Цсп расшифровка: ЦСП | это… Что такое ЦСП?
ЦСП | это… Что такое ЦСП?
ТолкованиеПеревод
- ЦСП
ЦСП
центр специальной подготовки
ЦСП
Центр социального партнёрства
общественная организация
http://csp.yaroslavl.ru/
г. Ярославль, организация
ЦСП
Центр стратегического планирования
Словарь: С. Фадеев. Словарь сокращений современного русского языка. — С.-Пб.: Политехника, 1997. — 527 с.
ЦСП
Центр содействия правосудию
ЦСП при фонде ИНДЕМ
Москва, юр.

Источник: http://dp.ru/main.php?page=48&id_article=105988
ЦСП
центральный сборный пункт
ЦСП
центр социальной помощи
ЦСП
цифровая система передач
ЦСП
Центральный стадион профсоюзов
г. Воронеж, организация
Центральный совет профсоюзов
Афганистан, организация
ЦСП
Центр содействия предпринимательству
ЦСП
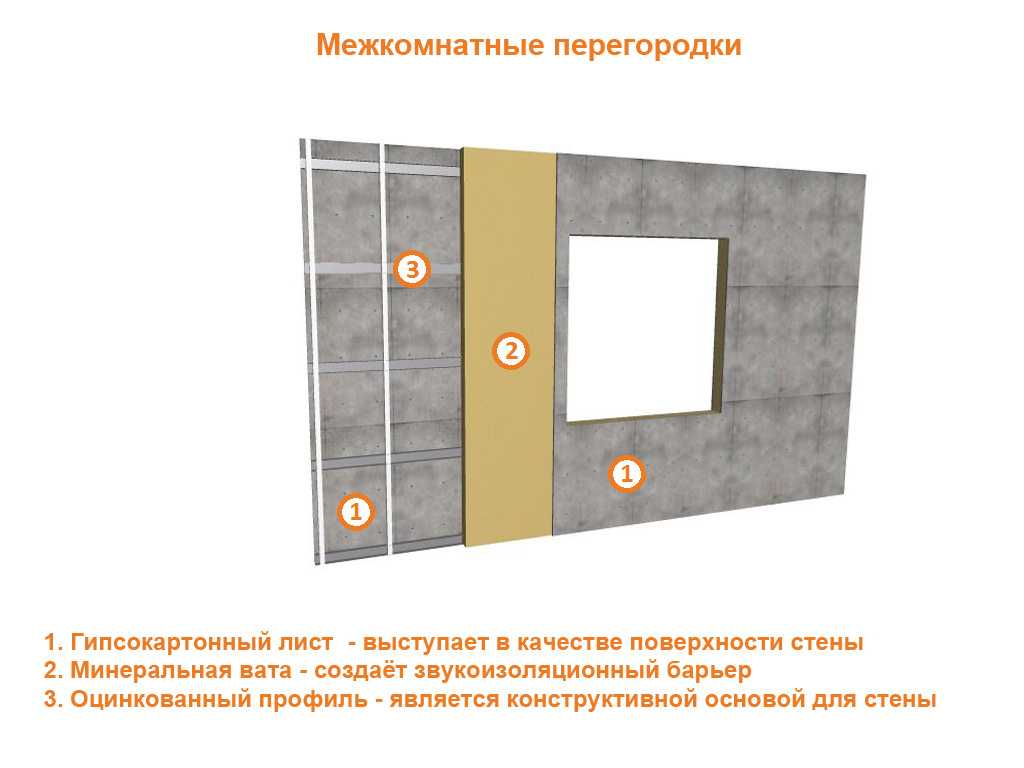
цементно-стружечная плита
ЦСП
централизованная система планирования
Словарь: С.
