Фундаменты столбчатые серия: Библиотека государственных стандартов
Фундаменты железобетонные столбчатые. Серия 1.820.9-1
Производство ЖБИ » Общегражданское строительство » Фундаментные блоки » Фундаменты железобетонные столбчатые. Серия 1.820.9-1
| Наименование изделия | Длина, мм | Ширина, мм | Высота, мм | Масса, кг |
| Фундамент Ф16.15.9-Т | 1600 | 900 | 1500 | 1770 |
| Фундамент Ф19.18.9-Т | 1900 | 900 | 1800 | 2400 |
| Свая СВТ30.5-П | 3000 | 950 | 500 | 1220 |
| Свая СВТ40.5-П | 4000 | 950 | 500 | 1460 |
| Стенка ограждающая ПС45.8-П | 4500 | 800 | 80 | 720 |
| Стенка ограждающая ПС45.6-П | 4500 | 600 | 80 | 500 |
| Стенка ограждающая ПС45.7-П | 4500 | 700 | 80 | 600 |
В современном общегражданском строительстве используются фундаменты железобетонные столбчатые.
Изделия по серии 1.820.9-1 — это монолитные конструкции, представляющие собой высокопрочные несущие элементы, которые используются при строительстве таких сооружений, как склады минеральных удобрений, имеющие пролеты 24 метра. Вместимость таких сооружений под складские объекты может быть от 3,5 до 20 тысяч т. В производстве изделий используются качественные материалы и конструкция надёжно армируется, благодаря чему получаются высокопрочные блоки для строительства стен, находящиеся под большими вертикальными нагрузками, в том числе под динамическими ударами, сжатием, изгибающим нагрузками и растяжениями. Такая особая форма блоков позволяет смонтировать изделия в кратчайшие сроки.
Серия 1.820.9-1 включает выпуск 1, где представлены фундаменты железобетонные столбчатые, а также забивные тавровые сваи СВТ и изделия ограждающей стенки типа ПС.
Железобетонные изделия по серии 1.820.9-1 выбираются в зависимости от таких параметров как: назначение, несущая способность, высота и других условий применения:
- ПС — стенка ограждающая
- СВТ — свая таврового сечения
- Ф — фундамент столбчатый
Стенки ограждающие предназначаются для разделения на части складских помещения. Изделия обеспечивают необходимую прочность и устойчивость всему сооружению.
Изделия обеспечивают необходимую прочность и устойчивость всему сооружению.
Забивные сваи передают на грунт нагрузки от свайных фундаментов. Железобетонные сваи с сечением тавровой формы с заостренной головой, предназначены для прорезания грунта. Изделия погружается в грунт при помощи свайных молотов, вибропогружателей или вибровдавливающих агрегатов.
Сборные фундаменты под колонны образуются двумя плитами, которые укладываются друг на друга и цементируются раствором. Выбор размеров блоков принимается с учетом предполагаемой глубины фундамента. Фундаменты обладает высокими прочностными характеристиками, блоки просты и удобны для строительно-монтажных работ.
Изделия применяются в районах со средней температуры ниже -40°С в районах с сейсмичностью до 6 баллов.
Блоки изготавливаются из бетона классом прочности на сжатие — В25, морозостойкостью — F200, водонепроницаемостью — W6.
Современные комплексы добавок и присадок позволяют получать ЖБИ и с более высокими техническими характеристиками предотвращающим разрушение бетона в процессе эксплуатации в суровых условиях
Армирующая конструкция изготавливается из стержневой арматуры класса A-IIIв или A-I по ГОСТ 5781-61, также применяется холоднотянутая проволока марки B-I по ГОСТ 6727-53.
Фундаменты железобетонные столбчатые имеют поверхность без раковин, наплывов, сколов и расслоений. В компании Завод строительных конструкций «Союз» вы можете заказать железобетонные изделия высокого заводского качества.
Производство на основе предписаний нормативной документации позволяет достигать высокого качества готовых материалов для успешного и эффективного использования в строительстве. Входящее в состав изделий сырье обеспечивает прочность и долговечность возводимых промышленных зданий. Все металлические закладные детали проходят противокоррозионную обработку в заводских условиях в соответствии с рекомендациями нормативного документа.
На заключительных стадиях производства партии готовых промаркированных изделий проходят через комплекс приемо-сдаточных испытаний, направленных на то, чтобы выявить все имеющиеся недостатки и выбраковать недостаточно качественную для эксплуатации продукцию.
Мы поставляем заказчикам продукцию, на которую предоставляется гарантии на ЖБИ и необходимые технические паспорта.
Цены на железобетонные изделия можете узнать, обратившись в наши представительства. Стоимость железобетонных изделий может меняться в зависимости от объема и общей ситуации на строительном рынке.
Купить фундаменты железобетонные столбчатые вы можете в наших представительствах в Санкт-Петербурге в Москве Екатеринбурге и Красноярске.
Энциклопедия индивидуального застройщика
|
| ||||||
2007-2018, NskDom. разработка: Костиков Михаил | |||||||
| Поиск | Обратная связь | Карта сайта |

 12; ФЛ 14.12; ФЛ 16.12. Для опирания стен чаще всего используются типовые несущие перемычки или фундаментные балки.
12; ФЛ 14.12; ФЛ 16.12. Для опирания стен чаще всего используются типовые несущие перемычки или фундаментные балки.
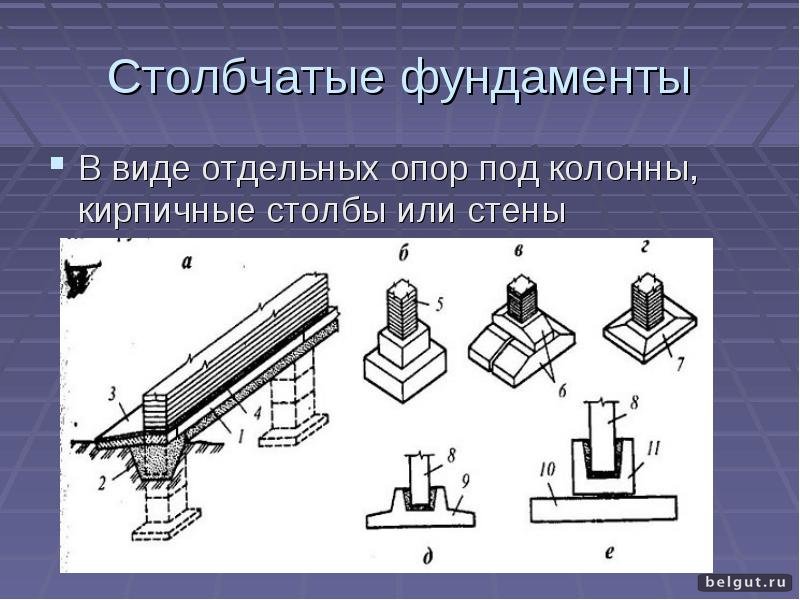
 Если столбы выполнять монолитными в инвентарной опалубке, уменьшив их сечение вдвое по сравнению со сборными
Если столбы выполнять монолитными в инвентарной опалубке, уменьшив их сечение вдвое по сравнению со сборными
 Применение сборных столбчатых фундаментов на площадках с неоднородными, сжимаемыми или пучинистыми грунтами без специальных конструктивных мероприятий не рекомендуется.
Применение сборных столбчатых фундаментов на площадках с неоднородными, сжимаемыми или пучинистыми грунтами без специальных конструктивных мероприятий не рекомендуется.
