересно посмотреть, какое направление хочет выбрать клиент с обрезкой. У них есть время разобраться с этим. Стена также давала деревьям небольшую опору, отгораживая соседний участок.
Туи имеют естественную столбчатую форму, но они также хорошо адаптируются к более тесной обрезке. Этот пейзаж требовал вертикального элемента, который не затенял бы окружающие растения. Обрезка один раз в год — это все, что нужно для поддержания формы.
В этом ландшафте присутствуют как подрезанные, так и необрезанные туи. Обрезанные цилиндрические формы очень интересны и скульптурны. Обрезка любого дерева или вечнозеленого растения должна проводиться с течением времени. Моим сиреневым палабинам потребовалось стандартные 2 года, чтобы оправиться от шока, вызванного моим припадком полларда.
Есть такие деревья, которые от природы не особо колонновидные, но поддаются обрезке. Гибрид магнолии Ivory Chalice, гибрид магнолии остроконечной и магнолии денудата, был обрезан, чтобы оставаться в пределах этого очень узкого пространства вдоль подъездной дорожки. Они счастливы здесь уже более 10 лет.
Populus tremuloides erecta , или шведский колонновидный тополь, представляет собой свободно растущее колонновидное дерево, которое в конечном итоге защитит гигантские окна этого современного дома. Округлые и зубчатые листья развеваются на ветру, как и любой другой мак, а осенняя окраска великолепна. У этого дерева иногда может быть отвалившаяся ветка — небольшая обрезка исправит это. Даже старые деревья не намного шире, чем 5 или 6 футов.