Фадеев. Словарь сокращений современного русского языка. — С.-Пб.: Политехника, 1997. — 527 с.ЦСП
центр социальной поддержки
организация
ЦСП
Центр строительного проектирования
название компаний
организация, строительство
Источник: http://c-s-proekt.ru/
ЦСП
Центр спортивной подготовки сборных команд России
организация, РФ, спорт
Источник: http://www.consultant.ru/online/base/?req=doc;base=EXP;n=483490
ЦСП
центральный совет партии
Источник: http://www.
rosbalt.ru/2008/04/25/478543.htmlЦСП
центр системного проектирования
Источник: http://www.gazetakoroleva.ru/index.php?arhivyear=2007&month=&number=2005131&st=66
ЦСП ЦНИИмаша
ЦСП
центр социальных программ
Источник: http://www.rusal.ru/about/social/charity/csp/
Пример использования
фонд «ЦСП» РУСАЛа
ЦСП
Центр спортивной подготовки сборных команд
спорт
Источник: http://www.rian.ru/sport/20050811/41139615.html
ЦСП
цифровой сигнальный процессор

 Фадеев. Словарь сокращений современного русского языка. — С.-Пб.: Политехника, 1997. — 527 с.
Фадеев. Словарь сокращений современного русского языка. — С.-Пб.: Политехника, 1997. — 527 с. rosbalt.ru/2008/04/25/478543.html
rosbalt.ru/2008/04/25/478543.html selsoft.ru/page/sprav_sokr.htm
selsoft.ru/page/sprav_sokr.htmСловарь сокращений и аббревиатур. Академик. 2015.
Игры ⚽ Поможем решить контрольную работу
- ШОУ
- ОО БГО
Полезное
Об организации — ФГБУ «ЦСП» ФМБА России
Федеральное государственное бюджетное учреждение «Центр стратегического планирования и управления медико-биологическими рисками здоровью» Федерального медико-биологического агентства (далее — Учреждение) является федеральным государственным бюджетным учреждением науки (Распоряжение Правительства Российской Федерации от 28 марта 2020 г. № 771-р).
Учреждение, ранее именуемое как федеральное государственное бюджетное учреждение «Научно-исследовательский институт экологии человека и гигиены окружающей среды им. А.Н. Сысина» Министерства здравоохранения Российской Федерации, было образовано постановлением Совнаркома РСФСР от 29.10.1931 № 1135 как Центральный институт коммунальной санитарии и гигиены Наркомздрава СССР.
Приказом Наркомздрава СССР от 25.08.1944 № 560 на базе Центрального института коммунальной санитарии и гигиены Наркомздрава СССР организован Институт общей и коммунальной гигиены Академии медицинских наук, который в соответствии с постановлением Совнаркома СССР от 30.06.1944 № 797 был включен в состав Академии медицинских наук СССР.
Указом Президиума Верховного Совета СССР от 12.06.1957 Учреждению было присвоено имя А.Н. Сысина.
В соответствии с Указом Президента Российской Федерации от 04.01.1992 № 5 «О преобразовании Академии медицинских наук СССР в Российскую академию медицинских наук» и приказом Российской академии медицинских наук от 23.03.1992 № 18 Учреждение включено в перечень учреждений, организаций и предприятий, находящихся в подчинении Российской академии медицинских наук, как Научно-исследовательский институт общей и коммунальной гигиены имени А.Н. Сысина.
В соответствии с приказом РАМН от 28.05.1992 № 34 Научно-исследовательский институт общей и коммунальной гигиены имени А. Н. Сысина переименован в Научно- исследовательский институт экологии человека и гигиены окружающей среды им. А.Н. Сысина Российской академии медицинских наук.
Н. Сысина переименован в Научно- исследовательский институт экологии человека и гигиены окружающей среды им. А.Н. Сысина Российской академии медицинских наук.
В соответствии с постановлением Президиума Российской академии медицинских наук от 03.10.2001 № 292 Научно-исследовательский институт экологии человека и гигиены окружающей среды им. А.Н. Сысина Российской академии медицинских наук переименован в Государственное учреждение Научно-исследовательский институт экологии человека и гигиены окружающей среды им. А.Н. Сысина Российской академии медицинских наук.