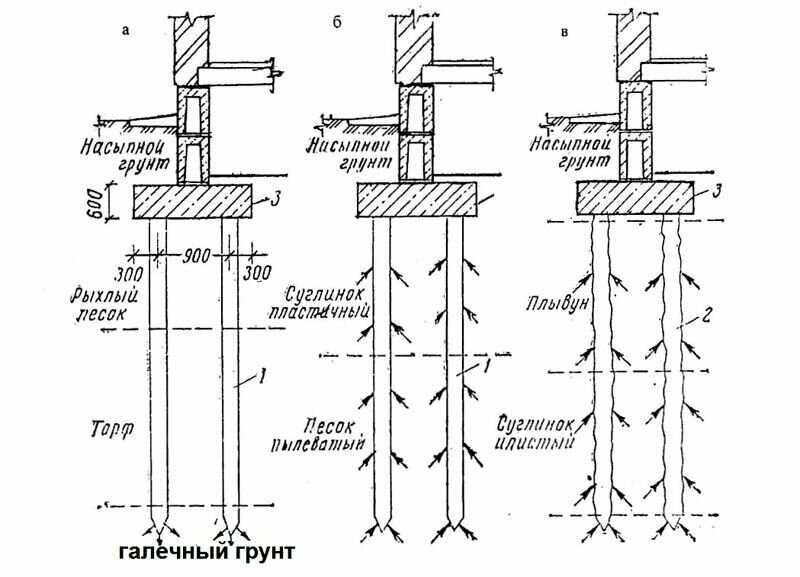
 С помощью этого станка выполняются также скважины с уширением до 3,5 м для устройства монолитных столбчатых фундаментов. Как показал опыт, применение буровых машин более чем вдвое сокращает продолжительность работ нулевого цикла. Преимуществом такого метода является возможность выполнения земляных работ круглогодично, так как бурильная машина способна разрабатывать и мерзлый грунт.
С помощью этого станка выполняются также скважины с уширением до 3,5 м для устройства монолитных столбчатых фундаментов. Как показал опыт, применение буровых машин более чем вдвое сокращает продолжительность работ нулевого цикла. Преимуществом такого метода является возможность выполнения земляных работ круглогодично, так как бурильная машина способна разрабатывать и мерзлый грунт.
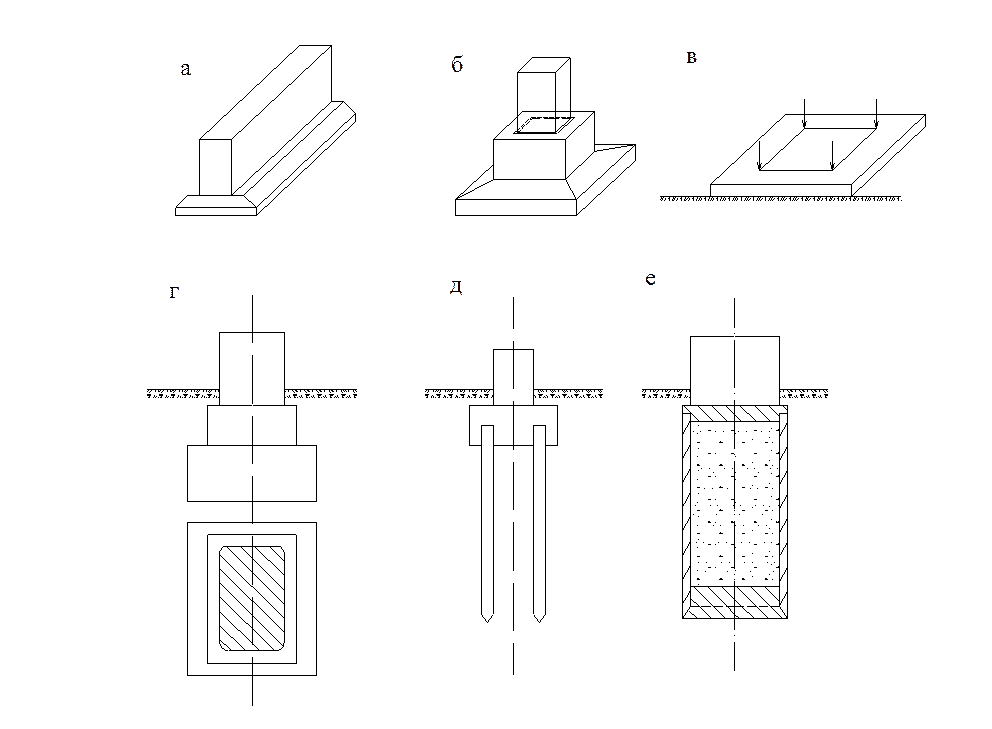
 см-6,0 кгс/кв.см.
см-6,0 кгс/кв.см.
 хорш Культиваторы Horsch Tiger MT, Агросоюз, Универсальный пневматический посевной комплекс «PonТerrа» Союз-Спецтехника, АСК, Промагро, Кедр. Ширина захвата: 375мм, вес: 3.5 кг, твердость упрочненного слоя 52 HRC.
хорш Культиваторы Horsch Tiger MT, Агросоюз, Универсальный пневматический посевной комплекс «PonТerrа» Союз-Спецтехника, АСК, Промагро, Кедр. Ширина захвата: 375мм, вес: 3.5 кг, твердость упрочненного слоя 52 HRC.  Вы получите лучшую автоматику для ворот (откатных, промышленных, гаражных, распашных) от лучших мировых брендов CAME, AN-Motors, KingGates, Doorhan и другие по стоимости производителя. Качественный монтаж (подключение), регулировку и персональное обучение. Бесплатную помощь и консультацию в подборе.
Вы получите лучшую автоматику для ворот (откатных, промышленных, гаражных, распашных) от лучших мировых брендов CAME, AN-Motors, KingGates, Doorhan и другие по стоимости производителя. Качественный монтаж (подключение), регулировку и персональное обучение. Бесплатную помощь и консультацию в подборе. ru
ruПостроение сжатия по столбцам в базе данных, ориентированной на строки
Как мы добились сжатия 91%-96% в последней версии TimescaleDB
Сегодня мы рады объявить о новой собственной возможности сжатия для TimescaleDB, временного ряда БД на PostgreSQL. Эта новая функция, которая находилась в закрытом бета-тестировании в течение нескольких месяцев, использует лучшие в своем классе алгоритмы сжатия, а также новый метод создания гибридного хранилища строк и столбцов. Во время нашего бета-тестирования мы приглашали членов сообщества попробовать его и оставить нам отзыв, и в результате сейчас мы видим до 9Коэффициент сжатия без потерь 6% для различных реальных и смоделированных рабочих нагрузок временных рядов.
В этом выпуске размер хранилища TimescaleDB теперь сопоставим со специально созданными и более ограниченными хранилищами NoSQL — без ущерба для наших уникальных возможностей. TimescaleDB по-прежнему предлагает полноценный SQL, реляционные JOIN и функции, мощные возможности автоматизации, а также надежность и огромную экосистему, основанную на использовании основы PostgreSQL. Мы знаем, что хранилище могло быть ограничивающим фактором для некоторых людей, заинтересованных в TimescaleDB в прошлом, но мы рекомендуем вам попробовать собственное сжатие и сообщить нам, что вы думаете.
TimescaleDB по-прежнему предлагает полноценный SQL, реляционные JOIN и функции, мощные возможности автоматизации, а также надежность и огромную экосистему, основанную на использовании основы PostgreSQL. Мы знаем, что хранилище могло быть ограничивающим фактором для некоторых людей, заинтересованных в TimescaleDB в прошлом, но мы рекомендуем вам попробовать собственное сжатие и сообщить нам, что вы думаете.
TimescaleDB достигает такой степени сжатия за счет использования лучших в своем классе алгоритмов сжатия различных типов данных. Мы используем следующие алгоритмы (и позволим пользователям выбрать алгоритм в будущих выпусках):
- Сжатие Gorilla для чисел с плавающей запятой подобные типы
- Сжатие словаря всей строки для столбцов с несколькими повторяющимися значениями (+ сжатие LZ сверху)
- Сжатие массива на основе LZ для всех остальных типов
Мы расширили Gorilla и Simple-8b для обработки распаковки данных в обратном порядке, что позволяет нам ускорить запросы, использующие обратное сканирование. Для супер технических подробностей, пожалуйста, смотрите наш пресс-релиз по компрессии.
Для супер технических подробностей, пожалуйста, смотрите наш пресс-релиз по компрессии.
(Мы обнаружили, что это типоспецифичное сжатие достаточно мощное: в дополнение к более высокой сжимаемости, некоторые методы, такие как Gorilla и дельта-дельта, могут быть до 40 раз быстрее, чем сжатие на основе LZ во время декодирования, что приводит к значительному снижению производительности. улучшенная производительность запросов.)