В соответствии с постановлением Президиума Российской академии медицинских наук от 25.06.2008 № 147 Государственное учреждение Научно-исследовательский институт экологии человека и гигиены окружающей среды им. А.Н. Сысина Российской академии медицинских наук переименован в Учреждение Российской академии медицинских наук Научно-исследовательский институт экологии человека и гигиены окружающей среды им. А.Н. Сысина РАМН.
В соответствии с распоряжением Правительства Российской Федерации от 02. 09.2010 № 1441-р Учреждение передано в ведение Министерства здравоохранения и социального развития Российской Федерации.
09.2010 № 1441-р Учреждение передано в ведение Министерства здравоохранения и социального развития Российской Федерации.
Распоряжением Правительства Российской Федерации от 19.07.2012 № 1286-р Учреждение отнесено к ведению Министерства здравоохранения Российской Федерации.
Приказом Министерства здравоохранения Российской Федерации от 05.04.2017 № 157 Учреждение переименовано в федеральное государственное бюджетное учреждение «Центр стратегического планирования и управления медико-биологическими рисками здоровью» Министерства здравоохранения Российской Федерации.
CSP и процесс шифрования — приложения Win32
Редактировать
Твиттер LinkedIn Фейсбук Электронная почта
- Статья
- 2 минуты на чтение
Функции CryptoAPI используют поставщиков криптографических услуг (CSP) для выполнения шифрования и дешифрования, а также для хранения ключей и обеспечения безопасности. Эти CSP являются независимыми модулями. В идеале CSP должны быть независимыми от конкретного приложения, чтобы любое приложение могло работать с различными CSP. Однако в действительности некоторые приложения предъявляют особые требования, требующие индивидуального CSP. Это по сравнению с Windows
Качество защиты ключей в системе является конструктивным параметром CSP, а не системы в целом. Это позволяет приложению работать в различных контекстах безопасности без изменений.
Доступ приложений к внутренним криптографическим компонентам строго ограничен. Это облегчает разработку безопасных и переносимых приложений.
Применяются следующие три правила проектирования:
- Приложения не могут получить прямой доступ к ключевому материалу.
- Приложения не могут указывать детали криптографических операций. Интерфейс CSP позволяет приложению выбирать алгоритм шифрования или подписи, но реализация каждой криптографической операции выполняется CSP.
- Приложения не обрабатывают учетные данные пользователя или другие данные аутентификации пользователя. Аутентификация пользователя выполняется CSP; поэтому будущие CSP с расширенными возможностями аутентификации, такими как ввод биометрических данных, будут функционировать без необходимости изменения модели аутентификации приложений.
Как минимум CSP состоит из библиотеки динамической компоновки (DLL) и файла подписи . Файл подписи необходим для обеспечения того, чтобы CryptoAPI распознает CSP. CryptoAPI периодически проверяет эту подпись, чтобы гарантировать обнаружение любого вмешательства в CSP.
CryptoAPI периодически проверяет эту подпись, чтобы гарантировать обнаружение любого вмешательства в CSP.
Некоторые CSP могут реализовать часть своих функций в службе с разделением адресов, вызываемой через локальный RPC, или в оборудовании, вызываемом через драйвер системного устройства. Изоляция глобальных операций с состоянием ключей и центральных криптографических операций в службе с разделением адресов или в оборудовании защищает ключи и операции от подделки в пространстве данных приложения.
Для приложений неразумно использовать атрибуты, характерные для конкретного CSP. Например, Microsoft Base Cryptographic Provider (поставляется с CryptoAPI) поддерживает 40-битные сеансовые ключи и 512-битные открытые ключи. Приложения, манипулирующие этими ключами, должны избегать предположений об объеме памяти, необходимом для хранения этих ключей, поскольку при использовании другого CSP приложение может выйти из строя. Хорошо написанные приложения должны работать с различными CSP.
Дополнительные сведения о типах провайдеров криптографии и предопределенных CSP, которые можно использовать с CryptoAPI, см. в разделе Типы провайдеров криптографии и поставщики служб криптографии Майкрософт.
Лабораторная работа 4-2: Шифр Цезаря — Шифрование и дешифрование — CSP Python
Примечание. Часть этой лабораторной работы взята из замечательной книги Эла Свейгарта « Взлом секретных шифров с помощью Python: руководство для начинающих по криптографии и компьютерному программированию с помощью Python », доступна онлайн здесь, в Invent With Python, среди других его работ. Не стесняйтесь проверить их, если они вас интересуют!
Шифр Цезаря
Шифр Цезаря, названный в честь Юлия Цезаря из Древнего Рима, представляет собой тип шифра замены, в котором каждая буква исходного (незашифрованного) сообщения заменяется другой буквой.
Шифрование с помощью шифра Цезаря
Но как решить, какая буква чем заменяется? Вот где в игру вступает ключ . Присутствующий почти в каждом алгоритме шифрования ключ определяет способ шифрования данных .
Присутствующий почти в каждом алгоритме шифрования ключ определяет способ шифрования данных .
В шифре Цезаря ключом является число от 0 до 25, потому что в алфавите 26 букв. Это означает, что для любого данного сообщения существует 26 различных способов, которыми мы можем зашифровать сообщение.
Для каждой буквы ключ определяет , какая буква заменяет текущую букву, путем обратного отсчета алфавита . В следующем примере, допустим, мы хотим зашифровать букву B с помощью ключа 3 , мы найдем 3-ю букву, которая появляется после B , то есть C, D, затем, наконец, E .
В шифре Цезаря с ключом 3 A становится D, B становится E, C становится F и так далее…
Это легко показать, выстроив два алфавита, по одному на каждом другой, со вторым алфавитом, начинающимся с буквы, сдвинутой на 3 буквы вниз. Это означает, что нижний ряд должен быть сдвинут на осталось .
ABCDEFGHIJKLMNOPQRSTUVWXYZ DEFGHIJKLMNOPQRSTUVWXYZABC
Вы могли заметить, что вторая строка начинается с букв ABC сразу после Z . Это потому, что когда вы перемещаетесь вниз по алфавиту, если вы дойдете до конца (Z), он вернется к началу (A).
Этот тип изображения делает более ясным, какая буква должна стать какой. Если бы мы хотели зашифровать слово БИЛЛИ , мы бы просто взяли каждую уникальная буква открытого текста (верхняя строка) и найти соответствующую ей букву зашифрованного текста (нижняя строка), или:
A [B] CDEFGH [I] JK [L] MNOPQRSTUVWX [Y] Z D [E] FGHIJK [L] MN [O] PQRSTUVWXYZA [B] C
Итак, мы ясно видим, что:
BстановитсяEIстановитсяLLстановитсяOYстановитсяB
(Обратите внимание, что нам нужно найти только уникальные буквы, например L , потому что каждый L всегда будет превращаться в одну и ту же букву)
Таким образом, окончательный зашифрованный текст будет ELOOB . Обратите внимание, что когда мы доходим до конца алфавита, мы продолжаем считать, начиная с A, B и т. д.
Обратите внимание, что когда мы доходим до конца алфавита, мы продолжаем считать, начиная с A, B и т. д.
Расшифровка с помощью шифра Цезаря
Расшифровка работает очень похожим образом, за исключением того, что на этот раз вместо обратного отсчета алфавит, ты считаешь «вверх»! В качестве примера попробуем расшифровать ELOOB с использованием ключа 3 , потому что мы знаем, что результатом должен быть наш исходный открытый текст, BILLY . Начнем с выравнивания наших алфавитов:
ABCDEFGHIJKLMNOPQRSTUVWXYZ. XYZABCDEFGHIJKLMNOPQRSTUVW
Обратите внимание, что на этот раз вместо того, чтобы сместить нижний ряд влево, мы смещаем его вправо . Затем мы можем найти наши буквы зашифрованного текста (верхний ряд) E, L, O, B и найти соответствующие им буквы открытого текста (нижний ряд).