В будущем мы планируем предоставить расширенные алгоритмы для других собственных типов, таких как данные JSON, но даже сегодня, используя описанные выше подходы, все типы данных PostgreSQL могут использоваться в собственном сжатии TimescaleDB.
Встроенное сжатие (и TimescaleDB 1.5) сегодня широко доступно для загрузки по всем нашим каналам распространения, включая Managed Service for TimescaleDB. Эта возможность выпущена под нашей лицензией Timescale Community (поэтому ее можно использовать совершенно бесплатно).
Базы данных, ориентированные на строки и столбцы
Традиционно базы данных относятся к одной из двух категорий: базы данных, ориентированные на строки, и базы данных, ориентированные на столбцы (они же «столбцы»).
Вот пример: Допустим, у нас есть таблица, в которой хранятся следующие данные для 1 млн пользователей: user_id, name, # logins, last_login . Таким образом, у нас фактически есть 1 миллион строк и 4 столбца. Хранилище данных, ориентированное на строки, будет физически хранить данные каждого пользователя (т. е. каждую строку) на диске непрерывно. Напротив, хранилище столбцов будет хранить все user_id вместе, все имена вместе и так далее, так что данные каждого столбца будут храниться на диске непрерывно.
В результате поверхностные и широкие запросы будут выполняться быстрее в хранилище строк (например, «извлечь все данные для пользователя X»), а глубокие и узкие запросы будут выполняться быстрее в хранилище столбцов (например, « рассчитать среднее количество входов в систему для всех пользователей»).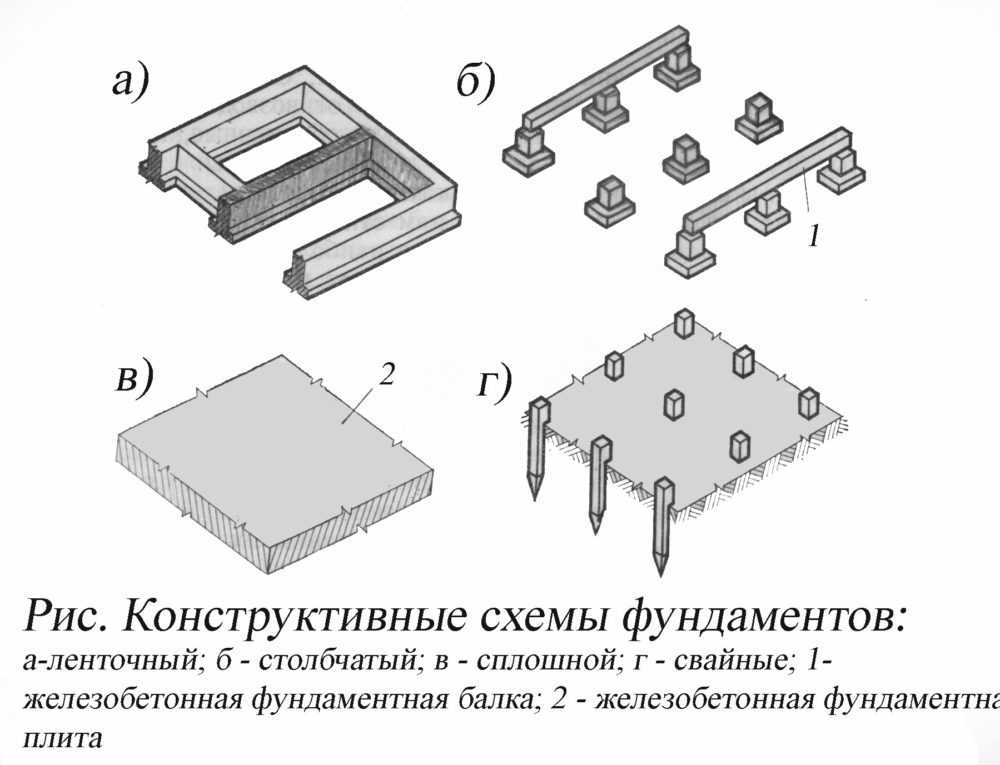
В частности, хранилища столбцов очень хорошо справляются с узкими запросами к очень большим данным. При таком хранилище необходимо считывать с диска только указанные столбцы (вместо того, чтобы загружать страницы данных с диска со всеми строками, а затем выбирать один или несколько столбцов только в памяти).
Кроме того, поскольку отдельные столбцы данных обычно имеют один и тот же тип и часто берутся из более ограниченной области или диапазона, они обычно сжимаются лучше, чем целая широкая строка данных, содержащая множество различных типов данных и диапазонов. Например, наш столбец количества входов в систему будет иметь целочисленный тип и может охватывать небольшой диапазон числовых значений.
Тем не менее, магазины в виде колонн не обходятся без компромиссов. Во-первых, вставки занимают гораздо больше времени: системе нужно разбить каждую запись на соответствующие столбцы и соответствующим образом записать ее на диск. Во-вторых, хранилищам на основе строк проще использовать индекс (например, B-дерево) для быстрого поиска подходящих записей.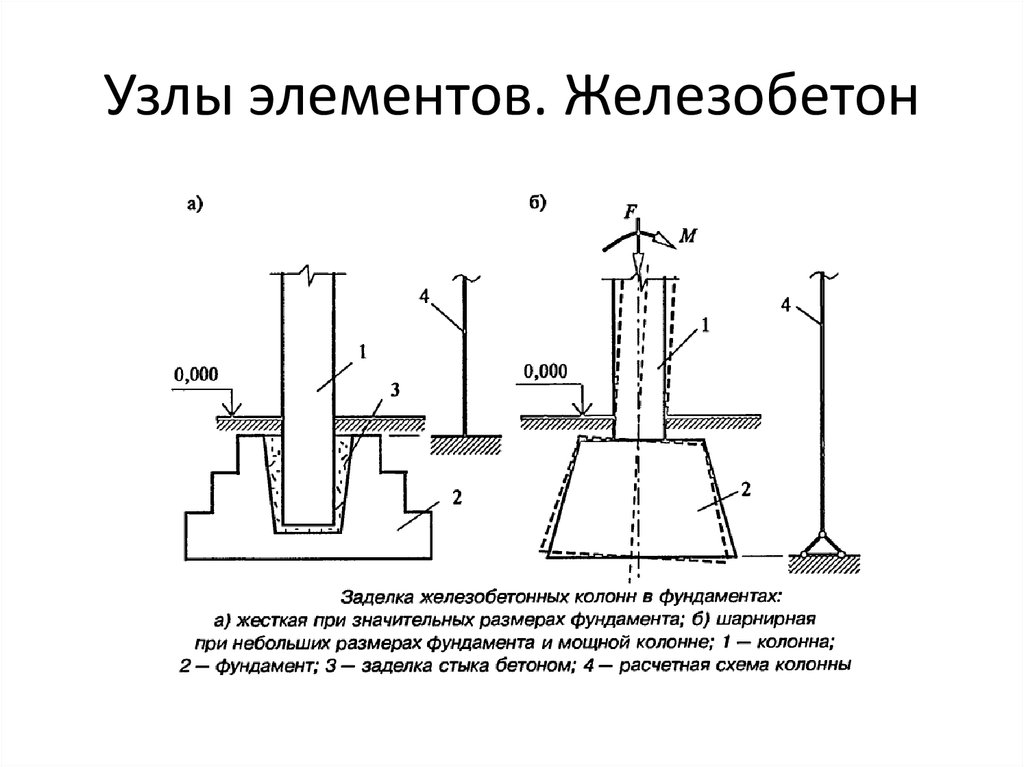 В-третьих, с помощью хранилища строк легче нормализовать набор данных, чтобы вы могли более эффективно хранить связанные наборы данных в других таблицах.
В-третьих, с помощью хранилища строк легче нормализовать набор данных, чтобы вы могли более эффективно хранить связанные наборы данных в других таблицах.
В результате выбор между базой данных, ориентированной на строки, и базой данных, ориентированной на столбцы, сильно зависит от вашей рабочей нагрузки. Как правило, хранилища, ориентированные на строки, используются с транзакционными (OLTP) рабочими нагрузками, а хранилища по столбцам — с аналитическими (OLAP) рабочими нагрузками.
Но рабочие нагрузки временных рядов уникальны
Если вы раньше работали с данными временных рядов, вы знаете, что рабочие нагрузки уникальны во многих отношениях:
- Запросы временных рядов могут быть отдельный запрос обращается ко многим столбцам данных, а также к данным на многих различных устройствах/серверах/элементах. Например, « Что происходит в моем развертывании за последние K минут? »
- Запросы временных рядов также могут быть глубокими и узкими, когда отдельный запрос выбирает меньшее количество столбцов для определенного устройства/сервера/элемента за более длительный период времени.
 Например, « Какова средняя загрузка ЦП для этого сервера за последние 24 часа? ”
Например, « Какова средняя загрузка ЦП для этого сервера за последние 24 часа? ” - Рабочие нагрузки временных рядов обычно требуют большого количества вставок. Скорость вставки в сотни тысяч операций записи в секунду является нормальной.
- Наборы данных временных рядов также очень детализированы, эффективно собирая данные с более высоким разрешением, чем OLTP или OLAP, что приводит к гораздо большим наборам данных. Терабайты данных временных рядов также вполне нормальны.
 Например, « Какова средняя загрузка ЦП для этого сервера за последние 24 часа? ”
Например, « Какова средняя загрузка ЦП для этого сервера за последние 24 часа? ” В результате оптимальное хранилище временных рядов должно:
- Поддерживать высокую скорость вставки, легко достигающую сотен тысяч операций записи в секунду
- Эффективно обрабатывать как мелкие и широкие, так и глубокие и узкие запросы в этом большом наборе данных
- Эффективно хранить, т. е. сжимать, этот большой набор данных, чтобы он был управляемым и экономически эффективным
Именно это мы сделали с последней версией TimescaleDB.
Сочетание лучшего из обоих миров
Архитектура TimescaleDB представляет собой базу данных временных рядов, построенную на основе PostgreSQL. При этом он унаследовал все лучшее, что есть в PostgreSQL: полноценный SQL, огромную гибкость запросов и моделей данных, проверенную в боевых условиях надежность, активную и усердную базу разработчиков и пользователей, а также одну из крупнейших экосистем баз данных.
Но низкоуровневое хранилище TimescaleDB использует ориентированный на строки формат хранения PostgreSQL, который добавляет скромные накладные расходы на каждую строку и снижает сжимаемость, поскольку непрерывные значения данных имеют множество различных типов — строки, целые числа, числа с плавающей запятой и т. д. — и взяты из разных диапазонов. И сам по себе PostgreSQL на сегодняшний день не предлагает никакого встроенного сжатия (за исключением очень больших объектов, хранящихся на их собственных «TOAST-страницах», которые неприменимы для большей части контента).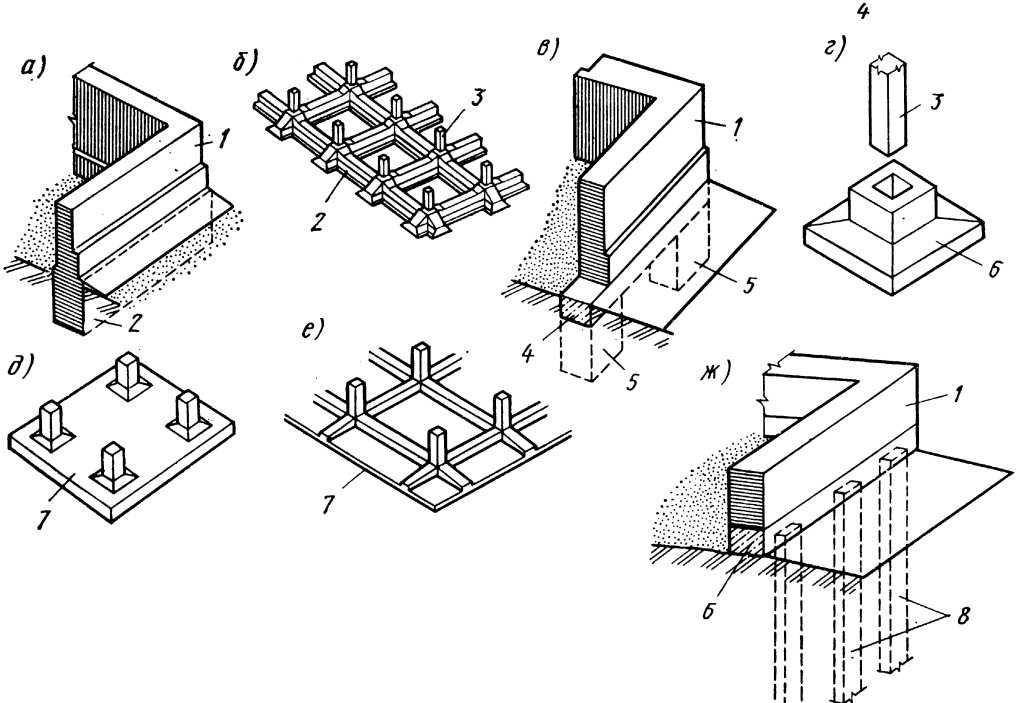
В качестве альтернативы некоторые пользователи запускают TimescaleDB в сжатой файловой системе, такой как ZFS или BTRFS, для экономии места на диске, часто в режиме 3x-9.х диапазон. Но это приводит к некоторым проблемам развертывания, учитывая, что это внешняя зависимость, и на ее сжимаемость по-прежнему влияет ориентированный на строки характер базовой базы данных (поскольку данные сопоставляются со страницами диска).
Теперь, с TimescaleDB 1.5, мы смогли объединить лучшее из обоих миров: (1) все преимущества PostgreSQL, включая производительность вставки и производительность поверхностных и широких запросов для последних данных из хранилища строк, в сочетании с (2) сжатием и дополнительной производительностью запросов — чтобы гарантировать, что мы только читать сжатые столбцы, указанные в запросе — для глубоких и узких запросов хранилища столбцов.
Вот результаты.
Результаты: экономия пространства на уровне 91-96 % (по данным независимого бета-тестирования)
Перед выпуском мы попросили некоторых членов сообщества и существующих клиентов TimescaleDB провести бета-тестирование новых функций сжатия с некоторыми из их реальных наборов данных, а также как проверенное сжатие по наборам данных Time-Series Benchmarking Suite.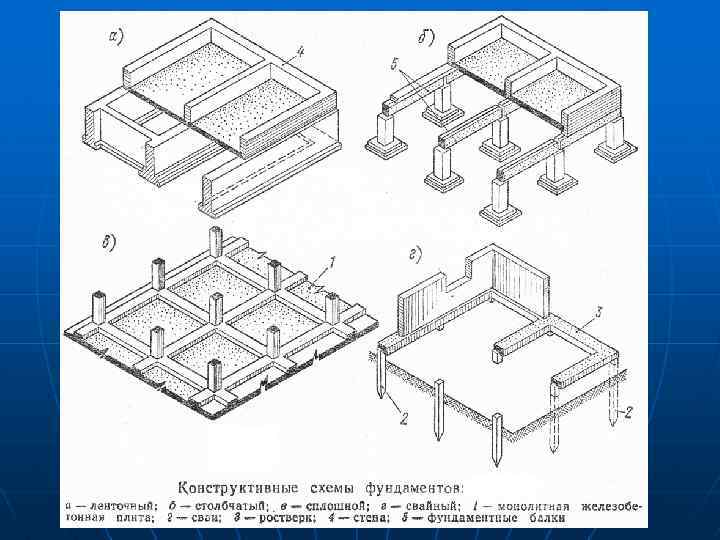
Ниже приведены результаты, которые включают тип рабочей нагрузки, общее количество несжатых байтов, сжатые байты (размер, который они увидели после сжатия) и экономию при сжатии. И эта экономия только при кодировании без потерь для сжатия.
| Рабочая нагрузка | Несжатый | Сжатый | Экономия на хранении |
| Показатели ИТ (от бета-тестера Telco) | 1396 ГБ | 77,0 ГБ | 94% экономии |
| Данные мониторинга промышленного IoT (из бета-тестера) | 1,445 ГБ | 0,077 ГБ | 95% экономии |
| Показатели ИТ (набор данных DevOps из TSBS) | 125 ГБ | 5,5 ГБ | 96% экономии |
| Данные мониторинга IoT (набор данных IoT из TSBS) | 251 ГБ | 23,8 ГБ | Экономия 91% |
«Коэффициент сжатия невероятно высок :)» — Тамихиро Ли, сетевой инженер, Sakura Internet
Дополнительные результаты: экономия затрат и более быстрые запросы
Но такое сжатие не только академическое, оно дает два реальных преимущества:
- Стоимость. Хранение в масштабе стоит дорого. Дисковый том объемом 10 ТБ в облаке сам по себе стоит более 12 000 долларов США в год (из расчета 0,10 долларов США/ГБ/месяц для хранилища AWS EBS), а дополнительные реплики высокой доступности и резервные копии могут увеличить эту цифру еще в 2–3 раза. Достижение 9Хранилище 5 % может сэкономить вам более 10 000 – 25 000 долларов США в год только на расходах на хранение (например, 12 000 $/10 ТБ * 10 ТБ/машина * 2 машины [один мастер и одна реплика] * экономия 95 % = 22,8 000 $ ) .