A [B] CD [E] FGHIJK [L] MN [O] PQRSTUVWXYZ X [Y] ZA [B] CDEFGH [I] JK [L] MNOPQRSTUVW
Теперь мы можем видеть, что:
EстановитсяBLстановитсяIOстановитсяLBстановитсяY
Что дает нам исходный открытый текст БИЛЛИ .
Далее мы собираемся узнать о реализации шифра Цезаря на Python.
Пошаговое руководство по шифрованию
Для начала создайте файл с именем FILN_caesar.py , где FILN — ваши имя и фамилия, без пробела.
Эта лаборатория будет работать немного иначе, чем предыдущие. Цель этого лабораторного занятия — объяснить алгоритм, провести вас через алгоритм, а также выделить мыслительные процессы, лежащие в основе хорошего дизайна кода. Пожалуйста, обратите особое внимание и прочтите весь текст, так как он предлагает некоторые стратегии и понимание того, как вы можете писать код.
В этой лабораторной работе вы должны следовать и шаг за шагом создавать это в предпочитаемой вами среде IDE Python. Измененные строки в коде будут выделены.
Давайте начнем с нашей функции шифрования. В этой функции мы будем принимать ключ и сообщение в качестве аргументов. Первое, что я собираюсь сделать, это преобразовать все сообщение в верхний регистр, что мы можем сделать с помощью строкового метода .. Затем я собираюсь создать переменную с именем  upper()
upper() alpha , который будет содержать алфавит в виде длинной строки
def encrypt(key, message):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
|
Далее я знаю, что мне придется работать с каждой буквой в сообщении. Я могу написать цикл для , который будет перебирать каждую букву в строке, используя для var в str , где var будет циклически проходить каждый символ в стр . Я также знаю, что, поскольку я просматриваю букву за буквой, мне нужно будет инициализировать пустую строку в качестве результата, чтобы я мог опираться на нее.
1 2 3 4 5 6 | def encrypt(ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
|
Следует отметить, что шифр Цезаря не обрабатывает символы, не являющиеся буквами, такие как знаки препинания или пробелы. Итак, мы хотим убедиться, что если мы собираемся что-то зашифровать, мы будем шифровать только буквы.
Итак, мы хотим убедиться, что если мы собираемся что-то зашифровать, мы будем шифровать только буквы.
Давайте добавим условие, чтобы справиться с этим. Логика здесь такова: «если это письмо, зашифруйте его. в противном случае просто добавьте его к результату (т.е. не изменяйте его)». Мы можем проверить, находится ли буква var в строке str , используя var in str , которая возвращает True , если var найдена в str .
1 2 3 4 5 6 7 8 9 10 | def encrypt(ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
если буква в альфе: #если буква на самом деле буква
# зашифровать это
еще:
результат = результат + буква
|
Теперь мы приступим к шифрованию. Это происходит побуквенно, так как мы используем цикл for для повторения сообщения, что делает его проще для нас. Первое, что мы хотим сделать, это выяснить где буква в алфавите? В каком индексе буква? Для этого мы можем использовать строковый метод
Первое, что мы хотим сделать, это выяснить где буква в алфавите? В каком индексе буква? Для этого мы можем использовать строковый метод .find() , который даст нам первое вхождение буквы.