- Производительность запроса. Сжатие приводит к немедленному повышению производительности для многих типов запросов. Чем больше данных помещается в меньшем пространстве, тем меньше страниц диска (со сжатыми данными) необходимо прочитать для ответа на запросы. (Ниже приведен краткий обзор бенчмаркинга, а более подробное описание будет в следующем посте.)
 Хранение в масштабе стоит дорого. Дисковый том объемом 10 ТБ в облаке сам по себе стоит более 12 000 долларов США в год (из расчета 0,10 долларов США/ГБ/месяц для хранилища AWS EBS), а дополнительные реплики высокой доступности и резервные копии могут увеличить эту цифру еще в 2–3 раза. Достижение 9Хранилище 5 % может сэкономить вам более 10 000 – 25 000 долларов США в год только на расходах на хранение (например, 12 000 $/10 ТБ * 10 ТБ/машина * 2 машины [один мастер и одна реплика] * экономия 95 % = 22,8 000 $ ) .
Хранение в масштабе стоит дорого. Дисковый том объемом 10 ТБ в облаке сам по себе стоит более 12 000 долларов США в год (из расчета 0,10 долларов США/ГБ/месяц для хранилища AWS EBS), а дополнительные реплики высокой доступности и резервные копии могут увеличить эту цифру еще в 2–3 раза. Достижение 9Хранилище 5 % может сэкономить вам более 10 000 – 25 000 долларов США в год только на расходах на хранение (например, 12 000 $/10 ТБ * 10 ТБ/машина * 2 машины [один мастер и одна реплика] * экономия 95 % = 22,8 000 $ ) .Дальнейшие действия
Собственное сжатие сегодня широко доступно в TimescaleDB 1. 5. Вы можете либо установить TimescaleDB, либо обновить текущее развертывание TimescaleDB. Если вы ищете полностью управляемый размещенный вариант, мы рекомендуем вам ознакомиться с управляемой службой для TimescaleDB (мы предлагаем бесплатную 30-дневную пробную версию).
5. Вы можете либо установить TimescaleDB, либо обновить текущее развертывание TimescaleDB. Если вы ищете полностью управляемый размещенный вариант, мы рекомендуем вам ознакомиться с управляемой службой для TimescaleDB (мы предлагаем бесплатную 30-дневную пробную версию).
Мы также рекомендуем вам подписаться на наш предстоящий веб-семинар «Как снизить общую стоимость владения базой данных с помощью TimescaleDB», чтобы узнать больше.
Теперь, если вы хотите узнать больше о забавных технических деталях — о построении колоночного хранилища в системах на основе строк, индексации и запросах к сжатым данным, а также о некоторых тестах — пожалуйста, продолжайте читать.
Все заслуги в этих результатах принадлежат нашим замечательным инженерам и менеджерам по проектам: Джошу Локерману, Гаятри Айяпану, Свену Клемму, Дэвиду Кону, Анте Крешичу, Мату Арье, Дайане Хси и Бобу Булю. (И да, мы набираем сотрудников по всему миру.)
Построение колоночного хранилища на основе построчной системы
Признавая, что рабочие нагрузки временных рядов обращаются к данным во временном порядке, наш высокоуровневый подход к построению столбцового хранилища заключается в преобразовании множества широких строк данных (скажем, 1000) в одну строку данных. Но теперь каждое поле (столбец) этой новой строки хранит упорядоченный набор данных, включающий весь столбец из 1000 строк.
Но теперь каждое поле (столбец) этой новой строки хранит упорядоченный набор данных, включающий весь столбец из 1000 строк.
Итак, рассмотрим упрощенный пример, используя таблицу со следующей схемой:
| Отметка времени | Идентификатор устройства | Код состояния | Температура |
| 12:00:01 | А | 0 | 70.11 |
| 12:00:01 | Б | 0 | 69,70 |
| 12:00:02 | А | 0 | 70.12 |
| 12:00:02 | Б | 0 | 69,69 |
| 12:00:03 | А | 0 | 70.14 |
| 12:00:03 | Б | 4 | 69,70 |
После преобразования этих данных в одну строку данные в форме «массива»:
| Отметка времени | Идентификатор устройства | Код состояния | Температура |
| [12:00:01, 12:00:01, 12:00:02, 12:00:02, 12:00:03, 12:00:03] | [А, Б, А, Б, А, Б] | [0, 0, 0, 0, 0, 4] | [70. 11, 11, 69.70, 70.12, 69.69, 70.14, 69.70] |
Даже до использования сжатия данных этот формат сразу экономит место, значительно снижая наши внутренние накладные расходы на строку. PostgreSQL обычно добавляет ~ 27 байт служебных данных на строку (например, для управления версиями MVCC). Таким образом, даже без сжатия, если наша схема выше, скажем, 32 байта, то 1000 строк данных, которые ранее занимали [1000 * (32 + 27)] ~= 59 килобайт теперь занимает [1000 * 32 + 27] ~= 32 килобайта в этом формате.
Но, учитывая формат, в котором схожие данные (временные метки, идентификаторы устройств, показания температуры и т. д.) хранятся непрерывно, мы можем применить к нему алгоритмы сжатия для конкретного типа, чтобы каждый массив сжимался отдельно.
Затем, если запрос запрашивает подмножество этих столбцов:
ВЫБРАТЬ time_bucket(‘1 minute’, timestamp) как минуту СРЕДНЯЯ (температура) ИЗ таблицы WHERE timestamp > now() - интервал «1 день» ЗАКАЗАТЬ ПО МИНУТАМ DESC СГРУППИРОВАТЬ ПО минутам
Механизм запросов может извлекать (и распаковывать во время запроса) только столбцы метки времени и температуры для вычисления и возврата этой агрегации.
Но, учитывая, что формат хранения Postgres в стиле MVCC может записывать несколько строк на одну и ту же страницу диска, как мы можем получить с диска только нужные сжатые массивы, а не более широкий набор окружающих данных? Здесь мы используем невстроенные страницы диска для хранения этих сжатых массивов, т. е. они подвергаются TOAST, так что данные в строке теперь указывают на вторичную страницу диска, на которой хранится сжатый массив (фактическая строка в основной таблице кучи становится очень маленькой). , потому что это просто указатели на данные TOAST). Таким образом, с диска загружаются только сжатые массивы для необходимых столбцов, что еще больше повышает производительность запросов за счет сокращения дискового ввода-вывода. (Помните, что каждый массив может содержать от 100 до 1000 элементов данных, а не 6, как показано.)
Индексирование и запросы к сжатым данным
Однако этот формат сам по себе имеет серьезную проблему: какие строки должна извлекать и распаковывать база данных для выполнения запроса? В приведенной выше схеме база данных не может легко определить, какие строки содержат данные за прошедший день, поскольку сама метка времени находится в сжатом столбце. Нужно ли распаковывать все данные в порции (или даже всю гипертаблицу), чтобы определить, какие строки соответствуют последнему дню? Точно так же пользовательские запросы обычно могут фильтроваться или группироваться по определенному устройству (например,
Нужно ли распаковывать все данные в порции (или даже всю гипертаблицу), чтобы определить, какие строки соответствуют последнему дню? Точно так же пользовательские запросы обычно могут фильтроваться или группироваться по определенному устройству (например, ВЫБЕРИТЕ температуру… ГДЕ device_id = ‘A’ ).