1 2 3 4 5 6 7 8 9 10 11 | def encrypt(ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
если буква в альфе: #если буква на самом деле буква
#найди букву в алфавите
letter_index = alpha.find(буква)
еще:
результат = результат + буква
|
Теперь, когда мы знаем буквенный индекс открытого текста… мы должны найти соответствующую букву зашифрованного текста! Хотя технически мы могли бы создать новую строку алфавита, которая была сдвинута, было бы намного проще вычислить новый буквенный индекс, используя ключ . Мы можем «сдвинуть» алфавит влево, добавив значение ключа к индексу. В нашем старом примере, где мы превратили
Мы можем «сдвинуть» алфавит влево, добавив значение ключа к индексу. В нашем старом примере, где мы превратили B в E с ключом 3 , вы можете видеть здесь, что индекс B — это 1 , а индекс E — это 4 , так что действительно, +3 — это операция. В общем, это просто + ключ .
1 2 3 4 5 6 7 8 9 10 11 | def encrypt(ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
если буква в альфе: #если буква на самом деле буква
# найти соответствующую букву зашифрованного текста в алфавите
letter_index = alpha.find(буква) + ключ
еще:
результат = результат + буква
|
Теперь, когда у нас есть индекс буквы зашифрованного текста, нам просто нужно добавить эту букву к результату. Прямо сейчас
Прямо сейчас letter_index представляет позицию буквы в алфавите. Мы хотим получить само письмо. Мы делаем это, просто используя letter_index в качестве индекса строки alpha[letter_index] . Затем мы добавляем это к результату.
1 2 3 4 5 6 7 8 910 11 12 13 | def encrypt(ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
если буква в альфе: #если буква на самом деле буква
# найти соответствующую букву зашифрованного текста в алфавите
letter_index = alpha.find(буква) + ключ
результат = результат + альфа[буквенный_индекс]
еще:
результат = результат + буква
|
Однако мы забыли одну вещь. Мы забыли обработать циклы! Как мы справимся с тем, что произойдет, когда мы дойдем до конца алфавита? Ну, всякий раз, когда мы достигаем индекса 26, мы хотим, чтобы этот индекс стал равным нулю (тем более, что альфа не имеет 26-го индекса!). Если наш индекс становится равным 28, мы хотим, чтобы наш индекс на самом деле был равен 2. Последовательность здесь заключается в том, что , если наш индекс равен 26 или больше, мы хотим вычесть 26. Хотя мы могли бы использовать для этого оператор if, существует лучший способ.
Если наш индекс становится равным 28, мы хотим, чтобы наш индекс на самом деле был равен 2. Последовательность здесь заключается в том, что , если наш индекс равен 26 или больше, мы хотим вычесть 26. Хотя мы могли бы использовать для этого оператор if, существует лучший способ.
Это яркий пример того, где модуль по модулю может быть полезен. Мы можем использовать модуль для обработки циклов. Это работает, потому что любое число больше 26 будет уменьшено до числа от 0 до 25, так как остаток от деления на 26 может быть только от 0 до 25.
Мы можем убедиться, что это работает для обхода петли, наблюдая за следующим поведением:
- \(25 \% 26 = (0*26 + 25) \% 26 = 25\)
- \(26 \% 26 = (1*26 + 0) \% 26 = 0\)
- \(27 \% 26 = (1*26 + 1) \% 26 = 1\)
- \(28 \% 26 = (1*26 + 2) \% 26 = 2\)
- и так далее…
Затем мы можем просто использовать следующую строку для обработки цикла:
letter_index = (alpha.
 find(letter) + key) % 26
find(letter) + key) % 26
Однако при программировании рекомендуется избегать жесткого кодирования чисел, если это возможно. Мы работаем с числом 26, потому что в алфавите 26 букв, а также потому, что альфа имеет длину 26 ( len(alpha) == 26 ). Вместо 26 в нашем алгоритме мы должны использовать len(alpha) .
1 2 3 4 5 6 7 8 9 10 11 12 13 | def encrypt(ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
если буква в альфе: #если буква на самом деле буква
# найти соответствующую букву зашифрованного текста в алфавите
letter_index = (alpha.find(letter) + key) % len(alpha)
результат = результат + альфа[буквенный_индекс]
еще:
результат = результат + буква
|
Наконец, то, что мы написали, будет повторяться для каждого символа в сообщении. Вернем нашу последнюю строку.