Распаковка всех данных будет очень неэффективной. Но поскольку мы оптимизируем эту таблицу для запросов временных рядов, мы можем сделать больше и автоматически включать больше информации в эту строку для повышения производительности запросов.
TimescaleDB делает это, автоматически создавая подсказки данных и включая дополнительные группы при преобразовании данных в этот формат столбцов. При сжатии несжатой гипертаблицы (либо с помощью специальной команды, либо с помощью асинхронной политики) пользователь указывает столбцы «упорядочить по» и, при необходимости, «сегментировать по» столбцам. Столбцы ORDER BY определяют, как упорядочены строки, являющиеся частью сжатого исправления. Как правило, это временная метка, как в нашем рабочем примере, хотя она также может быть составной, например, ORDER BY time, then location.
Как правило, это временная метка, как в нашем рабочем примере, хотя она также может быть составной, например, ORDER BY time, then location.
Для каждого столбца «ORDER BY» TimescaleDB автоматически создает дополнительные столбцы, в которых хранятся минимальное и максимальное значение этого столбца. Таким образом, планировщик запросов может просмотреть этот специальный столбец, указывающий диапазон меток времени в сжатом столбце, без предварительного выполнения какой-либо распаковки, чтобы определить, может ли строка соответствовать предикату времени, указанному в SQL-запросе пользователя. .
Мы также можем сегментировать сжатые строки по определенному столбцу, чтобы каждая сжатая строка соответствовала данным об одном элементе, например, определенному идентификатору устройства. В следующем примере TimescaleDB выполняет сегментацию по device_id, так что для устройств A и B существуют отдельные сжатые строки, и каждая сжатая строка содержит данные из 1000 несжатых строк об этом устройстве.
| Идентификатор устройства | Отметка времени | Код состояния | Температура | Мин. метка времени | Максимальная отметка времени |
| А | [12:00:01, 12:00:02, 12:00:03] | [0, 0, 0] | [70.11, 70.12, 70.14] | 12:00:01 | 12:00:03 |
| Б | [12:00:01, 12:00:02, 12:00:03] | [0, 0, 0] | [70.11, 70.12, 70.14] | 12:00:01 | 12:00:03 |
Теперь запрос для устройства ‘A’ между временным интервалом выполняется довольно быстро: планировщик запросов может использовать индекс для поиска тех строк для ‘A’, которые содержат хотя бы несколько меток времени, соответствующих указанному интервалу, и даже последовательное сканирование выполняется довольно быстро, так как оценка предикатов идентификаторов устройств или минимальных/максимальных временных меток не требует распаковки. Затем исполнитель запроса распаковывает только столбцы отметки времени и температуры, соответствующие этим выбранным строкам.
Затем исполнитель запроса распаковывает только столбцы отметки времени и температуры, соответствующие этим выбранным строкам.
Эта возможность поддерживается встроенной структурой планировщика заданий TimescaleDB. Ранее мы использовали его для различных задач управления жизненным циклом данных, таких как политики хранения данных, изменение порядка данных и непрерывное агрегирование. Теперь мы используем его для асинхронного преобразования последних данных из несжатой формы на основе строк в эту сжатую форму столбцов в фрагментах гипертаблиц TimescaleDB: как только фрагмент станет достаточно старым, фрагмент будет транзакционно преобразован из строки в форму столбца.
Производительность запросов
Краткий обзорВ этот момент можно было бы задать один логичный вопрос: «Как сжатие влияет на производительность запросов?»
Мы обнаружили, что сжатие также приводит к немедленному повышению производительности для многих типов запросов. Чем больше данных помещается в меньшее пространство, тем меньше страниц диска (со сжатыми данными) необходимо прочитать для ответа на запросы.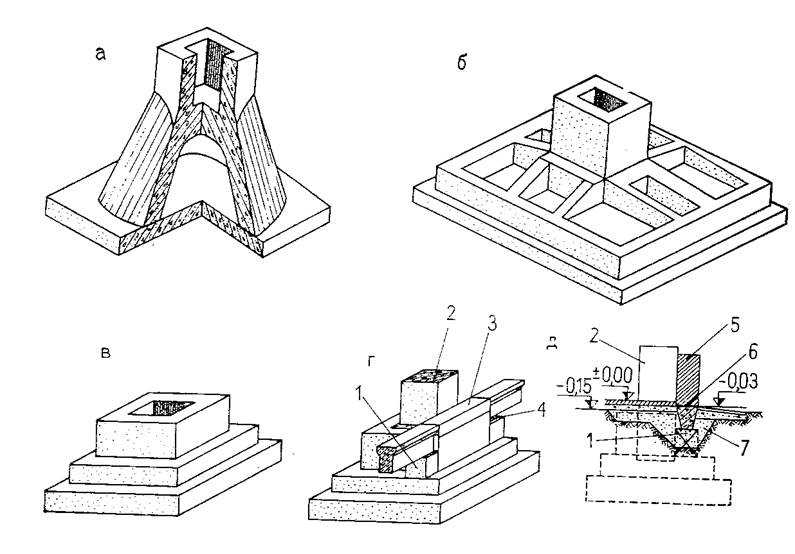
Учитывая длину этого поста, мы подробно рассмотрим производительность запросов в другом следующем посте в блоге, в том числе рассмотрим производительность для запросов, как при обращении к диску, так и при доступе к данным в памяти, а также для рабочих нагрузок DevOps и IoT.
А пока мы решили показать результаты.
Тесты производительности запросов
Мы используем набор тестов временных рядов с открытым исходным кодом (TSBS) с TimescaleDB, работающим на облачных виртуальных машинах с удаленным хранилищем SSD (в частности, типы инстансов Google Cloud n1-highmem-8 с 8 vCPU и 52 ГБ памяти с использованием как локальный твердотельный накопитель NVMe, так и удаленный жесткий диск).
В этом наборе запросов мы уделяем особое внимание производительности, связанной с диском, с которой часто приходится сталкиваться при выполнении специальных или рандомизированных запросов к большим наборам данных; в каком-то смысле эти результаты служат «худшим случаем» по сравнению с «теплыми» данными, которые, возможно, уже кэшированы в памяти. Для этого мы позаботились о том, чтобы все запросы выполнялись к данным, находящимся на диске, чтобы подсистема виртуальной памяти ОС еще не кэшировала дисковые страницы в память.
Для этого мы позаботились о том, чтобы все запросы выполнялись к данным, находящимся на диске, чтобы подсистема виртуальной памяти ОС еще не кэшировала дисковые страницы в память.
Как видно из приведенной ниже таблицы (в которой указано среднее значение 10 испытаний для двух экспериментальных установок, в одной из которых используется локальный SSD, а в другой — удаленный жесткий диск для хранения), практически все запросы TSBS выполняются быстрее при собственном сжатии.