Вернем нашу последнюю строку.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | def encrypt(ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
если буква в альфе: #если буква на самом деле буква
# найти соответствующую букву зашифрованного текста в алфавите
letter_index = (alpha.find(letter) + key) % len(alpha)
результат = результат + альфа[буквенный_индекс]
еще:
результат = результат + буква
вернуть результат
|
Пошаговое руководство по расшифровке
Опять же, это очень похоже на нашу функцию шифрования, поэтому давайте перепишем нашу функцию шифрования и назовем ее «расшифровать».
Когда вы переписываете функцию, помните, что мы меняем:
- Вместо
+ клавишамы хотим сдвинуться в другую сторону, используя вместо- клавишу.

Тогда наша окончательная программа:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | def encrypt(ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
если буква в альфе: #если буква на самом деле буква
# найти соответствующую букву зашифрованного текста в алфавите
letter_index = (alpha.find(letter) + key) % len(alpha)
результат = результат + альфа[буквенный_индекс]
еще:
результат = результат + буква
вернуть результат
def расшифровать (ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
если буква в альфе: #если буква на самом деле буква
# найти соответствующую букву зашифрованного текста в алфавите
letter_index = (alpha. |
 find(letter) - key) % len(alpha)
результат = результат + альфа[буквенный_индекс]
еще:
результат = результат + буква
вернуть результат
find(letter) - key) % len(alpha)
результат = результат + альфа[буквенный_индекс]
еще:
результат = результат + буква
вернуть результат
Тестирование нашей программы
Наконец, мы можем протестировать нашу программу. Давайте напишем скрипт для проверки нашего кода. Следующий код должен быть добавлен к и вашей программы выше.
по умолчанию main():
слово = "БИЛЛИ"
# зашифровать "БИЛЛИ" ключом 3
зашифровано = зашифровано (3, слово)
print(encrypted) #должен печатать "ELOOB"
# расшифровать "ELOOB" с ключом 3
расшифровано = расшифровано (3, зашифровано)
print(decrypted) #должен печатать "БИЛЛИ"
если __name__ == "__main__":
основной()
Запустите программу и сравните ее вывод с тем, что должно быть (она должна напечатать ELOOB , затем снова BILLY ). Если получится, то отлично! Мы должны проверить это еще раз, но на этот раз с фразой/словом с небуквенными символами:
def main():
слово = "ПРИВЕТ, МИР?!"
#encrypt "ПРИВЕТ, МИР?!" с ключом на 20
зашифровано = зашифровано (20, слово)
print(encrypted) #должен печатать "BYFFI QILFX?!"
#decrypt "BYFFI QILFX?!" с ключом на 20
расшифровано = расшифровано (20, зашифровано)
print(decrypted) #должен печатать "HELLO WORLD?!"
если __name__ == "__main__":
основной
Когда мы запускаем эту программу, мы должны заметить, что когда она печатает форму зашифрованного текста, пробел, знак вопроса и восклицательный знак остаются на одном месте. Хороший знак!
Хороший знак!
Рефакторинг нашего кода
Согласно Википедии, рефакторинг кода — это процесс реструктуризации существующего компьютерного кода без изменения его внешнего поведения. Это очень важный процесс для изучения, потому что он облегчает поддержку нашего кода, как вы скоро увидите.
- На данный момент в нашем коде есть два основных недостатка:
- Наш код часто повторяется.
- Наш алгоритм можно разбить на более специализированные функции
Глядя на наше окончательное решение, мы можем заметить, что циклы for в encrypt() и decrypt() почти идентичны, за исключением того, что один добавляет ключ, а другой вычитает ключ (#1). Мы также замечаем, что наш процесс шифрования/дешифрования целого слова может быть далее разбит на шифрование/дешифрование отдельных букв (как мы делаем в нашем для петли ) (#2). Эти два недостатка можно исправить, просто создав новую функцию.