| Типы запросов | ||||||
| Холодные запросы (от TSBS) | Несжатый (мс/запрос) | Сжатый (мс/запрос) | Соотношение | Несжатый (мс/запрос) | Сжатый (мс/запрос) | Соотношение |
| процессор-макс-все-1 | 42. 517 517 | 42.314 | 1,00 | 814.863 | 383,698 | 2,12 |
| процессор-макс-все-8 | 46.657 | 40.342 | 1,16 | 2987,42 | 1779.795 | 1,68 |
| группа по заказу по лимиту | 1373.309 | 6065.812 | 0,23 | 95202.022 | 6178.808 | 15.41 |
| высокопроизводительный процессор-1 | 46.657 | 40.342 | 1,16 | 1033.286 | 482.911 | 2,14 |
| высокопроизводительный процессор-все | 3551.953 | 8084.623 | 0,44 | 53995.25 | 8180.856 | 6,60 |
| одиночная группа по 1-1-12 | 49. 546 546 | 38,46 | 1,29 | 1058.517 | 293,941 | 3,60 |
| одиночная группа по 1-1-1 | 33,54 | 25.695 | 1,31 | 286.307 | 234.785 | 1,22 |
| одиночная группа по-1-8-1 | 50.805 | 40.495 | 1,25 | 995.306 | 598,26 | 1,66 |
| одиночная группа по 5-1-12 | 49.406 | 42.013 | 1,18 | 1083.432 | 432.758 | 2,50 |
| одиночная группа по 5-1-1 | 30.734 | 27.674 | 1.11 | 278.793 | 241 537 | 1,15 |
| одиночная группа по 5-8-1 | 45,91 | 43. 002 002 | 1,07 | 1000.578 | 627,39 | 1,59 |
| двойная группа-1 | 5925.591 | 1823.033 | 3,25 | 56676.155 | 1986.937 | 28,52 |
| двойная группа по 5 | 7568.038 | 2980.089 | 2,54 | 62681.04 | 2915.941 | 21.50 |
| двойная группа по всем | 9286.914 | 4399.367 | 2.11 | 65202.448 | 4257.638 | 15.31 |
| последняя точка | 1674,194 | 264,666 | 6,33 | 37998.325 | 539.368 | 70,45 |
В приведенной выше таблице указана задержка «холодных» запросов TSBS DevOps к TimescaleDB со всеми данными, находящимися на диске, как для несжатых, так и для сжатых данных.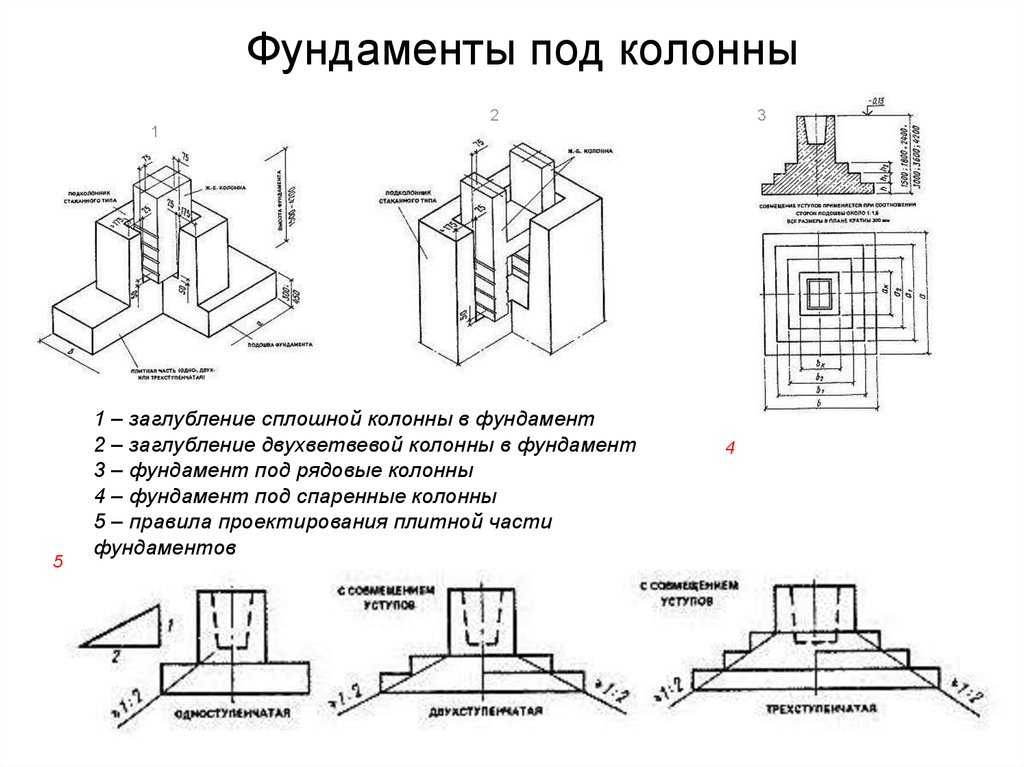 «Улучшение» определяется как «задержка несжатого запроса / задержка сжатого запроса».
«Улучшение» определяется как «задержка несжатого запроса / задержка сжатого запроса».
Тем не менее, можно создавать запросы, которые работают медленнее со сжатыми данными. В частности, сжатие TimescaleDB в настоящее время ограничивает типы индексов, которые можно построить на основе сжатых данных; в частности, b-деревья могут быть построены только на основе сегментированных столбцов. Но на практике мы обнаруживаем, что запросы, которые были бы быстрее с этими индексами, как правило, встречаются редко (например, они также требуют большого количества отдельных проиндексированных элементов, так что любой элемент отсутствует на большинстве страниц диска).
Ограничения и работа в будущем
Первоначальный выпуск встроенного сжатия TimescaleDB является довольно мощным, с пользовательскими расширенными алгоритмами сжатия для различных типов данных и обеспечивается нашей непрерывной асинхронной структурой планирования. Кроме того, у нас уже запланированы некоторые улучшения, например, улучшенное сжатие данных JSON.
Одно из основных ограничений нашего первоначального выпуска версии 1.5 заключается в том, что после преобразования фрагментов в форму сжатого столбца в настоящее время мы не разрешаем дальнейшие модификации данных (например, вставки, обновления, удаления) без ручной распаковки. Другими словами, куски неизменяемы в сжатой форме. Попытки изменить данные чанков либо завершатся ошибкой, либо пропадут молча (по желанию пользователя).
Тем не менее, учитывая, что рабочие нагрузки временных рядов в основном вставляют (или реже обновляют) последние данные, это гораздо меньшее ограничение для временных рядов, чем для варианта использования без временных рядов. Кроме того, пользователи могут настроить возраст фрагментов до того, как они будут преобразованы в эту сжатую столбчатую форму, что обеспечивает гибкость для умеренно неупорядоченных данных или во время запланированной обратной засыпки. Пользователи также могут явно распаковывать фрагменты перед их изменением. Мы также планируем ослабить/удалить это ограничение в будущих выпусках.
Резюме
Мы очень рады этой новой возможности и тому, как она обеспечит большую экономию средств, производительность запросов и масштабируемость хранилища для TimescaleDB и нашего сообщества.
Как мы упоминали выше, если вы заинтересованы в том, чтобы попробовать собственное сжатие сегодня, вы можете установить TimescaleDB или обновить текущую развертывание TimescaleDB. Если вы ищете полностью управляемый размещенный вариант, мы рекомендуем вам ознакомиться с управляемой службой для TimescaleDB (мы предлагаем бесплатную 30-дневную пробную версию). Вы также можете подписаться на наш предстоящий веб-семинар «Как снизить общую стоимость владения базой данных с помощью TimescaleDB», чтобы узнать больше.
За последние пару месяцев мы анонсировали как масштабируемую кластеризацию, так и собственное сжатие для TimescaleDB. В совокупности они помогают реализовать наше видение TimescaleDB как мощной, производительной и экономичной платформы для данных временных рядов, от малых до очень больших, от периферии до облака.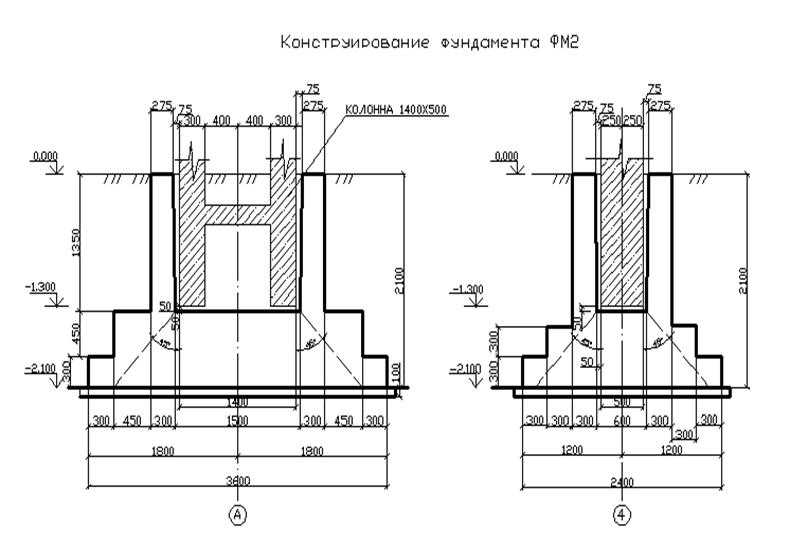
Мы все неоднократно слышали ошибочное представление о том, что для достижения необходимого масштаба, производительности и эффективности необходимо пожертвовать SQL, реляционными возможностями, гибкостью запросов и моделей данных, а также закаленной в боях надежностью и надежностью баз данных временных рядов. . Точно так же мы все слышали скептицизм в отношении PostgreSQL: хотя PostgreSQL является прекрасной и надежной базой данных, он не может работать с данными временных рядов.
С помощью TimescaleDB 1.5 мы продолжаем опровергать эти представления и демонстрируем, что благодаря целенаправленному подходу и разработке проблем с данными временных рядов не нужно идти на эти компромиссы.
Если у вас есть данные временных рядов, попробуйте последнюю версию TimescaleDB. Мы приветствуем ваши отзывы. И вместе давайте создадим единственную базу данных временных рядов, которая не заставит вас идти на трудные компромиссы. Давай, возьми свой торт и съешь его тоже.
Реляционная база данных с открытым исходным кодом для временных рядов и аналитики.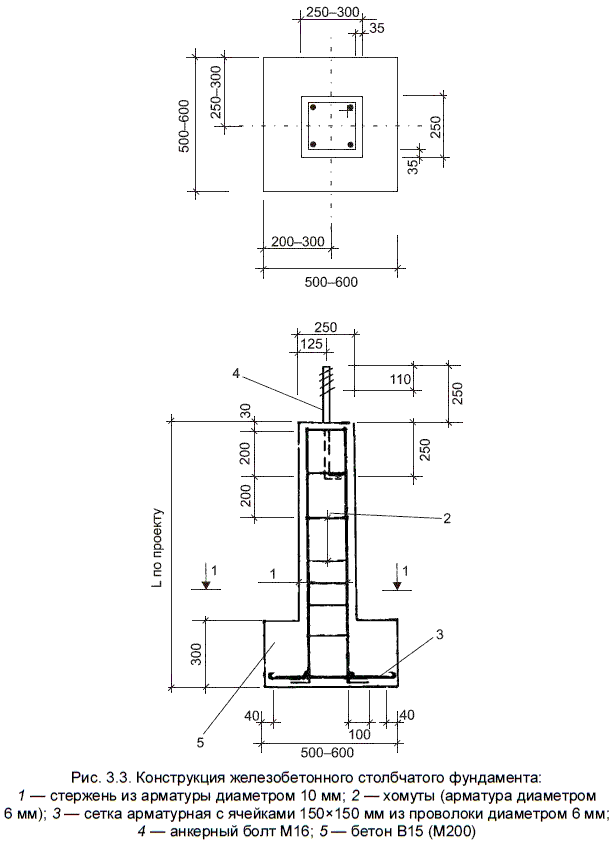
Патенты и патентные заявки США в области гидравлики и землеустройства (класс 405)
Перевозка, спуск на воду или удаление морских судов (класс 405/1)
- Рельсовый транспортер (класс 405/2)
- Подъем (Класс 405/3)
- Сухой док (Класс 405/4)
Герметичный кессон (Класс 405/8)
- Наличие подъемного троса (Класс 405/9)
- Подвижный относительно подвижной опоры (Класс 405/10)
Средства для обнажения обычно смачиваемой поверхности, например, коффердама и т. д. (класс 405/11)
д. (класс 405/11)
- Контур смачиваемой поверхности, например, кессон с боковой подвеской (Класс 405/12)
- Наличие средств транспортировки, размещения или перемещения (класс 405/13)
- Соединяемые секции (Класс 405/14)
Защита берега, берега или дна (класс 405/15)
- Облицовка (Класс 405/16)
- Рассеяние волны или потока (класс 405/21)
Дренаж или орошение (Класс 405/36)
- Контроль означает реакцию на обнаруженное состояние (класс 405/37).
- Включая подповерхностный гидроизоляционный слой (Класс 405/38)
- Наличие регулирования потока через канал (Класс 405/39)
- Заглушка (Класс 405/42)
- Пористая или перфорированная труба, желоб или плитка (класс 405/43)
- Пористый водный путь, например, канализация песка и т. д. (Класс 405/50)
- Разветвленный поток (Класс 405/51)

 д. (Класс 405/50)
д. (Класс 405/50)Контроль жидкости, обработка или локализация (класс 405/52)
- Хранение жидкости в земляной полости (Класс 405/53)
- Удержание плавучих веществ (класс 405/60)
- Эрозионная очистка (Класс 405/73)
- Осаждение взвешенных веществ в определенном месте (например, на промытом пирсе) (класс 405/74)
- Извлечение энергии из движущейся жидкости (класс 405/75)
- Генерация или усиление волн (класс 405/79)
- Управление потоком (класс 405/80)
Восстановление почвы (класс 405/128. 1)
1)
- Удаление или стабилизация загрязнения на месте (класс 405/128.15)
- С лечением (Класс 405/128.7)
Захоронение, локализация или обработка подземных отходов (класс 405/129)..1)
- Уплотнение (Класс 405/129.15)
- С обработкой отходов (Класс 405/129.2)
- Земляная формация (Класс 405/129. 35)
- Барьер для отходов, изоляция или мониторинг (класс 405/129.45)
- Свалка (Класс 405/129.95)
 35)
35)Модификация температуры или контроль земных пород (класс 405/130)
- Отопление (класс 405/131)
Подземный переход, например, туннель (класс 405/132)
- Вертикальный (Класс 405/133)
- Секционный (Класс 405/134)
- Подводный (класс 405/136)
- Скучно (класс 405/138)
- Вырезать и накрыть (Класс 405/149)
- Футеровка (Класс 405/150. 1)
 1)
1)Прокладка, извлечение, манипулирование или обработка подземных или подводных труб или кабелей (класс 405/154.1)
- Литье на месте (Класс 405/155)
- С формированием или разрезанием трубы или кабеля (Класс 405/156)
- С защитой или указанием трубы или траншеи (Класс 405/157)
- Погружение, подъем или манипулирование трубопроводом или кабелем в морской среде или из нее (класс 405/158)
- Путем продвижения по местности и направления трубы или кабеля в подземное положение (класс 405/174)
- Перемещение кабеля внутри трубы (класс 405/183. 5)
- Продвижение подземного отрезка трубы или кабеля (класс 405/184)
- Ремонт, замена или улучшение (класс 405/184.1)
- Поддержка, анкеровка или позиционирование трубы или кабеля (класс 405/184.4)
- Несколько секций труб (Класс 405/184.5)
Дайвинг (класс 405/185)
- Костюм или аксессуар к нему (класс 405/186)
- Подводный док или швартовка (класс 405/188)
- Дистанционное управление (Класс 405/190)
- С воздушным шлюзом (Класс 405/192)
- С выравниванием давления (Класс 405/193)
- С непрерывным доступом к поверхности (класс 405/194)
Морская конструкция или ее изготовление (класс 405/195. 1)
- С рабочей площадкой, регулируемой по вертикали относительно пола (класс 405/19).6)
- С горизонтально перемещаемой рабочей платформой (класс 405/201)
- С шарнирным соединением между рабочей площадкой и основанием (Класс 405/202)
- Плавающий на месте и поддерживаемый морским полом (класс 405/203)
- Контейнер для хранения (класс 405/210)
- Защита конструкции (Класс 405/211)
- В замороженных средах или на них (класс 405/217)
- Док (класс 405/218)
- Литье на месте (Класс 405/222)
- Платформа для натяжных ног (Класс 405/223. 1)
- С креплением конструкции к морскому дну (Класс 405/224)
Фонд (Класс 405/229)
- Фундамент (Класс 405/230)
- Столбчатая конструкция (например, пирс, свая) (класс 405/231)
Обработка или контроль земли (класс 405/258.1)
- Скальный или земляной болт или анкер (класс 405/259. 1)
- Химический (класс 405/263)
- Герметичность (Класс 405/270)
- Уплотнение (Класс 405/271)
- Укрепление, крепление или предотвращение обрушения (класс 405/272)
- Стабилизация или усиление грунта (класс 405/302.