Давайте создадим новую функцию get_cipherletter() .
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | def get_cipherletter (новый_ключ, буква):
def encrypt(ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
если буква в альфе: #если буква на самом деле буква
# найти соответствующую букву зашифрованного текста в алфавите
letter_index = (alpha.find(letter) + key) % len(alpha)
результат = результат + альфа[буквенный_индекс]
еще:
результат = результат +
вернуть результат
def расшифровать (ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
если буква в альфе: #если буква на самом деле буква
# найти соответствующую букву зашифрованного текста в алфавите
letter_index = (alpha. |
 find(letter) - key) % len(alpha)
результат = результат + альфа[буквенный_индекс]
еще:
результат = результат + буква
вернуть результат
find(letter) - key) % len(alpha)
результат = результат + альфа[буквенный_индекс]
еще:
результат = результат + буква
вернуть результат
Целью этой функции будет просто вернуть новую букву для нового ключа. Мы можем извлечь код из нашей существующей программы, чтобы помочь нам построить это:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 3940 | def get_cipherletter (новый_ключ, буква):
#все еще нужна альфа для поиска букв
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
если буква в альфе:
вернуть альфа[новый_ключ]
еще:
ответное письмо
def encrypt(ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
если буква в альфе: #если буква на самом деле буква
# найти соответствующую букву зашифрованного текста в алфавите
letter_index = (alpha. |
 find(letter) + key) % len(alpha)
результат = результат + альфа[буквенный_индекс]
еще:
результат = результат + буква
вернуть результат
def расшифровать (ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
если буква в альфе: #если буква на самом деле буква
# найти соответствующую букву зашифрованного текста в алфавите
letter_index = (alpha.find(letter) - key) % len(alpha)
результат = результат + альфа[буквенный_индекс]
еще:
результат = результат + буква
вернуть результат
find(letter) + key) % len(alpha)
результат = результат + альфа[буквенный_индекс]
еще:
результат = результат + буква
вернуть результат
def расшифровать (ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
если буква в альфе: #если буква на самом деле буква
# найти соответствующую букву зашифрованного текста в алфавите
letter_index = (alpha.find(letter) - key) % len(alpha)
результат = результат + альфа[буквенный_индекс]
еще:
результат = результат + буква
вернуть результат
Затем мы удаляем биты кода из наших функций encrypt и decrypt , которые теперь являются избыточными, и заменяем их кодом, который использует эту функцию:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | по определению get_cipherletter (новый_ключ, буква):
#все еще нужна альфа для поиска букв
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
если буква в альфе:
вернуть альфа[новый_ключ]
еще:
ответное письмо
def encrypt(ключ, сообщение):
сообщение = сообщение. |
 upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
new_key = (alpha.find(буква) + ключ) % len(альфа)
результат = результат + get_cipherletter (новый_ключ, буква)
вернуть результат
def расшифровать (ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
new_key = (alpha.find(letter) - key) % len(alpha)
результат = результат + get_cipherletter (новый_ключ, буква)
вернуть результат
upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
new_key = (alpha.find(буква) + ключ) % len(альфа)
результат = результат + get_cipherletter (новый_ключ, буква)
вернуть результат
def расшифровать (ключ, сообщение):
сообщение = сообщение.upper()
альфа = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
результат = ""
для письма в сообщении:
new_key = (alpha.find(letter) - key) % len(alpha)
результат = результат + get_cipherletter (новый_ключ, буква)
вернуть результат
«Но подождите!» — вы могли бы сказать — «А что, если у нас есть символ? Он не будет найден в alpha , когда мы используем alpha.find() !»
И вы правы! И это нормально. Функция .find() возвращает -1 , что по-прежнему является действительным числом, и проверка того, существует ли буква в alpha или нет, все равно будет происходить внутри функции.